 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCAtion: Long-time Collaborative Attention Framework for High Dynamic Range Video Reconstruction
Mar 15, 2026Prevailing High Dynamic Range (HDR) video reconstruction methods are fundamentally trapped in a fragile alignment-and-fusion paradigm. While explicit spatial alignment can successfully recover fine details in controlled environments, it becomes a severe bottleneck in unconstrained dynamic scenes. By forcing rigid alignment across unpredictable motions and varying exposures, these methods inevitably translate registration errors into severe ghosting artifacts and temporal flickering. In this paper, we rethink this conventional prerequisite. Recognizing that explicit alignment is inherently vulnerable to real-world complexities, we propose LoCAtion, a Long-time Collaborative Attention framework that reformulates HDR video generation from a fragile spatial warping task into a robust, alignment-free collaborative feature routing problem. Guided by this new formulation, our architecture explicitly decouples the highly entangled reconstruction task. Rather than struggling to rigidly warp neighboring frames, we anchor the scene on a continuous medium-exposure backbone and utilize collaborative attention to dynamically harvest and inject reliable irradiance cues from unaligned exposures. Furthermore, we introduce a learned global sequence solver. By leveraging bidirectional context and long-range temporal modeling, it propagates corrective signals and structural features across the entire sequence, inherently enforcing whole-video coherence and eliminating jitter. Extensive experiments demonstrate that LoCAtion achieves state-of-the-art visual quality and temporal stability, offering a highly competitive balance between accuracy and computational efficiency.
Capturing Stable HDR Videos Using a Dual-Camera System
Jul 09, 2025In HDR video reconstruction, exposure fluctuations in reference images from alternating exposure methods often result in flickering. To address this issue, we propose a dual-camera system (DCS) for HDR video acquisition, where one camera is assigned to capture consistent reference sequences, while the other is assigned to capture non-reference sequences for information supplementation. To tackle the challenges posed by video data, we introduce an exposure-adaptive fusion network (EAFNet) to achieve more robust results. EAFNet introduced a pre-alignment subnetwork to explore the influence of exposure, selectively emphasizing the valuable features across different exposure levels. Then, the enhanced features are fused by the asymmetric cross-feature fusion subnetwork, which explores reference-dominated attention maps to improve image fusion by aligning cross-scale features and performing cross-feature fusion. Finally, the reconstruction subnetwork adopts a DWT-based multiscale architecture to reduce ghosting artifacts and refine features at different resolutions. Extensive experimental evaluations demonstrate that the proposed method achieves state-of-the-art performance on different datasets, validating the great potential of the DCS in HDR video reconstruction. The codes and data captured by DCS will be available at https://github.com/zqqqyu/DCS.
Hierarchical Frequency-based Upsampling and Refining for Compressed Video Quality Enhancement
Mar 18, 2024



Video compression artifacts arise due to the quantization operation in the frequency domain. The goal of video quality enhancement is to reduce compression artifacts and reconstruct a visually-pleasant result. In this work, we propose a hierarchical frequency-based upsampling and refining neural network (HFUR) for compressed video quality enhancement. HFUR consists of two modules: implicit frequency upsampling module (ImpFreqUp) and hierarchical and iterative refinement module (HIR). ImpFreqUp exploits DCT-domain prior derived through implicit DCT transform, and accurately reconstructs the DCT-domain loss via a coarse-to-fine transfer. Consequently, HIR is introduced to facilitate cross-collaboration and information compensation between the scales, thus further refine the feature maps and promote the visual quality of the final output. We demonstrate the effectiveness of the proposed modules via ablation experiments and visualized results. Extensive experiments on public benchmarks show that HFUR achieves state-of-the-art performance for both constant bit rate and constant QP modes.
RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation
Jan 15, 2024



Large language models (LLMs) have demonstrated remarkable capabilities and have been extensively deployed across various domains, including recommender systems. Numerous studies have employed specialized \textit{prompts} to harness the in-context learning capabilities intrinsic to LLMs. For example, LLMs are prompted to act as zero-shot rankers for listwise ranking, evaluating candidate items generated by a retrieval model for recommendation. Recent research further uses instruction tuning techniques to align LLM with human preference for more promising recommendations. Despite its potential, current research overlooks the integration of multiple ranking tasks to enhance model performance. Moreover, the signal from the conventional recommendation model is not integrated into the LLM, limiting the current system performance. In this paper, we introduce RecRanker, tailored for instruction tuning LLM to serve as the \textbf{Ranker} for top-\textit{k} \textbf{Rec}ommendations. Specifically, we introduce importance-aware sampling, clustering-based sampling, and penalty for repetitive sampling for sampling high-quality, representative, and diverse training data. To enhance the prompt, we introduce position shifting strategy to mitigate position bias and augment the prompt with auxiliary information from conventional recommendation models, thereby enriching the contextual understanding of the LLM. Subsequently, we utilize the sampled data to assemble an instruction-tuning dataset with the augmented prompt comprising three distinct ranking tasks: pointwise, pairwise, and listwise rankings. We further propose a hybrid ranking method to enhance the model performance by ensembling these ranking tasks. Our empirical evaluations demonstrate the effectiveness of our proposed RecRanker in both direct and sequential recommendation scenarios.
Perceptual Generative Autoencoders
Jun 25, 2019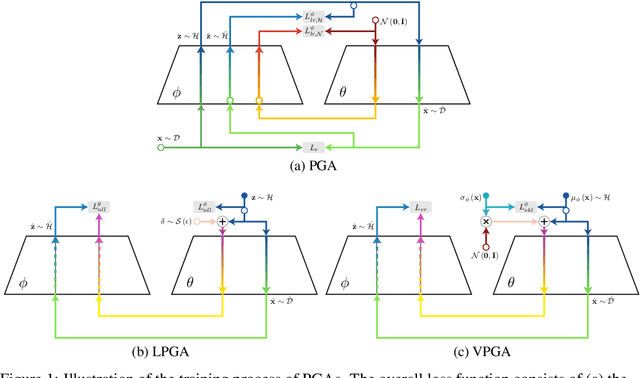
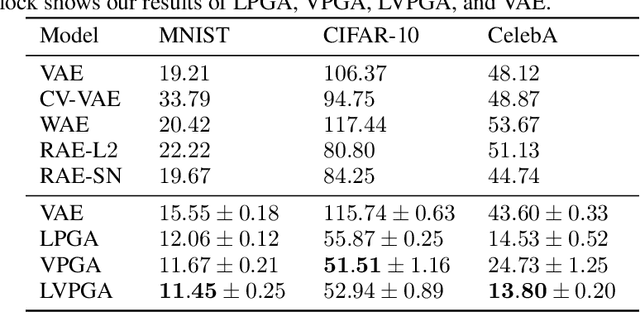


Modern generative models are usually designed to match target distributions directly in the data space, where the intrinsic dimensionality of data can be much lower than the ambient dimensionality. We argue that this discrepancy may contribute to the difficulties in training generative models. We therefore propose to map both the generated and target distributions to the latent space using the encoder of a standard autoencoder, and train the generator (or decoder) to match the target distribution in the latent space. The resulting method, perceptual generative autoencoder (PGA), is then incorporated with a maximum likelihood or variational autoencoder (VAE) objective to train the generative model. With maximum likelihood, PGAs generalize the idea of reversible generative models to unrestricted neural network architectures and arbitrary latent dimensionalities. When combined with VAEs, PGAs can generate sharper samples than vanilla VAEs. Compared to other autoencoder-based generative models using simple priors, PGAs achieve state-of-the-art FID scores on CIFAR-10 and CelebA.
Removing the Feature Correlation Effect of Multiplicative Noise
Sep 19, 2018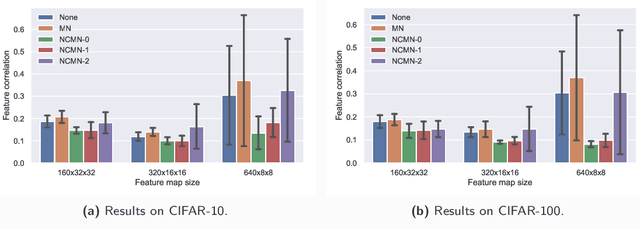
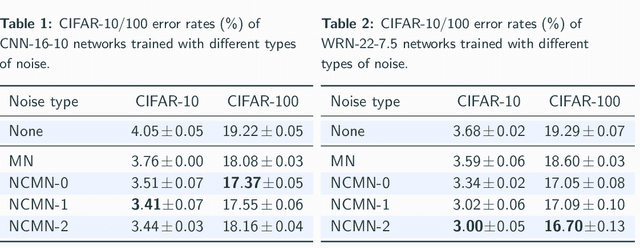
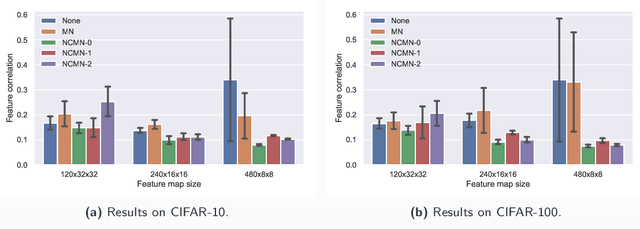
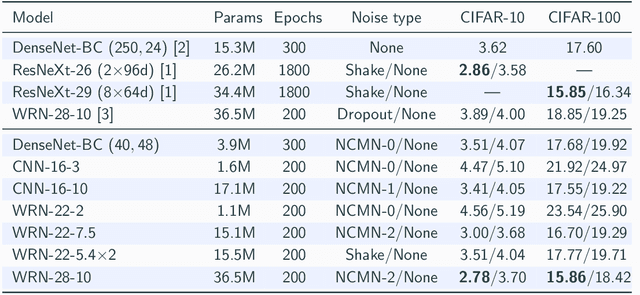
Multiplicative noise, including dropout, is widely used to regularize deep neural networks (DNNs), and is shown to be effective in a wide range of architectures and tasks. From an information perspective, we consider injecting multiplicative noise into a DNN as training the network to solve the task with noisy information pathways, which leads to the observation that multiplicative noise tends to increase the correlation between features, so as to increase the signal-to-noise ratio of information pathways. However, high feature correlation is undesirable, as it increases redundancy in representations. In this work, we propose non-correlating multiplicative noise (NCMN), which exploits batch normalization to remove the correlation effect in a simple yet effective way. We show that NCMN significantly improves the performance of standard multiplicative noise on image classification tasks, providing a better alternative to dropout for batch-normalized networks. Additionally, we present a unified view of NCMN and shake-shake regularization, which explains the performance gain of the latter.
Normalized Direction-preserving Adam
Sep 18, 2018

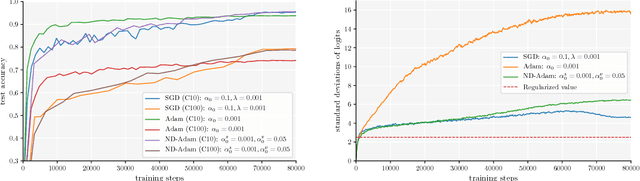
Adaptive optimization algorithms, such as Adam and RMSprop, have shown better optimization performance than stochastic gradient descent (SGD) in some scenarios. However, recent studies show that they often lead to worse generalization performance than SGD, especially for training deep neural networks (DNNs). In this work, we identify the reasons that Adam generalizes worse than SGD, and develop a variant of Adam to eliminate the generalization gap. The proposed method, normalized direction-preserving Adam (ND-Adam), enables more precise control of the direction and step size for updating weight vectors, leading to significantly improved generalization performance. Following a similar rationale, we further improve the generalization performance in classification tasks by regularizing the softmax logits. By bridging the gap between SGD and Adam, we also hope to shed light on why certain optimization algorithms generalize better than others.
Asynchronous Stochastic Proximal Methods for Nonconvex Nonsmooth Optimization
Sep 15, 2018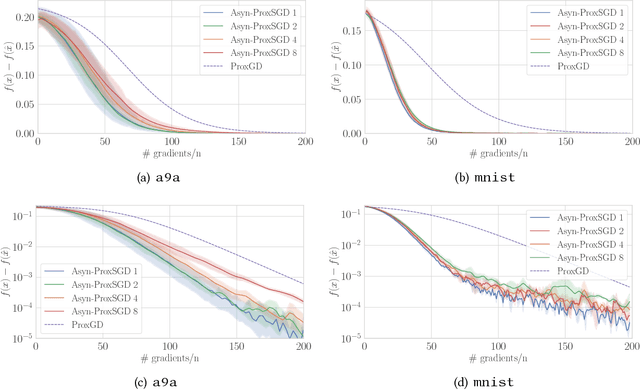

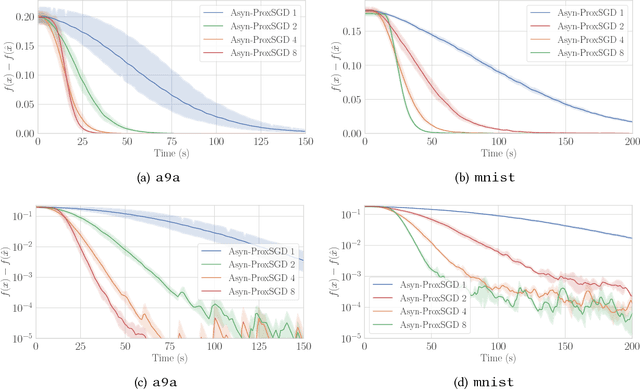

We study stochastic algorithms for solving nonconvex optimization problems with a convex yet possibly nonsmooth regularizer, which find wide applications in many practical machine learning applications. However, compared to asynchronous parallel stochastic gradient descent (AsynSGD), an algorithm targeting smooth optimization, the understanding of the behavior of stochastic algorithms for nonsmooth regularized optimization problems is limited, especially when the objective function is nonconvex. To fill this theoretical gap, in this paper, we propose and analyze asynchronous parallel stochastic proximal gradient (Asyn-ProxSGD) methods for nonconvex problems. We establish an ergodic convergence rate of $O(1/\sqrt{K})$ for the proposed Asyn-ProxSGD, where $K$ is the number of updates made on the model, matching the convergence rate currently known for AsynSGD (for smooth problems). To our knowledge, this is the first work that provides convergence rates of asynchronous parallel ProxSGD algorithms for nonconvex problems. Furthermore, our results are also the first to show the convergence of any stochastic proximal methods without assuming an increasing batch size or the use of additional variance reduction techniques. We implement the proposed algorithms on Parameter Server and demonstrate its convergence behavior and near-linear speedup, as the number of workers increases, on two real-world datasets.
A Block-wise, Asynchronous and Distributed ADMM Algorithm for General Form Consensus Optimization
Feb 24, 2018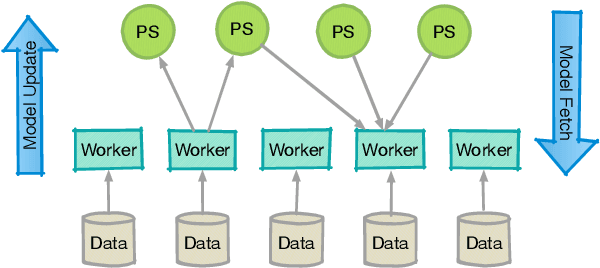
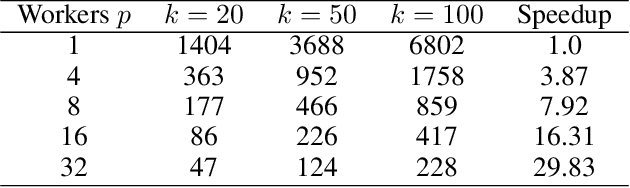
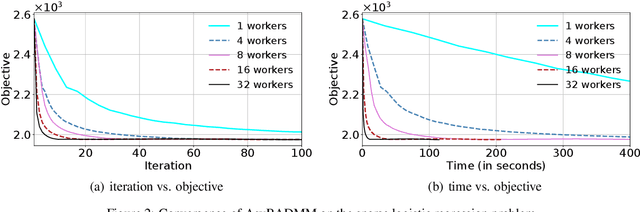
Many machine learning models, including those with non-smooth regularizers, can be formulated as consensus optimization problems, which can be solved by the alternating direction method of multipliers (ADMM). Many recent efforts have been made to develop asynchronous distributed ADMM to handle large amounts of training data. However, all existing asynchronous distributed ADMM methods are based on full model updates and require locking all global model parameters to handle concurrency, which essentially serializes the updates from different workers. In this paper, we present a novel block-wise, asynchronous and distributed ADMM algorithm, which allows different blocks of model parameters to be updated in parallel. The lock-free block-wise algorithm may greatly speedup sparse optimization problems, a common scenario in reality, in which most model updates only modify a subset of all decision variables. We theoretically prove the convergence of our proposed algorithm to stationary points for non-convex general form consensus problems with possibly non-smooth regularizers. We implement the proposed ADMM algorithm on the Parameter Server framework and demonstrate its convergence and near-linear speedup performance as the number of workers increases.
Expectile Matrix Factorization for Skewed Data Analysis
Mar 03, 2017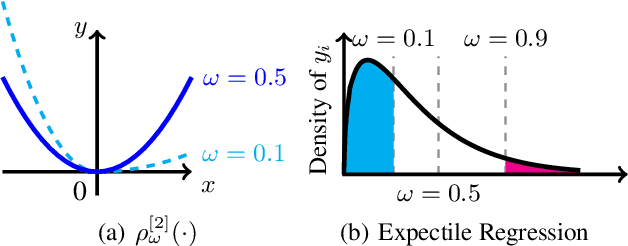
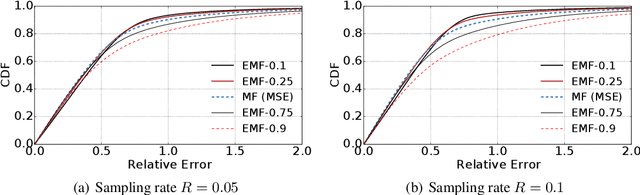
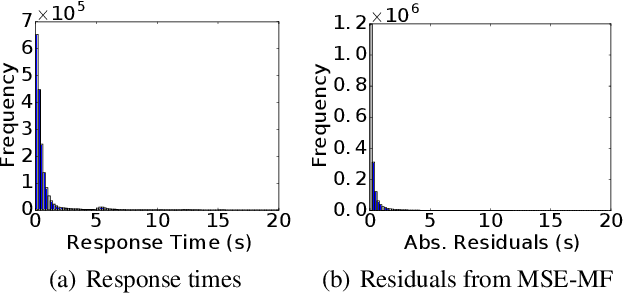
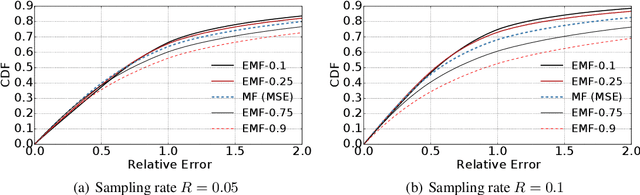
Matrix factorization is a popular approach to solving matrix estimation problems based on partial observations. Existing matrix factorization is based on least squares and aims to yield a low-rank matrix to interpret the conditional sample means given the observations. However, in many real applications with skewed and extreme data, least squares cannot explain their central tendency or tail distributions, yielding undesired estimates. In this paper, we propose \emph{expectile matrix factorization} by introducing asymmetric least squares, a key concept in expectile regression analysis, into the matrix factorization framework. We propose an efficient algorithm to solve the new problem based on alternating minimization and quadratic programming. We prove that our algorithm converges to a global optimum and exactly recovers the true underlying low-rank matrices when noise is zero. For synthetic data with skewed noise and a real-world dataset containing web service response times, the proposed scheme achieves lower recovery errors than the existing matrix factorization method based on least squares in a wide range of settings.