 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoformulation of Mathematical Optimization Models Using LLMs
Nov 03, 2024



Mathematical optimization is fundamental to decision-making across diverse domains, from operations research to healthcare. Yet, translating real-world problems into optimization models remains a formidable challenge, often demanding specialized expertise. This paper formally introduces the concept of $\textbf{autoformulation}$ -- an automated approach to creating optimization models from natural language descriptions for commercial solvers. We identify the three core challenges of autoformulation: (1) defining the vast, problem-dependent hypothesis space, (2) efficiently searching this space under uncertainty, and (3) evaluating formulation correctness (ensuring a formulation accurately represents the problem). To address these challenges, we introduce a novel method leveraging $\textit{Large Language Models}$ (LLMs) within a $\textit{Monte-Carlo Tree Search}$ framework. This approach systematically explores the space of possible formulations by exploiting the hierarchical nature of optimization modeling. LLMs serve two key roles: as dynamic formulation hypothesis generators and as evaluators of formulation correctness. To enhance search efficiency, we introduce a pruning technique to remove trivially equivalent formulations. Empirical evaluations across benchmarks containing linear and mixed-integer programming problems demonstrate our method's superior performance. Additionally, we observe significant efficiency gains from employing LLMs for correctness evaluation and from our pruning techniques.
Truncated Non-Uniform Quantization for Distributed SGD
Feb 02, 2024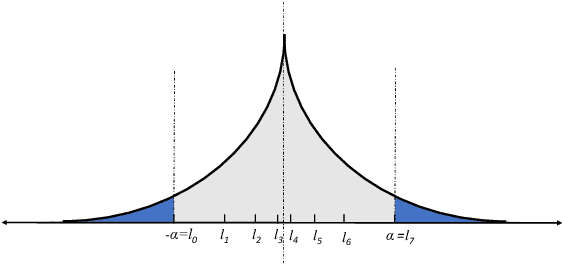
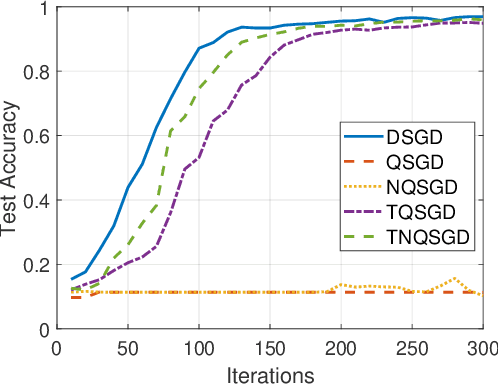
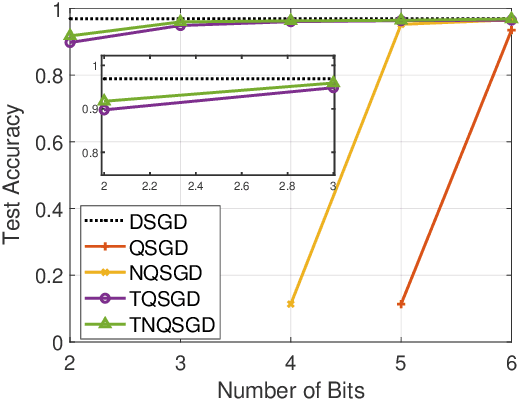
To address the communication bottleneck challenge in distributed learning, our work introduces a novel two-stage quantization strategy designed to enhance the communication efficiency of distributed Stochastic Gradient Descent (SGD). The proposed method initially employs truncation to mitigate the impact of long-tail noise, followed by a non-uniform quantization of the post-truncation gradients based on their statistical characteristics. We provide a comprehensive convergence analysis of the quantized distributed SGD, establishing theoretical guarantees for its performance. Furthermore, by minimizing the convergence error, we derive optimal closed-form solutions for the truncation threshold and non-uniform quantization levels under given communication constraints. Both theoretical insights and extensive experimental evaluations demonstrate that our proposed algorithm outperforms existing quantization schemes, striking a superior balance between communication efficiency and convergence performance.
Improved Quantization Strategies for Managing Heavy-tailed Gradients in Distributed Learning
Feb 02, 2024Gradient compression has surfaced as a key technique to address the challenge of communication efficiency in distributed learning. In distributed deep learning, however, it is observed that gradient distributions are heavy-tailed, with outliers significantly influencing the design of compression strategies. Existing parameter quantization methods experience performance degradation when this heavy-tailed feature is ignored. In this paper, we introduce a novel compression scheme specifically engineered for heavy-tailed gradients, which effectively combines gradient truncation with quantization. This scheme is adeptly implemented within a communication-limited distributed Stochastic Gradient Descent (SGD) framework. We consider a general family of heavy-tail gradients that follow a power-law distribution, we aim to minimize the error resulting from quantization, thereby determining optimal values for two critical parameters: the truncation threshold and the quantization density. We provide a theoretical analysis on the convergence error bound under both uniform and non-uniform quantization scenarios. Comparative experiments with other benchmarks demonstrate the effectiveness of our proposed method in managing the heavy-tailed gradients in a distributed learning environment.
Integrating Large Language Models into Recommendation via Mutual Augmentation and Adaptive Aggregation
Jan 25, 2024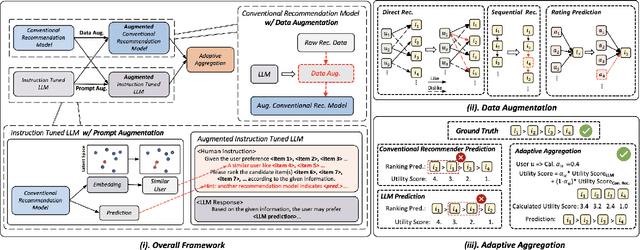
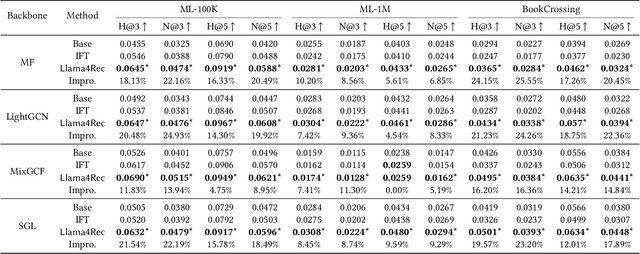
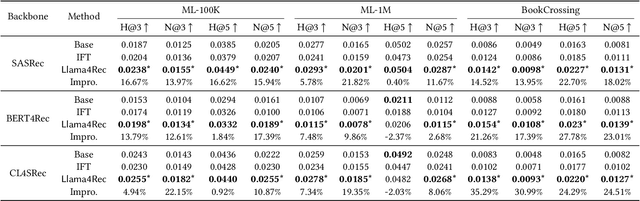
Conventional recommendation methods have achieved notable advancements by harnessing collaborative or sequential information from user behavior. Recently, large language models (LLMs) have gained prominence for their capabilities in understanding and reasoning over textual semantics, and have found utility in various domains, including recommendation. Conventional recommendation methods and LLMs each have their strengths and weaknesses. While conventional methods excel at mining collaborative information and modeling sequential behavior, they struggle with data sparsity and the long-tail problem. LLMs, on the other hand, are proficient at utilizing rich textual contexts but face challenges in mining collaborative or sequential information. Despite their individual successes, there is a significant gap in leveraging their combined potential to enhance recommendation performance. In this paper, we introduce a general and model-agnostic framework known as \textbf{L}arge \textbf{la}nguage model with \textbf{m}utual augmentation and \textbf{a}daptive aggregation for \textbf{Rec}ommendation (\textbf{Llama4Rec}). Llama4Rec synergistically combines conventional and LLM-based recommendation models. Llama4Rec proposes data augmentation and prompt augmentation strategies tailored to enhance the conventional model and LLM respectively. An adaptive aggregation module is adopted to combine the predictions of both kinds of models to refine the final recommendation results. Empirical studies on three real-world datasets validate the superiority of Llama4Rec, demonstrating its consistent outperformance of baseline methods and significant improvements in recommendation performance.
RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation
Jan 15, 2024



Large language models (LLMs) have demonstrated remarkable capabilities and have been extensively deployed across various domains, including recommender systems. Numerous studies have employed specialized \textit{prompts} to harness the in-context learning capabilities intrinsic to LLMs. For example, LLMs are prompted to act as zero-shot rankers for listwise ranking, evaluating candidate items generated by a retrieval model for recommendation. Recent research further uses instruction tuning techniques to align LLM with human preference for more promising recommendations. Despite its potential, current research overlooks the integration of multiple ranking tasks to enhance model performance. Moreover, the signal from the conventional recommendation model is not integrated into the LLM, limiting the current system performance. In this paper, we introduce RecRanker, tailored for instruction tuning LLM to serve as the \textbf{Ranker} for top-\textit{k} \textbf{Rec}ommendations. Specifically, we introduce importance-aware sampling, clustering-based sampling, and penalty for repetitive sampling for sampling high-quality, representative, and diverse training data. To enhance the prompt, we introduce position shifting strategy to mitigate position bias and augment the prompt with auxiliary information from conventional recommendation models, thereby enriching the contextual understanding of the LLM. Subsequently, we utilize the sampled data to assemble an instruction-tuning dataset with the augmented prompt comprising three distinct ranking tasks: pointwise, pairwise, and listwise rankings. We further propose a hybrid ranking method to enhance the model performance by ensembling these ranking tasks. Our empirical evaluations demonstrate the effectiveness of our proposed RecRanker in both direct and sequential recommendation scenarios.
Unsupervised Massive MIMO Channel Estimation with Dual-Path Knowledge-Aware Auto-Encoders
May 30, 2023


In this paper, an unsupervised deep learning framework based on dual-path model-driven variational auto-encoders (VAE) is proposed for angle-of-arrivals (AoAs) and channel estimation in massive MIMO systems. Specifically designed for channel estimation, the proposed VAE differs from the original VAE in two aspects. First, the encoder is a dual-path neural network, where one path uses the received signal to estimate the path gains and path angles, and another uses the correlation matrix of the received signal to estimate AoAs. Second, the decoder has fixed weights that implement the signal propagation model, instead of learnable parameters. This knowledge-aware decoder forces the encoder to output meaningful physical parameters of interests (i.e., path gains, path angles, and AoAs), which cannot be achieved by original VAE. Rigorous analysis is carried out to characterize the multiple global optima and local optima of the estimation problem, which motivates the design of the dual-path encoder. By alternating between the estimation of path gains, path angles and the estimation of AoAs, the encoder is proved to converge. To further improve the convergence performance, a low-complexity procedure is proposed to find good initial points. Numerical results validate theoretical analysis and demonstrate the performance improvements of our proposed framework.
PerFedRec++: Enhancing Personalized Federated Recommendation with Self-Supervised Pre-Training
May 11, 2023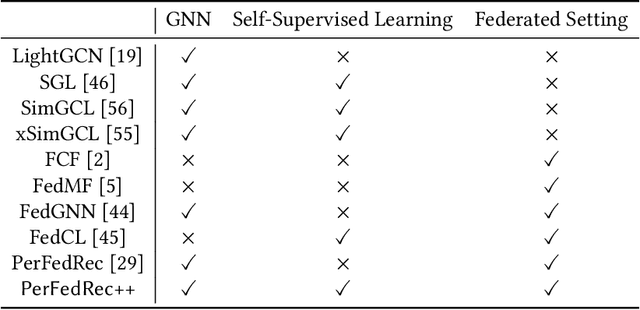
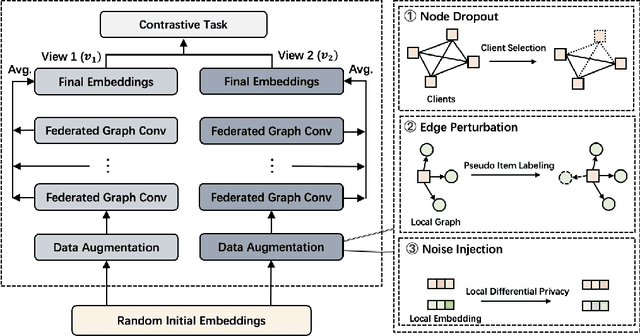

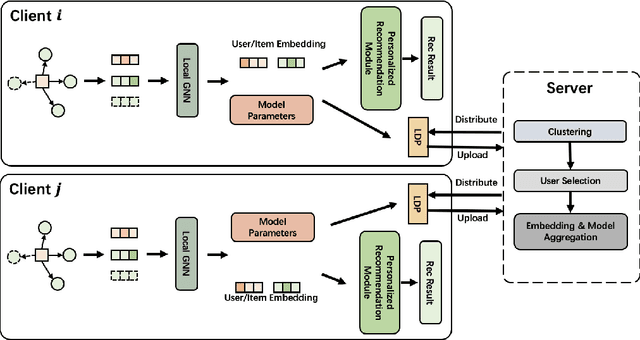
Federated recommendation systems employ federated learning techniques to safeguard user privacy by transmitting model parameters instead of raw user data between user devices and the central server. Nevertheless, the current federated recommender system faces challenges such as heterogeneity and personalization, model performance degradation, and communication bottleneck. Previous studies have attempted to address these issues, but none have been able to solve them simultaneously. In this paper, we propose a novel framework, named PerFedRec++, to enhance the personalized federated recommendation with self-supervised pre-training. Specifically, we utilize the privacy-preserving mechanism of federated recommender systems to generate two augmented graph views, which are used as contrastive tasks in self-supervised graph learning to pre-train the model. Pre-training enhances the performance of federated models by improving the uniformity of representation learning. Also, by providing a better initial state for federated training, pre-training makes the overall training converge faster, thus alleviating the heavy communication burden. We then construct a collaborative graph to learn the client representation through a federated graph neural network. Based on these learned representations, we cluster users into different user groups and learn personalized models for each cluster. Each user learns a personalized model by combining the global federated model, the cluster-level federated model, and its own fine-tuned local model. Experiments on three real-world datasets show that our proposed method achieves superior performance over existing methods.
Adaptive Top-K in SGD for Communication-Efficient Distributed Learning
Oct 24, 2022



Distributed stochastic gradient descent (SGD) with gradient compression has emerged as a communication-efficient solution to accelerate distributed learning. Top-K sparsification is one of the most popular gradient compression methods that sparsifies the gradient in a fixed degree during model training. However, there lacks an approach to adaptively adjust the degree of sparsification to maximize the potential of model performance or training speed. This paper addresses this issue by proposing a novel adaptive Top-K SGD framework, enabling adaptive degree of sparsification for each gradient descent step to maximize the convergence performance by exploring the trade-off between communication cost and convergence error. Firstly, we derive an upper bound of the convergence error for the adaptive sparsification scheme and the loss function. Secondly, we design the algorithm by minimizing the convergence error under the communication cost constraints. Finally, numerical results show that the proposed adaptive Top-K in SGD achieves a significantly better convergence rate compared with the state-of-the-art methods.
Towards Communication Efficient and Fair Federated Personalized Sequential Recommendation
Aug 24, 2022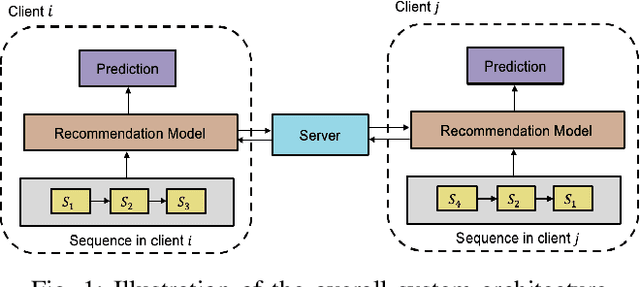
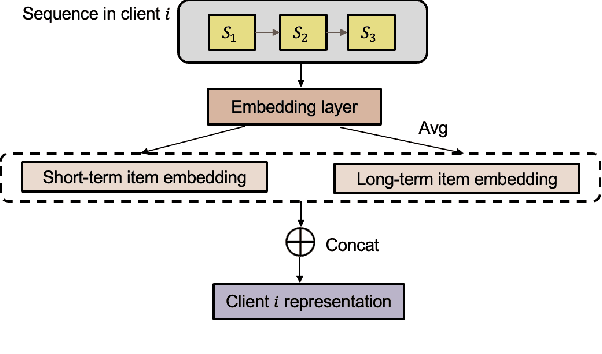
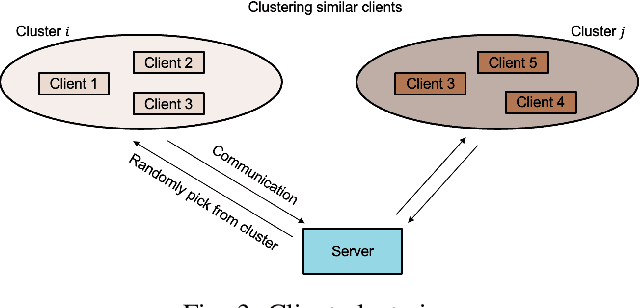
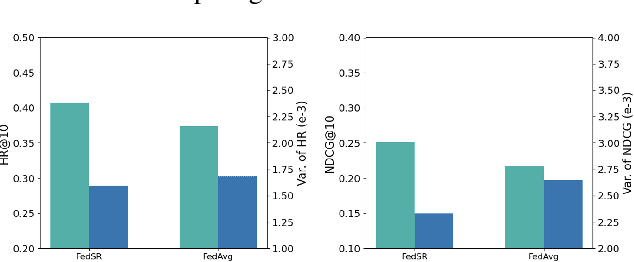
Federated recommendations leverage the federated learning (FL) techniques to make privacy-preserving recommendations. Though recent success in the federated recommender system, several vital challenges remain to be addressed: (i) The majority of federated recommendation models only consider the model performance and the privacy-preserving ability, while ignoring the optimization of the communication process; (ii) Most of the federated recommenders are designed for heterogeneous systems, causing unfairness problems during the federation process; (iii) The personalization techniques have been less explored in many federated recommender systems. In this paper, we propose a Communication efficient and Fair personalized Federated personalized Sequential Recommendation algorithm (CF-FedSR) to tackle these challenges. CF-FedSR introduces a communication-efficient scheme that employs adaptive client selection and clustering-based sampling to accelerate the training process. A fairness-aware model aggregation algorithm that can adaptively capture the data and performance imbalance among different clients to address the unfairness problems is proposed. The personalization module assists clients in making personalized recommendations and boosts the recommendation performance via local fine-tuning and model adaption. Extensive experimental results show the effectiveness and efficiency of our proposed method.
HySAGE: A Hybrid Static and Adaptive Graph Embedding Network for Context-Drifting Recommendations
Aug 20, 2022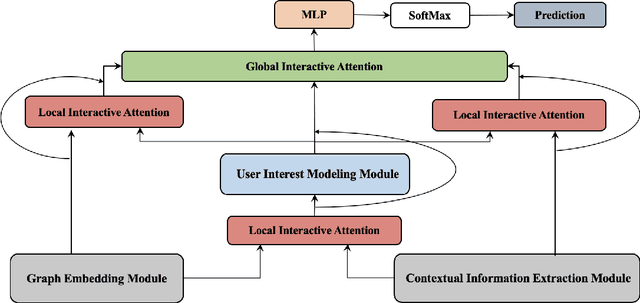
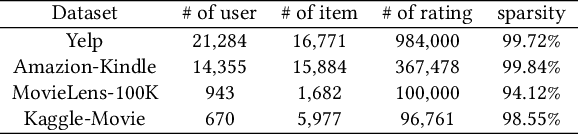
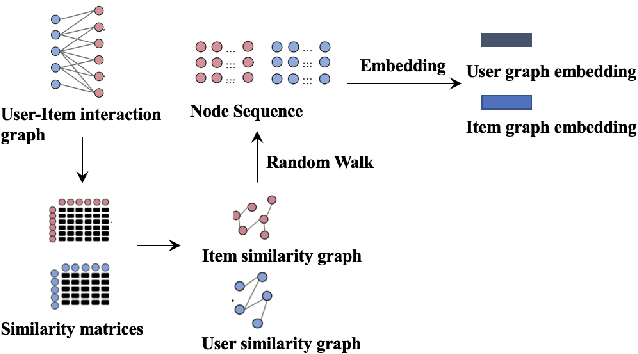
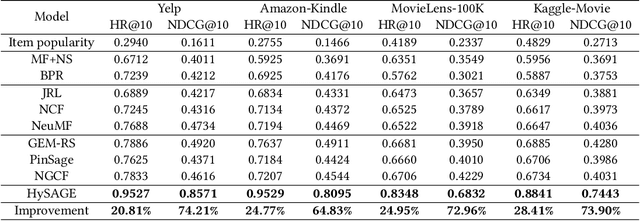
The recent popularity of edge devices and Artificial Intelligent of Things (AIoT) has driven a new wave of contextual recommendations, such as location based Point of Interest (PoI) recommendations and computing resource-aware mobile app recommendations. In many such recommendation scenarios, contexts are drifting over time. For example, in a mobile game recommendation, contextual features like locations, battery, and storage levels of mobile devices are frequently drifting over time. However, most existing graph-based collaborative filtering methods are designed under the assumption of static features. Therefore, they would require frequent retraining and/or yield graphical models burgeoning in sizes, impeding their suitability for context-drifting recommendations. In this work, we propose a specifically tailor-made Hybrid Static and Adaptive Graph Embedding (HySAGE) network for context-drifting recommendations. Our key idea is to disentangle the relatively static user-item interaction and rapidly drifting contextual features. Specifically, our proposed HySAGE network learns a relatively static graph embedding from user-item interaction and an adaptive embedding from drifting contextual features. These embeddings are incorporated into an interest network to generate the user interest in some certain context. We adopt an interactive attention module to learn the interactions among static graph embeddings, adaptive contextual embeddings, and user interest, helping to achieve a better final representation. Extensive experiments on real-world datasets demonstrate that HySAGE significantly improves the performance of the existing state-of-the-art recommendation algorithms.