 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-by-Step Optimization-like Reasoning in LLMs over Expanding Search Spaces
Jun 03, 2026Verifiable reward training has improved mathematical and coding reasoning, but these domains capture only part of step-by-step decision making. Many real-world tasks require finding a high-value feasible plan among many valid alternatives. We introduce OPT*, a scalable family of optimization-style tasks for training and evaluating LLM step-by-step optimization-like reasoning along a complexity axis: each task provides a feasibility checker and evaluator, while a complexity parameter expands the search space without requiring new human labels. This motivates studying these tasks in two regimes: (i) solver-guided online policy optimization, which uses a solver as a value oracle for partial states and applies rank-based reward shaping to reinforce better next steps, and (ii) search-based offline RL when such solvers are unavailable. Theoretically, we relate success in large search spaces to the information a reasoner extracts per unit of search budget. Empirically, we ablate the ingredients that make search efficient on OPT* and show that training on OPT* improves step-by-step optimization-like reasoning.
Timely Clinical Diagnosis through Active Test Selection
Oct 21, 2025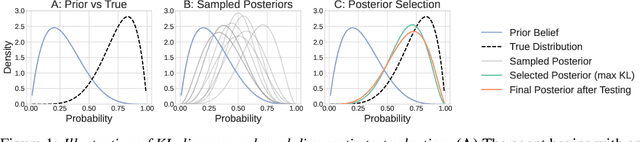



There is growing interest in using machine learning (ML) to support clinical diag- nosis, but most approaches rely on static, fully observed datasets and fail to reflect the sequential, resource-aware reasoning clinicians use in practice. Diagnosis remains complex and error prone, especially in high-pressure or resource-limited settings, underscoring the need for frameworks that help clinicians make timely and cost-effective decisions. We propose ACTMED (Adaptive Clinical Test selection via Model-based Experimental Design), a diagnostic framework that integrates Bayesian Experimental Design (BED) with large language models (LLMs) to better emulate real-world diagnostic reasoning. At each step, ACTMED selects the test expected to yield the greatest reduction in diagnostic uncertainty for a given patient. LLMs act as flexible simulators, generating plausible patient state distributions and supporting belief updates without requiring structured, task-specific training data. Clinicians can remain in the loop; reviewing test suggestions, interpreting intermediate outputs, and applying clinical judgment throughout. We evaluate ACTMED on real-world datasets and show it can optimize test selection to improve diagnostic accuracy, interpretability, and resource use. This represents a step to- ward transparent, adaptive, and clinician-aligned diagnostic systems that generalize across settings with reduced reliance on domain-specific data.
Learning a Dense Reasoning Reward Model from Expert Demonstration via Inverse Reinforcement Learning
Oct 02, 2025We reframe and operationalise adversarial inverse reinforcement learning (IRL) to large language model reasoning, learning a dense, token-level reward model for process supervision directly from expert demonstrations rather than imitating style via supervised fine-tuning. The learned reasoning reward serves two complementary roles: (i) it provides step-level feedback to optimise a reasoning policy during training; and (ii) it functions at inference as a critic to rerank sampled traces under fixed compute budgets. We demonstrate that our approach prioritises correctness over surface form, yielding scores that correlate with eventual answer validity and enabling interpretable localisation of errors within a trace. Empirically, on GSM8K with Llama3 and Qwen2.5 backbones, we demonstrate: (i) dense reasoning rewards can be used as a learning signal to elicit reasoning, and (ii) predictive performance is improved from reward-guided reranking (notably for Llama-based policies). By unifying training signals, inference-time selection, and token-level diagnostics into a single reasoning reward, this work suggests reusable process-level rewards with broad potential to enhance multi-step reasoning in language models.
Continuously Updating Digital Twins using Large Language Models
Jun 11, 2025Digital twins are models of real-world systems that can simulate their dynamics in response to potential actions. In complex settings, the state and action variables, and available data and knowledge relevant to a system can constantly change, requiring digital twins to continuously update with these changes to remain relevant. Current approaches struggle in this regard, as they require fixed, well-defined modelling environments, and they cannot adapt to novel variables without re-designs, or incorporate new information without re-training. To address this, we frame digital twinning as an in-context learning problem using large language models, enabling seamless updates to the twin at inference time. We develop CALM-DT, a Context-Adaptive Language Model-based Digital Twin that can accurately simulate across diverse state-action spaces using in-context learning alone by utilising fine-tuned encoders for sample retrieval. We empirically demonstrate CALM-DT's competitive performance with existing digital twin approaches, and its unique ability to adapt to changes in its modelling environment without parameter updates.
Autoformulation of Mathematical Optimization Models Using LLMs
Nov 03, 2024



Mathematical optimization is fundamental to decision-making across diverse domains, from operations research to healthcare. Yet, translating real-world problems into optimization models remains a formidable challenge, often demanding specialized expertise. This paper formally introduces the concept of $\textbf{autoformulation}$ -- an automated approach to creating optimization models from natural language descriptions for commercial solvers. We identify the three core challenges of autoformulation: (1) defining the vast, problem-dependent hypothesis space, (2) efficiently searching this space under uncertainty, and (3) evaluating formulation correctness (ensuring a formulation accurately represents the problem). To address these challenges, we introduce a novel method leveraging $\textit{Large Language Models}$ (LLMs) within a $\textit{Monte-Carlo Tree Search}$ framework. This approach systematically explores the space of possible formulations by exploiting the hierarchical nature of optimization modeling. LLMs serve two key roles: as dynamic formulation hypothesis generators and as evaluators of formulation correctness. To enhance search efficiency, we introduce a pruning technique to remove trivially equivalent formulations. Empirical evaluations across benchmarks containing linear and mixed-integer programming problems demonstrate our method's superior performance. Additionally, we observe significant efficiency gains from employing LLMs for correctness evaluation and from our pruning techniques.
Large Language Models to Enhance Bayesian Optimization
Feb 06, 2024Bayesian optimization (BO) is a powerful approach for optimizing complex and expensive-to-evaluate black-box functions. Its importance is underscored in many applications, notably including hyperparameter tuning, but its efficacy depends on efficiently balancing exploration and exploitation. While there has been substantial progress in BO methods, striking this balance still remains a delicate process. In this light, we present \texttt{LLAMBO}, a novel approach that integrates the capabilities of large language models (LLM) within BO. At a high level, we frame the BO problem in natural language terms, enabling LLMs to iteratively propose promising solutions conditioned on historical evaluations. More specifically, we explore how combining contextual understanding, few-shot learning proficiency, and domain knowledge of LLMs can enhance various components of model-based BO. Our findings illustrate that \texttt{LLAMBO} is effective at zero-shot warmstarting, and improves surrogate modeling and candidate sampling, especially in the early stages of search when observations are sparse. Our approach is performed in context and does not require LLM finetuning. Additionally, it is modular by design, allowing individual components to be integrated into existing BO frameworks, or function cohesively as an end-to-end method. We empirically validate \texttt{LLAMBO}'s efficacy on the problem of hyperparameter tuning, highlighting strong empirical performance across a range of diverse benchmarks, proprietary, and synthetic tasks.
Multi-Class Deep SVDD: Anomaly Detection Approach in Astronomy with Distinct Inlier Categories
Aug 10, 2023

With the increasing volume of astronomical data generated by modern survey telescopes, automated pipelines and machine learning techniques have become crucial for analyzing and extracting knowledge from these datasets. Anomaly detection, i.e. the task of identifying irregular or unexpected patterns in the data, is a complex challenge in astronomy. In this paper, we propose Multi-Class Deep Support Vector Data Description (MCDSVDD), an extension of the state-of-the-art anomaly detection algorithm One-Class Deep SVDD, specifically designed to handle different inlier categories with distinct data distributions. MCDSVDD uses a neural network to map the data into hyperspheres, where each hypersphere represents a specific inlier category. The distance of each sample from the centers of these hyperspheres determines the anomaly score. We evaluate the effectiveness of MCDSVDD by comparing its performance with several anomaly detection algorithms on a large dataset of astronomical light-curves obtained from the Zwicky Transient Facility. Our results demonstrate the efficacy of MCDSVDD in detecting anomalous sources while leveraging the presence of different inlier categories. The code and the data needed to reproduce our results are publicly available at https://github.com/mperezcarrasco/AnomalyALeRCE.
MPCC: Matching Priors and Conditionals for Clustering
Aug 21, 2020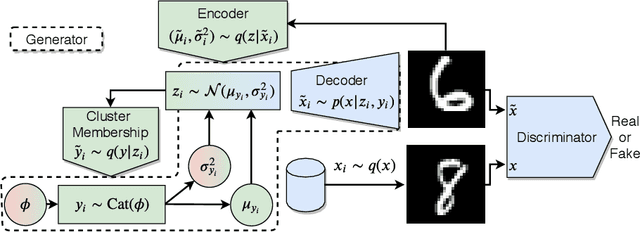


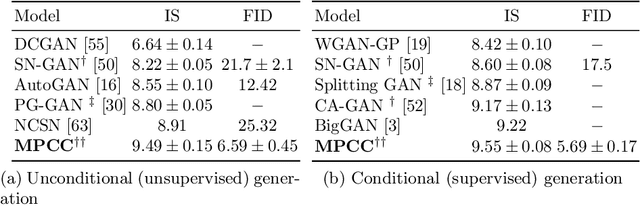
Clustering is a fundamental task in unsupervised learning that depends heavily on the data representation that is used. Deep generative models have appeared as a promising tool to learn informative low-dimensional data representations. We propose Matching Priors and Conditionals for Clustering (MPCC), a GAN-based model with an encoder to infer latent variables and cluster categories from data, and a flexible decoder to generate samples from a conditional latent space. With MPCC we demonstrate that a deep generative model can be competitive/superior against discriminative methods in clustering tasks surpassing the state of the art over a diverse set of benchmark datasets. Our experiments show that adding a learnable prior and augmenting the number of encoder updates improve the quality of the generated samples, obtaining an inception score of 9.49 $\pm$ 0.15 and improving the Fr\'echet inception distance over the state of the art by a 46.9% in CIFAR10.
Adversarial Variational Domain Adaptation
Sep 26, 2019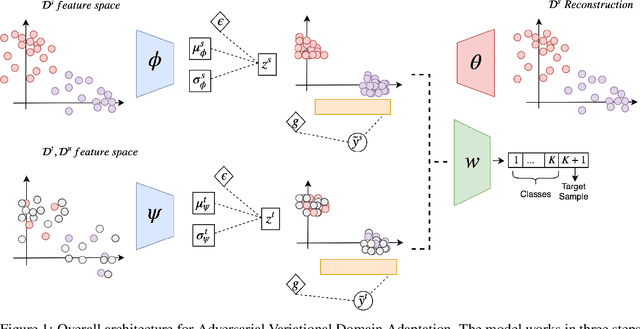
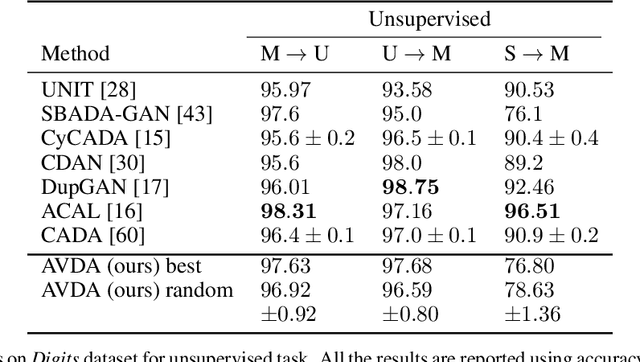

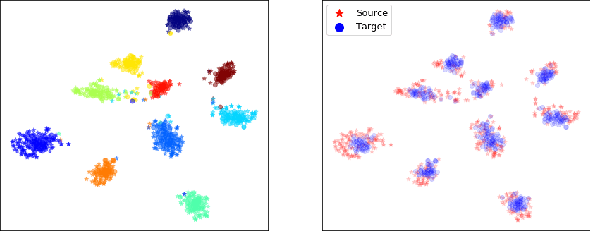
In this work we address the problem of transferring knowledge obtained from a vast annotated source domain to a low labeled or unlabeled target domain. We propose Adversarial Variational Domain Adaptation (AVDA), a semi-supervised domain adaptation method based on deep variational embedded representations. We use approximate inference and adversarial methods to map samples from source and target domains into an aligned semantic embedding. We show that on a semi-supervised few-shot scenario, our approach can be used to obtain a significant speed-up in performance when using an increasing number of labels on the target domain.