 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral shadow removal with Iterative Logistic Regression and latent Parametric Linear Combination of Gaussians
Dec 24, 2023Shadow detection and removal is a challenging problem in the analysis of hyperspectral images. Yet, this step is crucial for analyzing data for remote sensing applications like methane detection. In this work, we develop a shadow detection and removal method only based on the spectrum of each pixel and the overall distribution of spectral values. We first introduce Iterative Logistic Regression (ILR) to learn a spectral basis in which shadows can be linearly classified. We then model the joint distribution of the mean radiance and the projection coefficients of the spectra onto the above basis as a parametric linear combination of Gaussians. We can then extract the maximum likelihood mixing parameter of the Gaussians to estimate the shadow coverage and to correct the shadowed spectra. Our correction scheme reduces correction artefacts at shadow borders. The shadow detection and removal method is applied to hyperspectral images from MethaneAIR, a precursor to the satellite MethaneSAT.
Domain Adaptation via Minimax Entropy for Real/Bogus Classification of Astronomical Alerts
Aug 15, 2023

Time domain astronomy is advancing towards the analysis of multiple massive datasets in real time, prompting the development of multi-stream machine learning models. In this work, we study Domain Adaptation (DA) for real/bogus classification of astronomical alerts using four different datasets: HiTS, DES, ATLAS, and ZTF. We study the domain shift between these datasets, and improve a naive deep learning classification model by using a fine tuning approach and semi-supervised deep DA via Minimax Entropy (MME). We compare the balanced accuracy of these models for different source-target scenarios. We find that both the fine tuning and MME models improve significantly the base model with as few as one labeled item per class coming from the target dataset, but that the MME does not compromise its performance on the source dataset.
Multi-Class Deep SVDD: Anomaly Detection Approach in Astronomy with Distinct Inlier Categories
Aug 10, 2023With the increasing volume of astronomical data generated by modern survey telescopes, automated pipelines and machine learning techniques have become crucial for analyzing and extracting knowledge from these datasets. Anomaly detection, i.e. the task of identifying irregular or unexpected patterns in the data, is a complex challenge in astronomy. In this paper, we propose Multi-Class Deep Support Vector Data Description (MCDSVDD), an extension of the state-of-the-art anomaly detection algorithm One-Class Deep SVDD, specifically designed to handle different inlier categories with distinct data distributions. MCDSVDD uses a neural network to map the data into hyperspheres, where each hypersphere represents a specific inlier category. The distance of each sample from the centers of these hyperspheres determines the anomaly score. We evaluate the effectiveness of MCDSVDD by comparing its performance with several anomaly detection algorithms on a large dataset of astronomical light-curves obtained from the Zwicky Transient Facility. Our results demonstrate the efficacy of MCDSVDD in detecting anomalous sources while leveraging the presence of different inlier categories. The code and the data needed to reproduce our results are publicly available at https://github.com/mperezcarrasco/AnomalyALeRCE.
Con$^{2}$DA: Simplifying Semi-supervised Domain Adaptation by Learning Consistent and Contrastive Feature Representations
Apr 04, 2022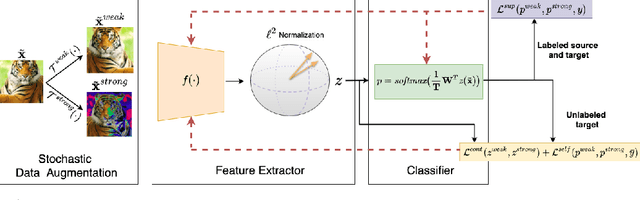
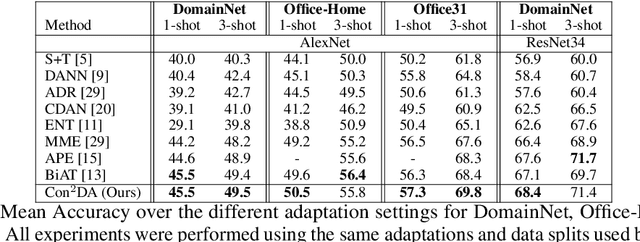
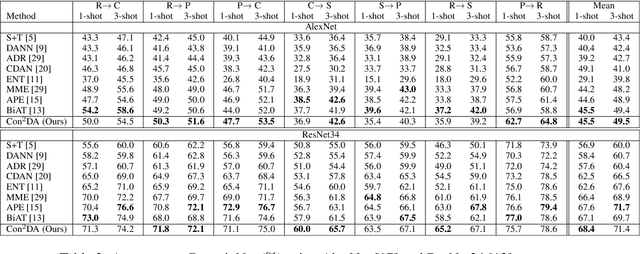
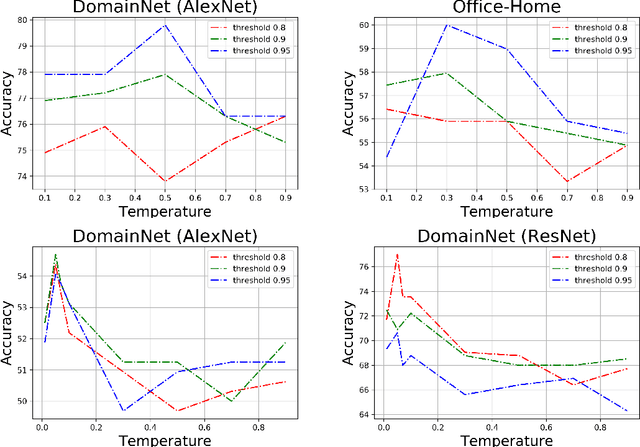
In this work, we present Con$^{2}$DA, a simple framework that extends recent advances in semi-supervised learning to the semi-supervised domain adaptation (SSDA) problem. Our framework generates pairs of associated samples by performing stochastic data transformations to a given input. Associated data pairs are mapped to a feature representation space using a feature extractor. We use different loss functions to enforce consistency between the feature representations of associated data pairs of samples. We show that these learned representations are useful to deal with differences in data distributions in the domain adaptation problem. We performed experiments to study the main components of our model and we show that (i) learning of the consistent and contrastive feature representations is crucial to extract good discriminative features across different domains, and ii) our model benefits from the use of strong augmentation policies. With these findings, our method achieves state-of-the-art performances in three benchmark datasets for SSDA.
* 11 pages, 3 figures, 4 tables
Adversarial Variational Domain Adaptation
Sep 26, 2019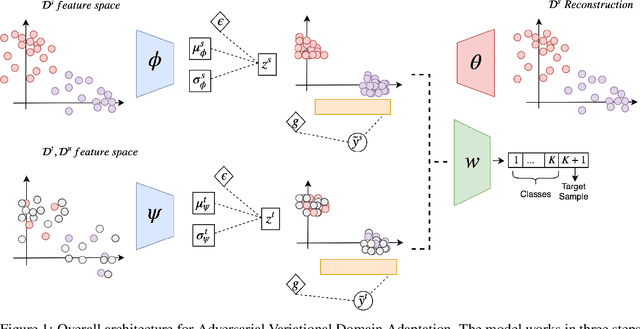
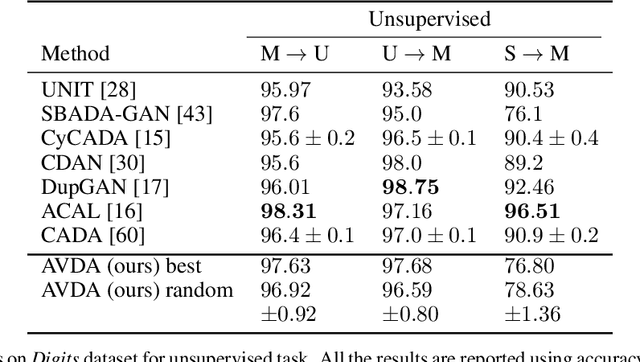

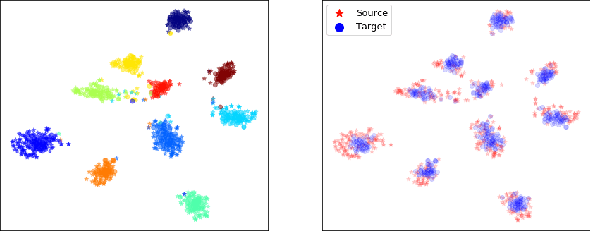
In this work we address the problem of transferring knowledge obtained from a vast annotated source domain to a low labeled or unlabeled target domain. We propose Adversarial Variational Domain Adaptation (AVDA), a semi-supervised domain adaptation method based on deep variational embedded representations. We use approximate inference and adversarial methods to map samples from source and target domains into an aligned semantic embedding. We show that on a semi-supervised few-shot scenario, our approach can be used to obtain a significant speed-up in performance when using an increasing number of labels on the target domain.