 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline-Grounded Evidence Accumulation for High-Stakes Agent Verification
Mar 03, 2026As LLM-powered agents have been used for high-stakes decision-making, such as clinical diagnosis, it becomes critical to develop reliable verification of their decisions to facilitate trustworthy deployment. Yet, existing verifiers usually underperform owing to a lack of domain knowledge and limited calibration. To address this, we establish GLEAN, an agent verification framework with Guideline-grounded Evidence Accumulation that compiles expert-curated protocols into trajectory-informed, well-calibrated correctness signals. GLEAN evaluates the step-wise alignment with domain guidelines and aggregates multi-guideline ratings into surrogate features, which are accumulated along the trajectory and calibrated into correctness probabilities using Bayesian logistic regression. Moreover, the estimated uncertainty triggers active verification, which selectively collects additional evidence for uncertain cases via expanding guideline coverage and performing differential checks. We empirically validate GLEAN with agentic clinical diagnosis across three diseases from the MIMIC-IV dataset, surpassing the best baseline by 12% in AUROC and 50% in Brier score reduction, which confirms the effectiveness in both discrimination and calibration. In addition, the expert study with clinicians recognizes GLEAN's utility in practice.
Scales++: Compute Efficient Evaluation Subset Selection with Cognitive Scales Embeddings
Oct 30, 2025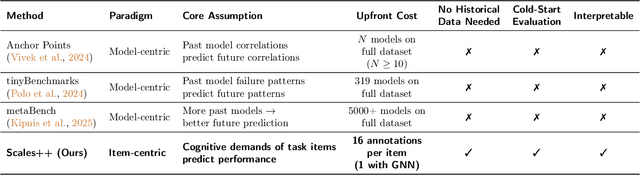
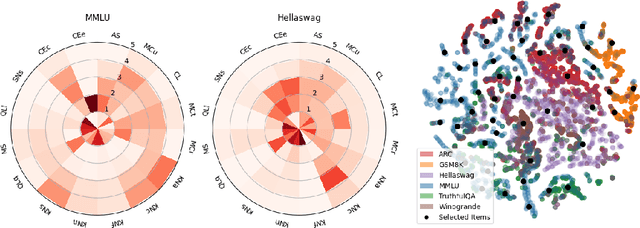
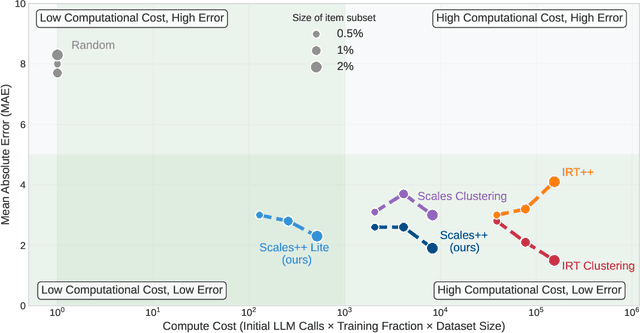
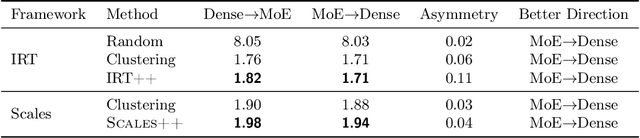
The prohibitive cost of evaluating large language models (LLMs) on comprehensive benchmarks necessitates the creation of small yet representative data subsets (i.e., tiny benchmarks) that enable efficient assessment while retaining predictive fidelity. Current methods for this task operate under a model-centric paradigm, selecting benchmarking items based on the collective performance of existing models. Such approaches are limited by large upfront costs, an inability to immediately handle new benchmarks (`cold-start'), and the fragile assumption that future models will share the failure patterns of their predecessors. In this work, we challenge this paradigm and propose a item-centric approach to benchmark subset selection, arguing that selection should be based on the intrinsic properties of the task items themselves, rather than on model-specific failure patterns. We instantiate this item-centric efficient benchmarking approach via a novel method, Scales++, where data selection is based on the cognitive demands of the benchmark samples. Empirically, we show Scales++ reduces the upfront selection cost by over 18x while achieving competitive predictive fidelity. On the Open LLM Leaderboard, using just a 0.5\% data subset, we predict full benchmark scores with a 2.9% mean absolute error. We demonstrate that this item-centric approach enables more efficient model evaluation without significant fidelity degradation, while also providing better cold-start performance and more interpretable benchmarking.
Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses
Sep 19, 2025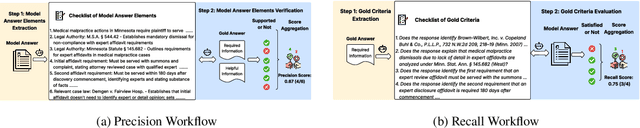



Evaluating long-form answers in high-stakes domains such as law or medicine remains a fundamental challenge. Standard metrics like BLEU and ROUGE fail to capture semantic correctness, and current LLM-based evaluators often reduce nuanced aspects of answer quality into a single undifferentiated score. We introduce DeCE, a decomposed LLM evaluation framework that separates precision (factual accuracy and relevance) and recall (coverage of required concepts), using instance-specific criteria automatically extracted from gold answer requirements. DeCE is model-agnostic and domain-general, requiring no predefined taxonomies or handcrafted rubrics. We instantiate DeCE to evaluate different LLMs on a real-world legal QA task involving multi-jurisdictional reasoning and citation grounding. DeCE achieves substantially stronger correlation with expert judgments ($r=0.78$), compared to traditional metrics ($r=0.12$), pointwise LLM scoring ($r=0.35$), and modern multidimensional evaluators ($r=0.48$). It also reveals interpretable trade-offs: generalist models favor recall, while specialized models favor precision. Importantly, only 11.95% of LLM-generated criteria required expert revision, underscoring DeCE's scalability. DeCE offers an interpretable and actionable LLM evaluation framework in expert domains.
Towards Human-Guided, Data-Centric LLM Co-Pilots
Jan 17, 2025Machine learning (ML) has the potential to revolutionize healthcare, but its adoption is often hindered by the disconnect between the needs of domain experts and translating these needs into robust and valid ML tools. Despite recent advances in LLM-based co-pilots to democratize ML for non-technical domain experts, these systems remain predominantly focused on model-centric aspects while overlooking critical data-centric challenges. This limitation is problematic in complex real-world settings where raw data often contains complex issues, such as missing values, label noise, and domain-specific nuances requiring tailored handling. To address this we introduce CliMB-DC, a human-guided, data-centric framework for LLM co-pilots that combines advanced data-centric tools with LLM-driven reasoning to enable robust, context-aware data processing. At its core, CliMB-DC introduces a novel, multi-agent reasoning system that combines a strategic coordinator for dynamic planning and adaptation with a specialized worker agent for precise execution. Domain expertise is then systematically incorporated to guide the reasoning process using a human-in-the-loop approach. To guide development, we formalize a taxonomy of key data-centric challenges that co-pilots must address. Thereafter, to address the dimensions of the taxonomy, we integrate state-of-the-art data-centric tools into an extensible, open-source architecture, facilitating the addition of new tools from the research community. Empirically, using real-world healthcare datasets we demonstrate CliMB-DC's ability to transform uncurated datasets into ML-ready formats, significantly outperforming existing co-pilot baselines for handling data-centric challenges. CliMB-DC promises to empower domain experts from diverse domains -- healthcare, finance, social sciences and more -- to actively participate in driving real-world impact using ML.
Unlocking Historical Clinical Trial Data with ALIGN: A Compositional Large Language Model System for Medical Coding
Nov 20, 2024



The reuse of historical clinical trial data has significant potential to accelerate medical research and drug development. However, interoperability challenges, particularly with missing medical codes, hinders effective data integration across studies. While Large Language Models (LLMs) offer a promising solution for automated coding without labeled data, current approaches face challenges on complex coding tasks. We introduce ALIGN, a novel compositional LLM-based system for automated, zero-shot medical coding. ALIGN follows a three-step process: (1) diverse candidate code generation; (2) self-evaluation of codes and (3) confidence scoring and uncertainty estimation enabling human deferral to ensure reliability. We evaluate ALIGN on harmonizing medication terms into Anatomical Therapeutic Chemical (ATC) and medical history terms into Medical Dictionary for Regulatory Activities (MedDRA) codes extracted from 22 immunology trials. ALIGN outperformed the LLM baselines, while also providing capabilities for trustworthy deployment. For MedDRA coding, ALIGN achieved high accuracy across all levels, matching RAG and excelling at the most specific levels (87-90% for HLGT). For ATC coding, ALIGN demonstrated superior performance, particularly at lower hierarchy levels (ATC Level 4), with 72-73% overall accuracy and 86-89% accuracy for common medications, outperforming baselines by 7-22%. ALIGN's uncertainty-based deferral improved accuracy by 17% to 90% accuracy with 30% deferral, notably enhancing performance on uncommon medications. ALIGN achieves this cost-efficiently at \$0.0007 and \$0.02 per code for GPT-4o-mini and GPT-4o, reducing barriers to clinical adoption. ALIGN advances automated medical coding for clinical trial data, contributing to enhanced data interoperability and reusability, positioning it as a promising tool to improve clinical research and accelerate drug development.
Context-Aware Testing: A New Paradigm for Model Testing with Large Language Models
Oct 31, 2024



The predominant de facto paradigm of testing ML models relies on either using only held-out data to compute aggregate evaluation metrics or by assessing the performance on different subgroups. However, such data-only testing methods operate under the restrictive assumption that the available empirical data is the sole input for testing ML models, disregarding valuable contextual information that could guide model testing. In this paper, we challenge the go-to approach of data-only testing and introduce context-aware testing (CAT) which uses context as an inductive bias to guide the search for meaningful model failures. We instantiate the first CAT system, SMART Testing, which employs large language models to hypothesize relevant and likely failures, which are evaluated on data using a self-falsification mechanism. Through empirical evaluations in diverse settings, we show that SMART automatically identifies more relevant and impactful failures than alternatives, demonstrating the potential of CAT as a testing paradigm.
Self-Healing Machine Learning: A Framework for Autonomous Adaptation in Real-World Environments
Oct 31, 2024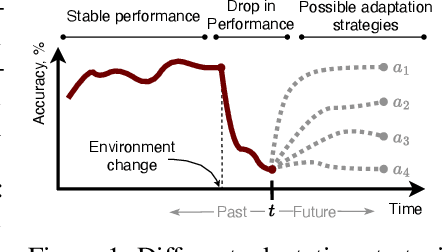



Real-world machine learning systems often encounter model performance degradation due to distributional shifts in the underlying data generating process (DGP). Existing approaches to addressing shifts, such as concept drift adaptation, are limited by their reason-agnostic nature. By choosing from a pre-defined set of actions, such methods implicitly assume that the causes of model degradation are irrelevant to what actions should be taken, limiting their ability to select appropriate adaptations. In this paper, we propose an alternative paradigm to overcome these limitations, called self-healing machine learning (SHML). Contrary to previous approaches, SHML autonomously diagnoses the reason for degradation and proposes diagnosis-based corrective actions. We formalize SHML as an optimization problem over a space of adaptation actions to minimize the expected risk under the shifted DGP. We introduce a theoretical framework for self-healing systems and build an agentic self-healing solution H-LLM which uses large language models to perform self-diagnosis by reasoning about the structure underlying the DGP, and self-adaptation by proposing and evaluating corrective actions. Empirically, we analyze different components of H-LLM to understand why and when it works, demonstrating the potential of self-healing ML.
Matchmaker: Self-Improving Large Language Model Programs for Schema Matching
Oct 31, 2024



Schema matching -- the task of finding matches between attributes across disparate data sources with different tables and hierarchies -- is critical for creating interoperable machine learning (ML)-ready data. Addressing this fundamental data-centric problem has wide implications, especially in domains like healthcare, finance and e-commerce -- but also has the potential to benefit ML models more generally, by increasing the data available for ML model training. However, schema matching is a challenging ML task due to structural/hierarchical and semantic heterogeneity between different schemas. Previous ML approaches to automate schema matching have either required significant labeled data for model training, which is often unrealistic or suffer from poor zero-shot performance. To this end, we propose Matchmaker - a compositional language model program for schema matching, comprised of candidate generation, refinement and confidence scoring. Matchmaker also self-improves in a zero-shot manner without the need for labeled demonstrations via a novel optimization approach, which constructs synthetic in-context demonstrations to guide the language model's reasoning process. Empirically, we demonstrate on real-world medical schema matching benchmarks that Matchmaker outperforms previous ML-based approaches, highlighting its potential to accelerate data integration and interoperability of ML-ready data.
You can't handle the truth: Data-centric insights improve pseudo-labeling
Jun 19, 2024



Pseudo-labeling is a popular semi-supervised learning technique to leverage unlabeled data when labeled samples are scarce. The generation and selection of pseudo-labels heavily rely on labeled data. Existing approaches implicitly assume that the labeled data is gold standard and 'perfect'. However, this can be violated in reality with issues such as mislabeling or ambiguity. We address this overlooked aspect and show the importance of investigating labeled data quality to improve any pseudo-labeling method. Specifically, we introduce a novel data characterization and selection framework called DIPS to extend pseudo-labeling. We select useful labeled and pseudo-labeled samples via analysis of learning dynamics. We demonstrate the applicability and impact of DIPS for various pseudo-labeling methods across an extensive range of real-world tabular and image datasets. Additionally, DIPS improves data efficiency and reduces the performance distinctions between different pseudo-labelers. Overall, we highlight the significant benefits of a data-centric rethinking of pseudo-labeling in real-world settings.
Relaxed Quantile Regression: Prediction Intervals for Asymmetric Noise
Jun 05, 2024Constructing valid prediction intervals rather than point estimates is a well-established approach for uncertainty quantification in the regression setting. Models equipped with this capacity output an interval of values in which the ground truth target will fall with some prespecified probability. This is an essential requirement in many real-world applications where simple point predictions' inability to convey the magnitude and frequency of errors renders them insufficient for high-stakes decisions. Quantile regression is a leading approach for obtaining such intervals via the empirical estimation of quantiles in the (non-parametric) distribution of outputs. This method is simple, computationally inexpensive, interpretable, assumption-free, and effective. However, it does require that the specific quantiles being learned are chosen a priori. This results in (a) intervals that are arbitrarily symmetric around the median which is sub-optimal for realistic skewed distributions, or (b) learning an excessive number of intervals. In this work, we propose Relaxed Quantile Regression (RQR), a direct alternative to quantile regression based interval construction that removes this arbitrary constraint whilst maintaining its strengths. We demonstrate that this added flexibility results in intervals with an improvement in desirable qualities (e.g. mean width) whilst retaining the essential coverage guarantees of quantile regression.