 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More, No Less: Least-Privilege Language Models
Jan 30, 2026Least privilege is a core security principle: grant each request only the minimum access needed to achieve its goal. Deployed language models almost never follow it, instead being exposed through a single API endpoint that serves all users and requests. This gap exists not because least privilege would be unhelpful; deployments would benefit greatly from reducing unnecessary capability exposure. The real obstacle is definitional and mechanistic: what does "access" mean inside a language model, and how can we enforce it without retraining or deploying multiple models? We take inspiration from least privilege in computer systems and define a class of models called least-privilege language models, where privilege is reachable internal computation during the forward pass. In this view, lowering privilege literally shrinks the model's accessible function class, as opposed to denying access via learned policies. We formalize deployment-time control as a monitor-allocator-enforcer stack, separating (i) request-time signals, (ii) a decision rule that allocates privilege, and (iii) an inference-time mechanism that selects privilege. We then propose Nested Least-Privilege Networks, a shape-preserving, rank-indexed intervention that provides a smooth, reversible control knob. We show that this knob yields policy-usable privilege-utility frontiers and enables selective suppression of targeted capabilities with limited collateral degradation across various policies. Most importantly, we argue for a new deployment paradigm that challenges the premise that language models can only be controlled at the output level.
Probabilistic Transformers for Joint Modeling of Global Weather Dynamics and Decision-Centric Variables
Jan 07, 2026Weather forecasts sit upstream of high-stakes decisions in domains such as grid operations, aviation, agriculture, and emergency response. Yet forecast users often face a difficult trade-off. Many decision-relevant targets are functionals of the atmospheric state variables, such as extrema, accumulations, and threshold exceedances, rather than state variables themselves. As a result, users must estimate these targets via post-processing, which can be suboptimal and can introduce structural bias. The core issue is that decisions depend on distributions over these functionals that the model is not trained to learn directly. In this work, we introduce GEM-2, a probabilistic transformer that jointly learns global atmospheric dynamics alongside a suite of variables that users directly act upon. Using this training recipe, we show that a lightweight (~275M params) and computationally efficient (~20-100x training speedup relative to state-of-the-art) transformer trained on the CRPS objective can directly outperform operational numerical weather prediction (NWP) models and be competitive with ML models that rely on expensive multi-step diffusion processes or require bespoke multi-stage fine-tuning strategies. We further demonstrate state-of-the-art economic value metrics under decision-theoretic evaluation, stable convergence to climatology at S2S and seasonal timescales, and a surprising insensitivity to many commonly assumed architectural and training design choices.
Visualizing token importance for black-box language models
Dec 12, 2025



We consider the problem of auditing black-box large language models (LLMs) to ensure they behave reliably when deployed in production settings, particularly in high-stakes domains such as legal, medical, and regulatory compliance. Existing approaches for LLM auditing often focus on isolated aspects of model behavior, such as detecting specific biases or evaluating fairness. We are interested in a more general question -- can we understand how the outputs of black-box LLMs depend on each input token? There is a critical need to have such tools in real-world applications that rely on inaccessible API endpoints to language models. However, this is a highly non-trivial problem, as LLMs are stochastic functions (i.e. two outputs will be different by chance), while computing prompt-level gradients to approximate input sensitivity is infeasible. To address this, we propose Distribution-Based Sensitivity Analysis (DBSA), a lightweight model-agnostic procedure to evaluate the sensitivity of the output of a language model for each input token, without making any distributional assumptions about the LLM. DBSA is developed as a practical tool for practitioners, enabling quick, plug-and-play visual exploration of LLMs reliance on specific input tokens. Through illustrative examples, we demonstrate how DBSA can enable users to inspect LLM inputs and find sensitivities that may be overlooked by existing LLM interpretability methods.
Statistical Hypothesis Testing for Auditing Robustness in Language Models
Jun 09, 2025Consider the problem of testing whether the outputs of a large language model (LLM) system change under an arbitrary intervention, such as an input perturbation or changing the model variant. We cannot simply compare two LLM outputs since they might differ due to the stochastic nature of the system, nor can we compare the entire output distribution due to computational intractability. While existing methods for analyzing text-based outputs exist, they focus on fundamentally different problems, such as measuring bias or fairness. To this end, we introduce distribution-based perturbation analysis, a framework that reformulates LLM perturbation analysis as a frequentist hypothesis testing problem. We construct empirical null and alternative output distributions within a low-dimensional semantic similarity space via Monte Carlo sampling, enabling tractable inference without restrictive distributional assumptions. The framework is (i) model-agnostic, (ii) supports the evaluation of arbitrary input perturbations on any black-box LLM, (iii) yields interpretable p-values; (iv) supports multiple perturbations via controlled error rates; and (v) provides scalar effect sizes. We demonstrate the usefulness of the framework across multiple case studies, showing how we can quantify response changes, measure true/false positive rates, and evaluate alignment with reference models. Above all, we see this as a reliable frequentist hypothesis testing framework for LLM auditing.
* arXiv admin note: substantial text overlap with arXiv:2412.00868
Quantifying perturbation impacts for large language models
Dec 01, 2024



We consider the problem of quantifying how an input perturbation impacts the outputs of large language models (LLMs), a fundamental task for model reliability and post-hoc interpretability. A key obstacle in this domain is disentangling the meaningful changes in model responses from the intrinsic stochasticity of LLM outputs. To overcome this, we introduce Distribution-Based Perturbation Analysis (DBPA), a framework that reformulates LLM perturbation analysis as a frequentist hypothesis testing problem. DBPA constructs empirical null and alternative output distributions within a low-dimensional semantic similarity space via Monte Carlo sampling. Comparisons of Monte Carlo estimates in the reduced dimensionality space enables tractable frequentist inference without relying on restrictive distributional assumptions. The framework is model-agnostic, supports the evaluation of arbitrary input perturbations on any black-box LLM, yields interpretable p-values, supports multiple perturbation testing via controlled error rates, and provides scalar effect sizes for any chosen similarity or distance metric. We demonstrate the effectiveness of DBPA in evaluating perturbation impacts, showing its versatility for perturbation analysis.
Self-Healing Machine Learning: A Framework for Autonomous Adaptation in Real-World Environments
Oct 31, 2024Real-world machine learning systems often encounter model performance degradation due to distributional shifts in the underlying data generating process (DGP). Existing approaches to addressing shifts, such as concept drift adaptation, are limited by their reason-agnostic nature. By choosing from a pre-defined set of actions, such methods implicitly assume that the causes of model degradation are irrelevant to what actions should be taken, limiting their ability to select appropriate adaptations. In this paper, we propose an alternative paradigm to overcome these limitations, called self-healing machine learning (SHML). Contrary to previous approaches, SHML autonomously diagnoses the reason for degradation and proposes diagnosis-based corrective actions. We formalize SHML as an optimization problem over a space of adaptation actions to minimize the expected risk under the shifted DGP. We introduce a theoretical framework for self-healing systems and build an agentic self-healing solution H-LLM which uses large language models to perform self-diagnosis by reasoning about the structure underlying the DGP, and self-adaptation by proposing and evaluating corrective actions. Empirically, we analyze different components of H-LLM to understand why and when it works, demonstrating the potential of self-healing ML.
Context-Aware Testing: A New Paradigm for Model Testing with Large Language Models
Oct 31, 2024



The predominant de facto paradigm of testing ML models relies on either using only held-out data to compute aggregate evaluation metrics or by assessing the performance on different subgroups. However, such data-only testing methods operate under the restrictive assumption that the available empirical data is the sole input for testing ML models, disregarding valuable contextual information that could guide model testing. In this paper, we challenge the go-to approach of data-only testing and introduce context-aware testing (CAT) which uses context as an inductive bias to guide the search for meaningful model failures. We instantiate the first CAT system, SMART Testing, which employs large language models to hypothesize relevant and likely failures, which are evaluated on data using a self-falsification mechanism. Through empirical evaluations in diverse settings, we show that SMART automatically identifies more relevant and impactful failures than alternatives, demonstrating the potential of CAT as a testing paradigm.
Redefining Digital Health Interfaces with Large Language Models
Oct 05, 2023Digital health tools have the potential to significantly improve the delivery of healthcare services. However, their use remains comparatively limited due, in part, to challenges surrounding usability and trust. Recently, Large Language Models (LLMs) have emerged as general-purpose models with the ability to process complex information and produce human-quality text, presenting a wealth of potential applications in healthcare. Directly applying LLMs in clinical settings is not straightforward, with LLMs susceptible to providing inconsistent or nonsensical answers. We demonstrate how LLMs can utilize external tools to provide a novel interface between clinicians and digital technologies. This enhances the utility and practical impact of digital healthcare tools and AI models while addressing current issues with using LLM in clinical settings such as hallucinations. We illustrate our approach with examples from cardiovascular disease and diabetes risk prediction, highlighting the benefit compared to traditional interfaces for digital tools.
Memes in the Wild: Assessing the Generalizability of the Hateful Memes Challenge Dataset
Jul 09, 2021

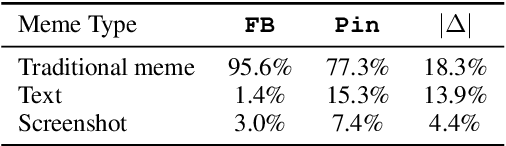

Hateful memes pose a unique challenge for current machine learning systems because their message is derived from both text- and visual-modalities. To this effect, Facebook released the Hateful Memes Challenge, a dataset of memes with pre-extracted text captions, but it is unclear whether these synthetic examples generalize to `memes in the wild'. In this paper, we collect hateful and non-hateful memes from Pinterest to evaluate out-of-sample performance on models pre-trained on the Facebook dataset. We find that memes in the wild differ in two key aspects: 1) Captions must be extracted via OCR, injecting noise and diminishing performance of multimodal models, and 2) Memes are more diverse than `traditional memes', including screenshots of conversations or text on a plain background. This paper thus serves as a reality check for the current benchmark of hateful meme detection and its applicability for detecting real world hate.