 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Video Models into Generalist Robot Policies
May 27, 2026Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex tasks across embodiments and environments. Recent work proposes robot foundation models that jointly predict future observations and actions by finetuning video models with action-labeled data. In this paper, we test the limits of an alternative approach: leave the video planner as-is while training an embodiment-specific inverse dynamics model (IDM). This decoupling offers several natural benefits: the video planner remains embodiment-agnostic, different video models can be interchanged easily without re-training the IDM, and the IDM can be independently trained with readily available self-play data. We present a closed-loop, video-to-action policy that combines an action-free video world model with a carefully-designed IDM based on the robot embodiment Jacobian. We demonstrate that our IDM design is both data-efficient and scalable to high-dimensional action spaces. Our policy, which we coin the Video-to-Embodied Robot Action Model (VERA), achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video planner can be used across multiple embodiments by pairing it with different embodiment-specific IDMs. Our results show that decoupled video planning plus faithful video-to-action translation is a viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control. More results are available on our project website: https://vera.csail.mit.edu.
End-to-End Training for Unified Tokenization and Latent Denoising
Mar 23, 2026Latent diffusion models (LDMs) enable high-fidelity synthesis by operating in learned latent spaces. However, training state-of-the-art LDMs requires complex staging: a tokenizer must be trained first, before the diffusion model can be trained in the frozen latent space. We propose UNITE - an autoencoder architecture for unified tokenization and latent diffusion. UNITE consists of a Generative Encoder that serves as both image tokenizer and latent generator via weight sharing. Our key insight is that tokenization and generation can be viewed as the same latent inference problem under different conditioning regimes: tokenization infers latents from fully observed images, whereas generation infers them from noise together with text or class conditioning. Motivated by this, we introduce a single-stage training procedure that jointly optimizes both tasks via two forward passes through the same Generative Encoder. The shared parameters enable gradients to jointly shape the latent space, encouraging a "common latent language". Across image and molecule modalities, UNITE achieves near state of the art performance without adversarial losses or pretrained encoders (e.g., DINO), reaching FID 2.12 and 1.73 for Base and Large models on ImageNet 256 x 256. We further analyze the Generative Encoder through the lenses of representation alignment and compression. These results show that single stage joint training of tokenization & generation from scratch is feasible.
Causality in Video Diffusers is Separable from Denoising
Feb 10, 2026Causality -- referring to temporal, uni-directional cause-effect relationships between components -- underlies many complex generative processes, including videos, language, and robot trajectories. Current causal diffusion models entangle temporal reasoning with iterative denoising, applying causal attention across all layers, at every denoising step, and over the entire context. In this paper, we show that the causal reasoning in these models is separable from the multi-step denoising process. Through systematic probing of autoregressive video diffusers, we uncover two key regularities: (1) early layers produce highly similar features across denoising steps, indicating redundant computation along the diffusion trajectory; and (2) deeper layers exhibit sparse cross-frame attention and primarily perform intra-frame rendering. Motivated by these findings, we introduce Separable Causal Diffusion (SCD), a new architecture that explicitly decouples once-per-frame temporal reasoning, via a causal transformer encoder, from multi-step frame-wise rendering, via a lightweight diffusion decoder. Extensive experiments on both pretraining and post-training tasks across synthetic and real benchmarks show that SCD significantly improves throughput and per-frame latency while matching or surpassing the generation quality of strong causal diffusion baselines.
Mean Flows for One-step Generative Modeling
May 19, 2025We propose a principled and effective framework for one-step generative modeling. We introduce the notion of average velocity to characterize flow fields, in contrast to instantaneous velocity modeled by Flow Matching methods. A well-defined identity between average and instantaneous velocities is derived and used to guide neural network training. Our method, termed the MeanFlow model, is self-contained and requires no pre-training, distillation, or curriculum learning. MeanFlow demonstrates strong empirical performance: it achieves an FID of 3.43 with a single function evaluation (1-NFE) on ImageNet 256x256 trained from scratch, significantly outperforming previous state-of-the-art one-step diffusion/flow models. Our study substantially narrows the gap between one-step diffusion/flow models and their multi-step predecessors, and we hope it will motivate future research to revisit the foundations of these powerful models.
Wasserstein distributional adversarial training for deep neural networks
Feb 13, 2025Design of adversarial attacks for deep neural networks, as well as methods of adversarial training against them, are subject of intense research. In this paper, we propose methods to train against distributional attack threats, extending the TRADES method used for pointwise attacks. Our approach leverages recent contributions and relies on sensitivity analysis for Wasserstein distributionally robust optimization problems. We introduce an efficient fine-tuning method which can be deployed on a previously trained model. We test our methods on a range of pre-trained models on RobustBench. These experimental results demonstrate the additional training enhances Wasserstein distributional robustness, while maintaining original levels of pointwise robustness, even for already very successful networks. The improvements are less marked for models pre-trained using huge synthetic datasets of 20-100M images. However, remarkably, sometimes our methods are still able to improve their performance even when trained using only the original training dataset (50k images).
Fixed Point Diffusion Models
Jan 16, 2024
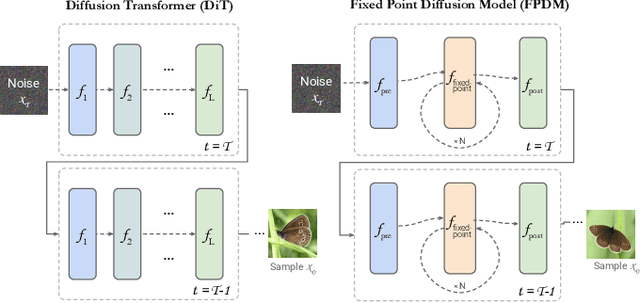

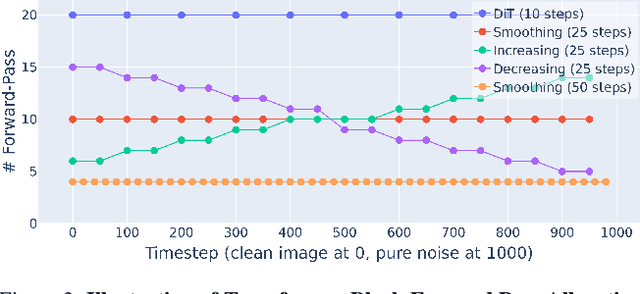
We introduce the Fixed Point Diffusion Model (FPDM), a novel approach to image generation that integrates the concept of fixed point solving into the framework of diffusion-based generative modeling. Our approach embeds an implicit fixed point solving layer into the denoising network of a diffusion model, transforming the diffusion process into a sequence of closely-related fixed point problems. Combined with a new stochastic training method, this approach significantly reduces model size, reduces memory usage, and accelerates training. Moreover, it enables the development of two new techniques to improve sampling efficiency: reallocating computation across timesteps and reusing fixed point solutions between timesteps. We conduct extensive experiments with state-of-the-art models on ImageNet, FFHQ, CelebA-HQ, and LSUN-Church, demonstrating substantial improvements in performance and efficiency. Compared to the state-of-the-art DiT model, FPDM contains 87% fewer parameters, consumes 60% less memory during training, and improves image generation quality in situations where sampling computation or time is limited. Our code and pretrained models are available at https://lukemelas.github.io/fixed-point-diffusion-models.
Sorting with Predictions
Nov 01, 2023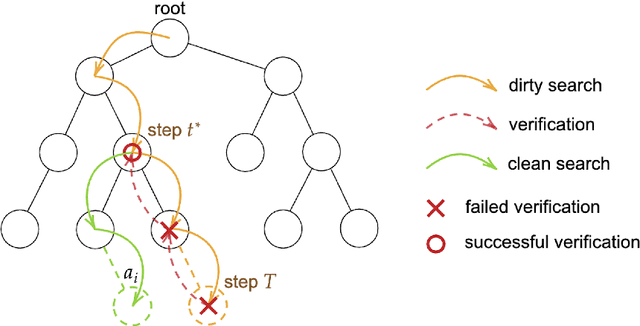
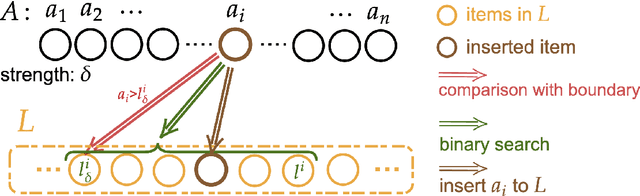

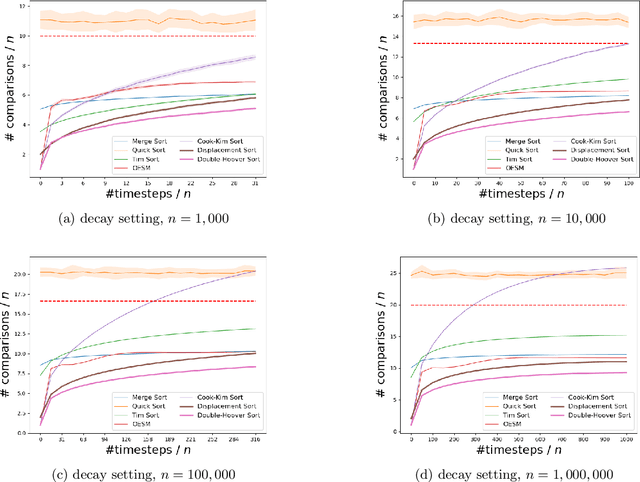
We explore the fundamental problem of sorting through the lens of learning-augmented algorithms, where algorithms can leverage possibly erroneous predictions to improve their efficiency. We consider two different settings: In the first setting, each item is provided a prediction of its position in the sorted list. In the second setting, we assume there is a "quick-and-dirty" way of comparing items, in addition to slow-and-exact comparisons. For both settings, we design new and simple algorithms using only $O(\sum_i \log \eta_i)$ exact comparisons, where $\eta_i$ is a suitably defined prediction error for the $i$th element. In particular, as the quality of predictions deteriorates, the number of comparisons degrades smoothly from $O(n)$ to $O(n\log n)$. We prove that the comparison complexity is theoretically optimal with respect to the examined error measures. An experimental evaluation against existing adaptive and non-adaptive sorting algorithms demonstrates the potential of applying learning-augmented algorithms in sorting tasks.
Goodhart's Law in Reinforcement Learning
Oct 13, 2023



Implementing a reward function that perfectly captures a complex task in the real world is impractical. As a result, it is often appropriate to think of the reward function as a proxy for the true objective rather than as its definition. We study this phenomenon through the lens of Goodhart's law, which predicts that increasing optimisation of an imperfect proxy beyond some critical point decreases performance on the true objective. First, we propose a way to quantify the magnitude of this effect and show empirically that optimising an imperfect proxy reward often leads to the behaviour predicted by Goodhart's law for a wide range of environments and reward functions. We then provide a geometric explanation for why Goodhart's law occurs in Markov decision processes. We use these theoretical insights to propose an optimal early stopping method that provably avoids the aforementioned pitfall and derive theoretical regret bounds for this method. Moreover, we derive a training method that maximises worst-case reward, for the setting where there is uncertainty about the true reward function. Finally, we evaluate our early stopping method experimentally. Our results support a foundation for a theoretically-principled study of reinforcement learning under reward misspecification.
Wasserstein distributional robustness of neural networks
Jun 16, 2023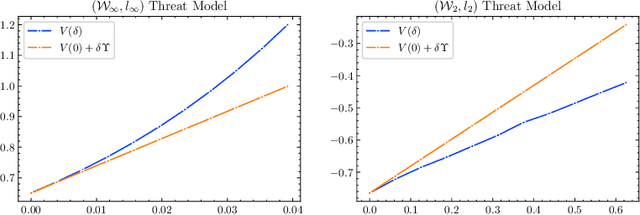

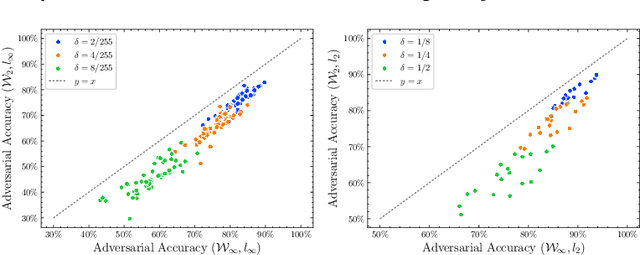

Deep neural networks are known to be vulnerable to adversarial attacks (AA). For an image recognition task, this means that a small perturbation of the original can result in the image being misclassified. Design of such attacks as well as methods of adversarial training against them are subject of intense research. We re-cast the problem using techniques of Wasserstein distributionally robust optimization (DRO) and obtain novel contributions leveraging recent insights from DRO sensitivity analysis. We consider a set of distributional threat models. Unlike the traditional pointwise attacks, which assume a uniform bound on perturbation of each input data point, distributional threat models allow attackers to perturb inputs in a non-uniform way. We link these more general attacks with questions of out-of-sample performance and Knightian uncertainty. To evaluate the distributional robustness of neural networks, we propose a first-order AA algorithm and its multi-step version. Our attack algorithms include Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) as special cases. Furthermore, we provide a new asymptotic estimate of the adversarial accuracy against distributional threat models. The bound is fast to compute and first-order accurate, offering new insights even for the pointwise AA. It also naturally yields out-of-sample performance guarantees. We conduct numerical experiments on the CIFAR-10 dataset using DNNs on RobustBench to illustrate our theoretical results. Our code is available at https://github.com/JanObloj/W-DRO-Adversarial-Methods.
Memes in the Wild: Assessing the Generalizability of the Hateful Memes Challenge Dataset
Jul 09, 2021

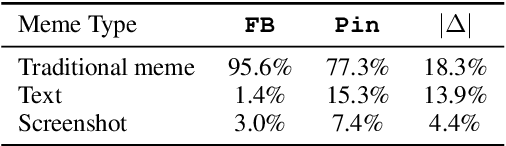

Hateful memes pose a unique challenge for current machine learning systems because their message is derived from both text- and visual-modalities. To this effect, Facebook released the Hateful Memes Challenge, a dataset of memes with pre-extracted text captions, but it is unclear whether these synthetic examples generalize to `memes in the wild'. In this paper, we collect hateful and non-hateful memes from Pinterest to evaluate out-of-sample performance on models pre-trained on the Facebook dataset. We find that memes in the wild differ in two key aspects: 1) Captions must be extracted via OCR, injecting noise and diminishing performance of multimodal models, and 2) Memes are more diverse than `traditional memes', including screenshots of conversations or text on a plain background. This paper thus serves as a reality check for the current benchmark of hateful meme detection and its applicability for detecting real world hate.