 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the ATE: Interpretable Modelling of Treatment Effects over Dose and Time
Jul 09, 2025The Average Treatment Effect (ATE) is a foundational metric in causal inference, widely used to assess intervention efficacy in randomized controlled trials (RCTs). However, in many applications -- particularly in healthcare -- this static summary fails to capture the nuanced dynamics of treatment effects that vary with both dose and time. We propose a framework for modelling treatment effect trajectories as smooth surfaces over dose and time, enabling the extraction of clinically actionable insights such as onset time, peak effect, and duration of benefit. To ensure interpretability, robustness, and verifiability -- key requirements in high-stakes domains -- we adapt SemanticODE, a recent framework for interpretable trajectory modelling, to the causal setting where treatment effects are never directly observed. Our approach decouples the estimation of trajectory shape from the specification of clinically relevant properties (e.g., maxima, inflection points), supporting domain-informed priors, post-hoc editing, and transparent analysis. We show that our method yields accurate, interpretable, and editable models of treatment dynamics, facilitating both rigorous causal analysis and practical decision-making.
Revolutionizing Clinical Trials: A Manifesto for AI-Driven Transformation
Jun 10, 2025This manifesto represents a collaborative vision forged by leaders in pharmaceuticals, consulting firms, clinical research, and AI. It outlines a roadmap for two AI technologies - causal inference and digital twins - to transform clinical trials, delivering faster, safer, and more personalized outcomes for patients. By focusing on actionable integration within existing regulatory frameworks, we propose a way forward to revolutionize clinical research and redefine the gold standard for clinical trials using AI.
No Equations Needed: Learning System Dynamics Without Relying on Closed-Form ODEs
Jan 30, 2025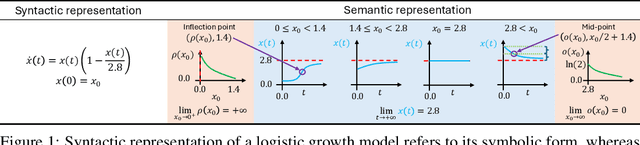

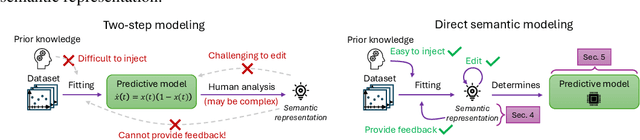

Data-driven modeling of dynamical systems is a crucial area of machine learning. In many scenarios, a thorough understanding of the model's behavior becomes essential for practical applications. For instance, understanding the behavior of a pharmacokinetic model, constructed as part of drug development, may allow us to both verify its biological plausibility (e.g., the drug concentration curve is non-negative and decays to zero) and to design dosing guidelines. Discovery of closed-form ordinary differential equations (ODEs) can be employed to obtain such insights by finding a compact mathematical equation and then analyzing it (a two-step approach). However, its widespread use is currently hindered because the analysis process may be time-consuming, requiring substantial mathematical expertise, or even impossible if the equation is too complex. Moreover, if the found equation's behavior does not satisfy the requirements, editing it or influencing the discovery algorithms to rectify it is challenging as the link between the symbolic form of an ODE and its behavior can be elusive. This paper proposes a conceptual shift to modeling low-dimensional dynamical systems by departing from the traditional two-step modeling process. Instead of first discovering a closed-form equation and then analyzing it, our approach, direct semantic modeling, predicts the semantic representation of the dynamical system (i.e., description of its behavior) directly from data, bypassing the need for complex post-hoc analysis. This direct approach also allows the incorporation of intuitive inductive biases into the optimization algorithm and editing the model's behavior directly, ensuring that the model meets the desired specifications. Our approach not only simplifies the modeling pipeline but also enhances the transparency and flexibility of the resulting models compared to traditional closed-form ODEs.
Self-Healing Machine Learning: A Framework for Autonomous Adaptation in Real-World Environments
Oct 31, 2024Real-world machine learning systems often encounter model performance degradation due to distributional shifts in the underlying data generating process (DGP). Existing approaches to addressing shifts, such as concept drift adaptation, are limited by their reason-agnostic nature. By choosing from a pre-defined set of actions, such methods implicitly assume that the causes of model degradation are irrelevant to what actions should be taken, limiting their ability to select appropriate adaptations. In this paper, we propose an alternative paradigm to overcome these limitations, called self-healing machine learning (SHML). Contrary to previous approaches, SHML autonomously diagnoses the reason for degradation and proposes diagnosis-based corrective actions. We formalize SHML as an optimization problem over a space of adaptation actions to minimize the expected risk under the shifted DGP. We introduce a theoretical framework for self-healing systems and build an agentic self-healing solution H-LLM which uses large language models to perform self-diagnosis by reasoning about the structure underlying the DGP, and self-adaptation by proposing and evaluating corrective actions. Empirically, we analyze different components of H-LLM to understand why and when it works, demonstrating the potential of self-healing ML.
Shape Arithmetic Expressions: Advancing Scientific Discovery Beyond Closed-Form Equations
Apr 15, 2024Symbolic regression has excelled in uncovering equations from physics, chemistry, biology, and related disciplines. However, its effectiveness becomes less certain when applied to experimental data lacking inherent closed-form expressions. Empirically derived relationships, such as entire stress-strain curves, may defy concise closed-form representation, compelling us to explore more adaptive modeling approaches that balance flexibility with interpretability. In our pursuit, we turn to Generalized Additive Models (GAMs), a widely used class of models known for their versatility across various domains. Although GAMs can capture non-linear relationships between variables and targets, they cannot capture intricate feature interactions. In this work, we investigate both of these challenges and propose a novel class of models, Shape Arithmetic Expressions (SHAREs), that fuses GAM's flexible shape functions with the complex feature interactions found in mathematical expressions. SHAREs also provide a unifying framework for both of these approaches. We also design a set of rules for constructing SHAREs that guarantee transparency of the found expressions beyond the standard constraints based on the model's size.
ODE Discovery for Longitudinal Heterogeneous Treatment Effects Inference
Mar 16, 2024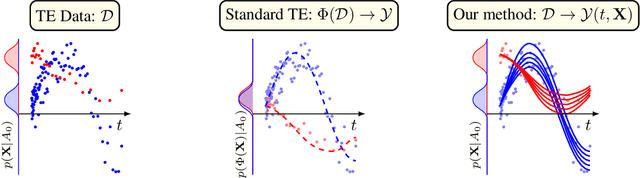

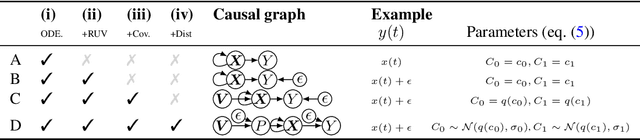
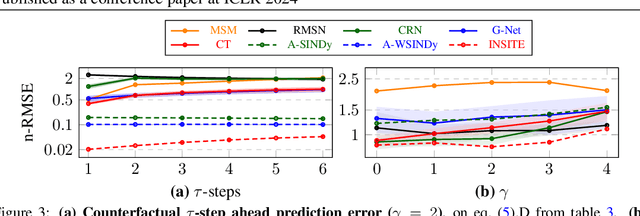
Inferring unbiased treatment effects has received widespread attention in the machine learning community. In recent years, our community has proposed numerous solutions in standard settings, high-dimensional treatment settings, and even longitudinal settings. While very diverse, the solution has mostly relied on neural networks for inference and simultaneous correction of assignment bias. New approaches typically build on top of previous approaches by proposing new (or refined) architectures and learning algorithms. However, the end result -- a neural-network-based inference machine -- remains unchallenged. In this paper, we introduce a different type of solution in the longitudinal setting: a closed-form ordinary differential equation (ODE). While we still rely on continuous optimization to learn an ODE, the resulting inference machine is no longer a neural network. Doing so yields several advantages such as interpretability, irregular sampling, and a different set of identification assumptions. Above all, we consider the introduction of a completely new type of solution to be our most important contribution as it may spark entirely new innovations in treatment effects in general. We facilitate this by formulating our contribution as a framework that can transform any ODE discovery method into a treatment effects method.
Causal Deep Learning
Mar 03, 2023



Causality has the potential to truly transform the way we solve a large number of real-world problems. Yet, so far, its potential remains largely unlocked since most work so far requires strict assumptions which do not hold true in practice. To address this challenge and make progress in solving real-world problems, we propose a new way of thinking about causality - we call this causal deep learning. The framework which we propose for causal deep learning spans three dimensions: (1) a structural dimension, which allows incomplete causal knowledge rather than assuming either full or no causal knowledge; (2) a parametric dimension, which encompasses parametric forms which are typically ignored; and finally, (3) a temporal dimension, which explicitly allows for situations which capture exposure times or temporal structure. Together, these dimensions allow us to make progress on a variety of real-world problems by leveraging (sometimes incomplete) causal knowledge and/or combining diverse causal deep learning methods. This new framework also enables researchers to compare systematically across existing works as well as identify promising research areas which can lead to real-world impact.
Navigating causal deep learning
Dec 01, 2022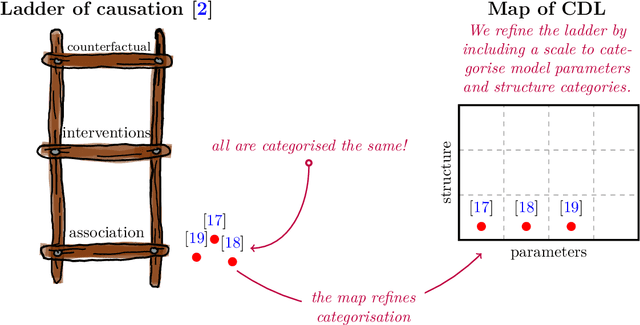
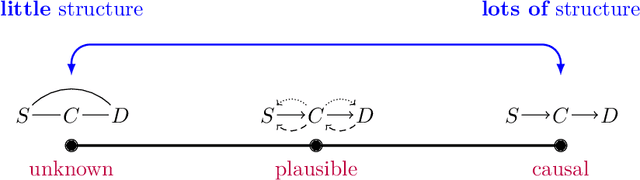
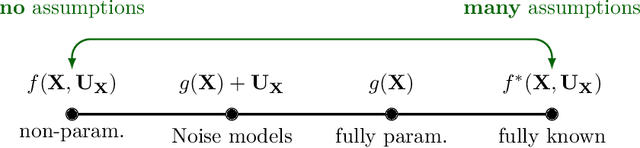
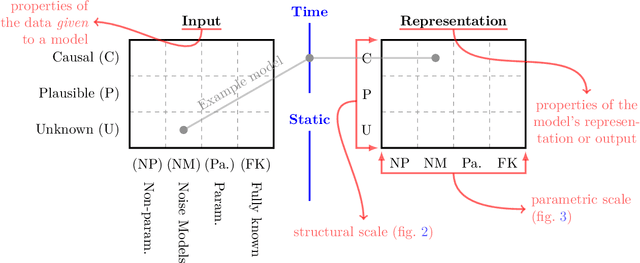
Causal deep learning (CDL) is a new and important research area in the larger field of machine learning. With CDL, researchers aim to structure and encode causal knowledge in the extremely flexible representation space of deep learning models. Doing so will lead to more informed, robust, and general predictions and inference -- which is important! However, CDL is still in its infancy. For example, it is not clear how we ought to compare different methods as they are so different in their output, the way they encode causal knowledge, or even how they represent this knowledge. This is a living paper that categorises methods in causal deep learning beyond Pearl's ladder of causation. We refine the rungs in Pearl's ladder, while also adding a separate dimension that categorises the parametric assumptions of both input and representation, arriving at the map of causal deep learning. Our map covers machine learning disciplines such as supervised learning, reinforcement learning, generative modelling and beyond. Our paradigm is a tool which helps researchers to: find benchmarks, compare methods, and most importantly: identify research gaps. With this work we aim to structure the avalanche of papers being published on causal deep learning. While papers on the topic are being published daily, our map remains fixed. We open-source our map for others to use as they see fit: perhaps to offer guidance in a related works section, or to better highlight the contribution of their paper.
D-CIPHER: Discovery of Closed-form PDEs
Jun 21, 2022

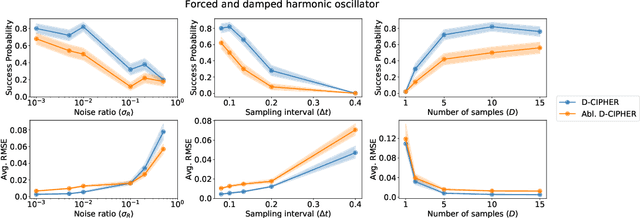

Closed-form differential equations, including partial differential equations and higher-order ordinary differential equations, are one of the most important tools used by scientists to model and better understand natural phenomena. Discovering these equations directly from data is challenging because it requires modeling relationships between various derivatives that are not observed in the data (\textit{equation-data mismatch}) and it involves searching across a huge space of possible equations. Current approaches make strong assumptions about the form of the equation and thus fail to discover many well-known systems. Moreover, many of them resolve the equation-data mismatch by estimating the derivatives, which makes them inadequate for noisy and infrequently sampled systems. To this end, we propose D-CIPHER, which is robust to measurement artifacts and can uncover a new and very general class of differential equations. We further design a novel optimization procedure, CoLLie, to help D-CIPHER search through this class efficiently. Finally, we demonstrate empirically that it can discover many well-known equations that are beyond the capabilities of current methods.
Privacy-preserving Object Detection
Mar 11, 2021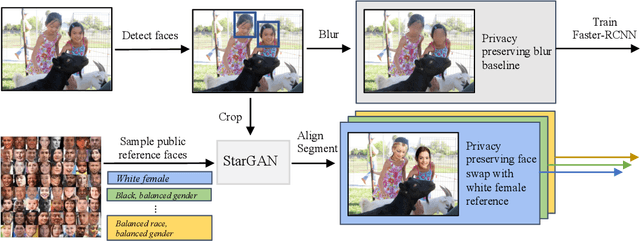
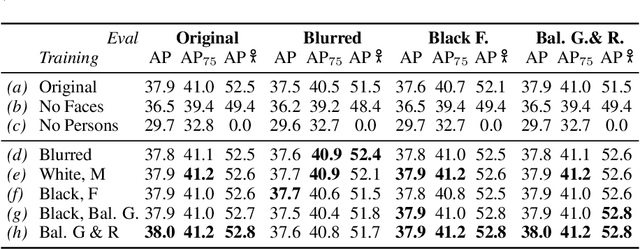

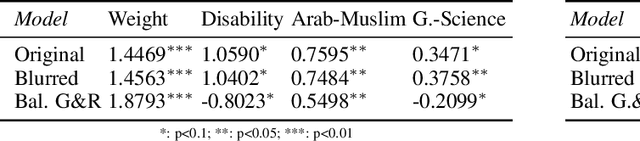
Privacy considerations and bias in datasets are quickly becoming high-priority issues that the computer vision community needs to face. So far, little attention has been given to practical solutions that do not involve collection of new datasets. In this work, we show that for object detection on COCO, both anonymizing the dataset by blurring faces, as well as swapping faces in a balanced manner along the gender and skin tone dimension, can retain object detection performances while preserving privacy and partially balancing bias.