 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Zero-Shot Time Series Foundation Models on Cloud Data
Feb 18, 2025Time series foundation models (FMs) have emerged as a popular paradigm for zero-shot multi-domain forecasting. FMs are trained on numerous diverse datasets and claim to be effective forecasters across multiple different time series domains, including cloud data. In this work we investigate this claim, exploring the effectiveness of FMs on cloud data. We demonstrate that many well-known FMs fail to generate meaningful or accurate zero-shot forecasts in this setting. We support this claim empirically, showing that FMs are outperformed consistently by simple linear baselines. We also illustrate a number of interesting pathologies, including instances where FMs suddenly output seemingly erratic, random-looking forecasts. Our results suggest a widespread failure of FMs to model cloud data.
DAM: Towards A Foundation Model for Time Series Forecasting
Jul 25, 2024It is challenging to scale time series forecasting models such that they forecast accurately for multiple distinct domains and datasets, all with potentially different underlying collection procedures (e.g., sample resolution), patterns (e.g., periodicity), and prediction requirements (e.g., reconstruction vs. forecasting). We call this general task universal forecasting. Existing methods usually assume that input data is regularly sampled, and they forecast to pre-determined horizons, resulting in failure to generalise outside of the scope of their training. We propose the DAM - a neural model that takes randomly sampled histories and outputs an adjustable basis composition as a continuous function of time for forecasting to non-fixed horizons. It involves three key components: (1) a flexible approach for using randomly sampled histories from a long-tail distribution, that enables an efficient global perspective of the underlying temporal dynamics while retaining focus on the recent history; (2) a transformer backbone that is trained on these actively sampled histories to produce, as representational output, (3) the basis coefficients of a continuous function of time. We show that a single univariate DAM, trained on 25 time series datasets, either outperformed or closely matched existing SoTA models at multivariate long-term forecasting across 18 datasets, including 8 held-out for zero-shot transfer, even though these models were trained to specialise for each dataset-horizon combination. This single DAM excels at zero-shot transfer and very-long-term forecasting, performs well at imputation, is interpretable via basis function composition and attention, can be tuned for different inference-cost requirements, is robust to missing and irregularly sampled data {by design}.
How Does It Function? Characterizing Long-term Trends in Production Serverless Workloads
Dec 15, 2023This paper releases and analyzes two new Huawei cloud serverless traces. The traces span a period of over 7 months with over 1.4 trillion function invocations combined. The first trace is derived from Huawei's internal workloads and contains detailed per-second statistics for 200 functions running across multiple Huawei cloud data centers. The second trace is a representative workload from Huawei's public FaaS platform. This trace contains per-minute arrival rates for over 5000 functions running in a single Huawei data center. We present the internals of a production FaaS platform by characterizing resource consumption, cold-start times, programming languages used, periodicity, per-second versus per-minute burstiness, correlations, and popularity. Our findings show that there is considerable diversity in how serverless functions behave: requests vary by up to 9 orders of magnitude across functions, with some functions executed over 1 billion times per day; scheduling time, execution time and cold-start distributions vary across 2 to 4 orders of magnitude and have very long tails; and function invocation counts demonstrate strong periodicity for many individual functions and on an aggregate level. Our analysis also highlights the need for further research in estimating resource reservations and time-series prediction to account for the huge diversity in how serverless functions behave. Datasets and code available at https://github.com/sir-lab/data-release
Privacy-preserving Object Detection
Mar 11, 2021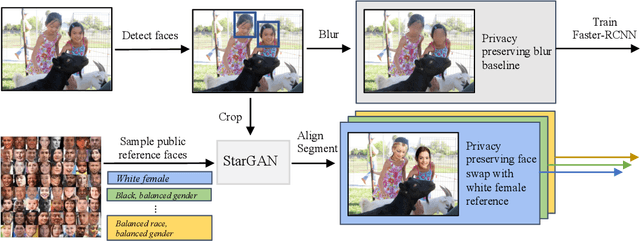
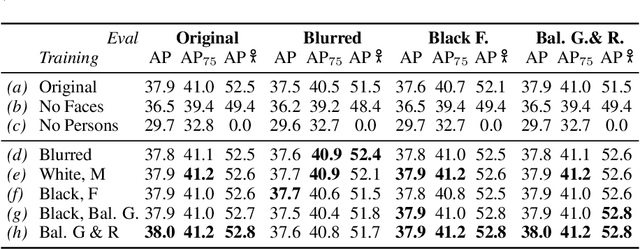

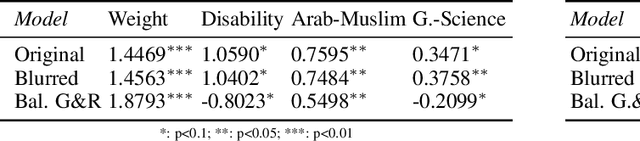
Privacy considerations and bias in datasets are quickly becoming high-priority issues that the computer vision community needs to face. So far, little attention has been given to practical solutions that do not involve collection of new datasets. In this work, we show that for object detection on COCO, both anonymizing the dataset by blurring faces, as well as swapping faces in a balanced manner along the gender and skin tone dimension, can retain object detection performances while preserving privacy and partially balancing bias.