 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified Multi-Agent Orchestration: A Plan-Execute-Verify-Replan Framework for Complex Query Resolution
Mar 12, 2026We present Verified Multi-Agent Orchestration (VMAO), a framework that coordinates specialized LLM-based agents through a verification-driven iterative loop. Given a complex query, our system decomposes it into a directed acyclic graph (DAG) of sub-questions, executes them through domain-specific agents in parallel, verifies result completeness via LLM-based evaluation, and adaptively replans to address gaps. The key contributions are: (1) dependency-aware parallel execution over a DAG of sub-questions with automatic context propagation, (2) verification-driven adaptive replanning that uses an LLM-based verifier as an orchestration-level coordination signal, and (3) configurable stop conditions that balance answer quality against resource usage. On 25 expert-curated market research queries, VMAO improves answer completeness from 3.1 to 4.2 and source quality from 2.6 to 4.1 (1-5 scale) compared to a single-agent baseline, demonstrating that orchestration-level verification is an effective mechanism for multi-agent quality assurance.
OpenVIS: Open-vocabulary Video Instance Segmentation
May 26, 2023



We propose and study a new computer vision task named open-vocabulary video instance segmentation (OpenVIS), which aims to simultaneously segment, detect, and track arbitrary objects in a video according to corresponding text descriptions. Compared to the original video instance segmentation, OpenVIS enables users to identify objects of desired categories, regardless of whether those categories were included in the training dataset. To achieve this goal, we propose a two-stage pipeline for proposing high-quality class-agnostic object masks and predicting their corresponding categories via pre-trained VLM. Specifically, we first employ a query-based mask proposal network to generate masks of all potential objects, where we replace the original class head with an instance head trained with a binary object loss, thereby enhancing the class-agnostic mask proposal ability. Then, we introduce a proposal post-processing approach to adapt the proposals better to the pre-trained VLMs, avoiding distortion and unnatural proposal inputs. Meanwhile, to facilitate research on this new task, we also propose an evaluation benchmark that utilizes off-the-shelf datasets to comprehensively assess its performance. Experimentally, the proposed OpenVIS exhibits a remarkable 148\% improvement compared to the full-supervised baselines on BURST, which have been trained on all categories.
SelfGait: A Spatiotemporal Representation Learning Method for Self-supervised Gait Recognition
Mar 27, 2021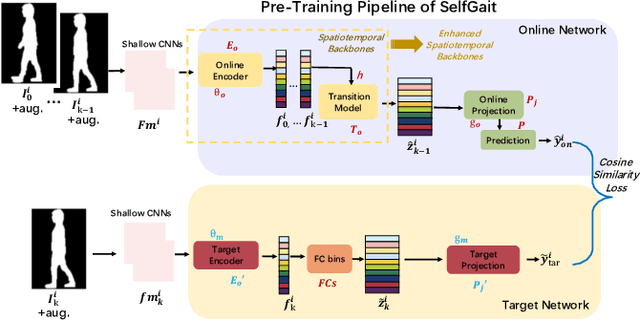
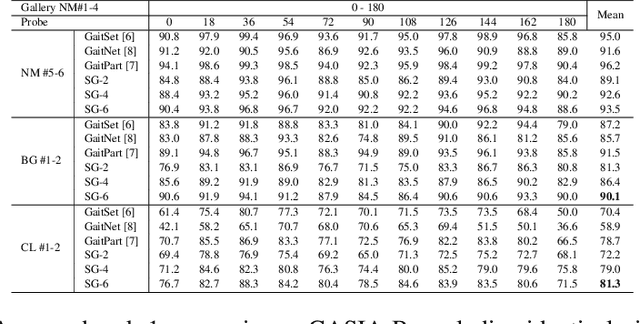
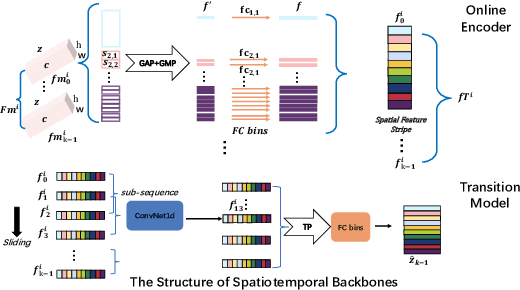

Gait recognition plays a vital role in human identification since gait is a unique biometric feature that can be perceived at a distance. Although existing gait recognition methods can learn gait features from gait sequences in different ways, the performance of gait recognition suffers from insufficient labeled data, especially in some practical scenarios associated with short gait sequences or various clothing styles. It is unpractical to label the numerous gait data. In this work, we propose a self-supervised gait recognition method, termed SelfGait, which takes advantage of the massive, diverse, unlabeled gait data as a pre-training process to improve the representation abilities of spatiotemporal backbones. Specifically, we employ the horizontal pyramid mapping (HPM) and micro-motion template builder (MTB) as our spatiotemporal backbones to capture the multi-scale spatiotemporal representations. Experiments on CASIA-B and OU-MVLP benchmark gait datasets demonstrate the effectiveness of the proposed SelfGait compared with four state-of-the-art gait recognition methods. The source code has been released at https://github.com/EchoItLiu/SelfGait.
Privacy-preserving Object Detection
Mar 11, 2021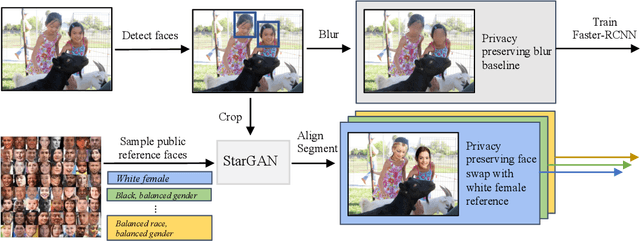
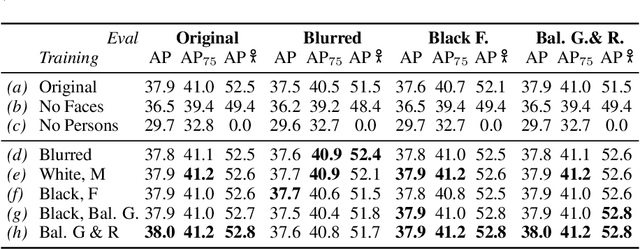

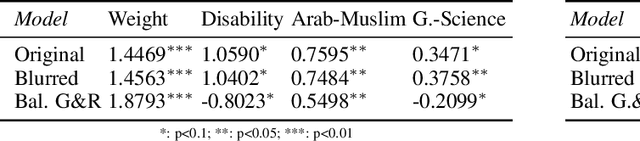
Privacy considerations and bias in datasets are quickly becoming high-priority issues that the computer vision community needs to face. So far, little attention has been given to practical solutions that do not involve collection of new datasets. In this work, we show that for object detection on COCO, both anonymizing the dataset by blurring faces, as well as swapping faces in a balanced manner along the gender and skin tone dimension, can retain object detection performances while preserving privacy and partially balancing bias.