 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Score: Tuning Cluster Schedulers through Reinforcement Learning
Mar 11, 2026Efficiently allocating incoming jobs to nodes in large-scale clusters can lead to substantial improvements in both cluster utilization and job performance. In order to allocate incoming jobs, cluster schedulers usually rely on a set of scoring functions to rank feasible nodes. Results from individual scoring functions are usually weighted equally, which could lead to sub-optimal deployments as the one-size-fits-all solution does not take into account the characteristics of each workload. Tuning the weights of scoring functions, however, requires expert knowledge and is computationally expensive. This paper proposes a reinforcement learning approach for learning the weights in scheduler scoring algorithms with the overall objective of improving the end-to-end performance of jobs for a given cluster. Our approach is based on percentage improvement reward, frame-stacking, and limiting domain information. We propose a percentage improvement reward to address the objective of multi-step parameter tuning. The inclusion of frame-stacking allows for carrying information across an optimization experiment. Limiting domain information prevents overfitting and improves performance in unseen clusters and workloads. The policy is trained on different combinations of workloads and cluster setups. We demonstrate the proposed approach improves performance on average by 33\% compared to fixed weights and 12\% compared to the best-performing baseline in a lab-based serverless scenario.
DAM: Towards A Foundation Model for Time Series Forecasting
Jul 25, 2024It is challenging to scale time series forecasting models such that they forecast accurately for multiple distinct domains and datasets, all with potentially different underlying collection procedures (e.g., sample resolution), patterns (e.g., periodicity), and prediction requirements (e.g., reconstruction vs. forecasting). We call this general task universal forecasting. Existing methods usually assume that input data is regularly sampled, and they forecast to pre-determined horizons, resulting in failure to generalise outside of the scope of their training. We propose the DAM - a neural model that takes randomly sampled histories and outputs an adjustable basis composition as a continuous function of time for forecasting to non-fixed horizons. It involves three key components: (1) a flexible approach for using randomly sampled histories from a long-tail distribution, that enables an efficient global perspective of the underlying temporal dynamics while retaining focus on the recent history; (2) a transformer backbone that is trained on these actively sampled histories to produce, as representational output, (3) the basis coefficients of a continuous function of time. We show that a single univariate DAM, trained on 25 time series datasets, either outperformed or closely matched existing SoTA models at multivariate long-term forecasting across 18 datasets, including 8 held-out for zero-shot transfer, even though these models were trained to specialise for each dataset-horizon combination. This single DAM excels at zero-shot transfer and very-long-term forecasting, performs well at imputation, is interpretable via basis function composition and attention, can be tuned for different inference-cost requirements, is robust to missing and irregularly sampled data {by design}.
How Does It Function? Characterizing Long-term Trends in Production Serverless Workloads
Dec 15, 2023This paper releases and analyzes two new Huawei cloud serverless traces. The traces span a period of over 7 months with over 1.4 trillion function invocations combined. The first trace is derived from Huawei's internal workloads and contains detailed per-second statistics for 200 functions running across multiple Huawei cloud data centers. The second trace is a representative workload from Huawei's public FaaS platform. This trace contains per-minute arrival rates for over 5000 functions running in a single Huawei data center. We present the internals of a production FaaS platform by characterizing resource consumption, cold-start times, programming languages used, periodicity, per-second versus per-minute burstiness, correlations, and popularity. Our findings show that there is considerable diversity in how serverless functions behave: requests vary by up to 9 orders of magnitude across functions, with some functions executed over 1 billion times per day; scheduling time, execution time and cold-start distributions vary across 2 to 4 orders of magnitude and have very long tails; and function invocation counts demonstrate strong periodicity for many individual functions and on an aggregate level. Our analysis also highlights the need for further research in estimating resource reservations and time-series prediction to account for the huge diversity in how serverless functions behave. Datasets and code available at https://github.com/sir-lab/data-release
Benchmarking and Performance Modelling of MapReduce Communication Pattern
May 23, 2020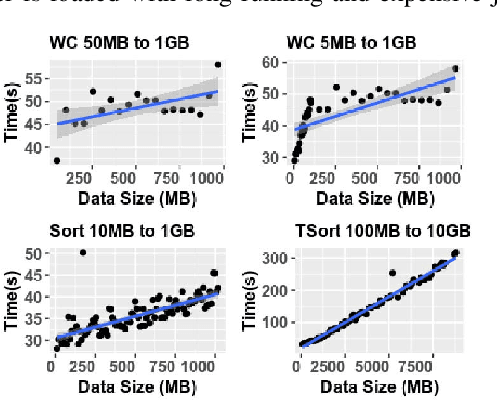



Understanding and predicting the performance of big data applications running in the cloud or on-premises could help minimise the overall cost of operations and provide opportunities in efforts to identify performance bottlenecks. The complexity of the low-level internals of big data frameworks and the ubiquity of application and workload configuration parameters makes it challenging and expensive to come up with comprehensive performance modelling solutions. In this paper, instead of focusing on a wide range of configurable parameters, we studied the low-level internals of the MapReduce communication pattern and used a minimal set of performance drivers to develop a set of phase level parametric models for approximating the execution time of a given application on a given cluster. Models can be used to infer the performance of unseen applications and approximate their performance when an arbitrary dataset is used as input. Our approach is validated by running empirical experiments in two setups. On average the error rate in both setups is plus or minus 10% from the measured values.
* 8 pages, 10 figures
Integrating Know-How into the Linked Data Cloud
Apr 15, 2016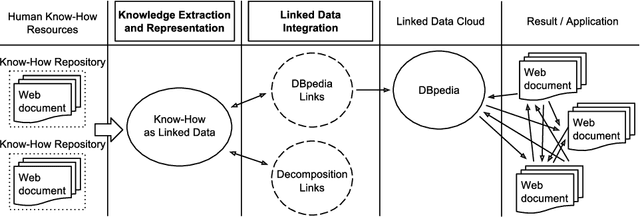

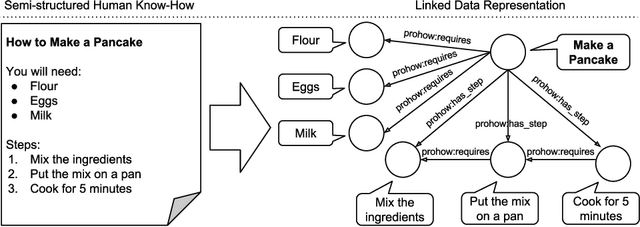
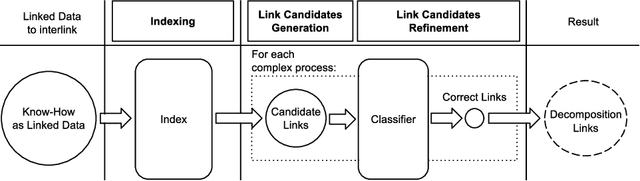
This paper presents the first framework for integrating procedural knowledge, or "know-how", into the Linked Data Cloud. Know-how available on the Web, such as step-by-step instructions, is largely unstructured and isolated from other sources of online knowledge. To overcome these limitations, we propose extending to procedural knowledge the benefits that Linked Data has already brought to representing, retrieving and reusing declarative knowledge. We describe a framework for representing generic know-how as Linked Data and for automatically acquiring this representation from existing resources on the Web. This system also allows the automatic generation of links between different know-how resources, and between those resources and other online knowledge bases, such as DBpedia. We discuss the results of applying this framework to a real-world scenario and we show how it outperforms existing manual community-driven integration efforts.
* The 19th International Conference on Knowledge Engineering and Knowledge Management (EKAW 2014), 24-28 November 2014, Link\"oping, Sweden
A Linked Data Scalability Challenge: Concept Reuse Leads to Semantic Decay
Mar 05, 2016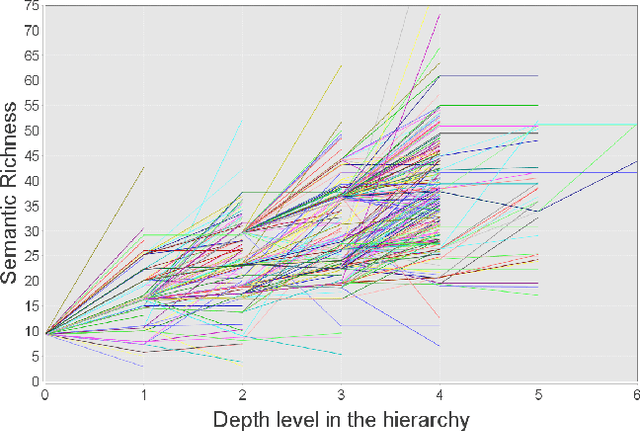
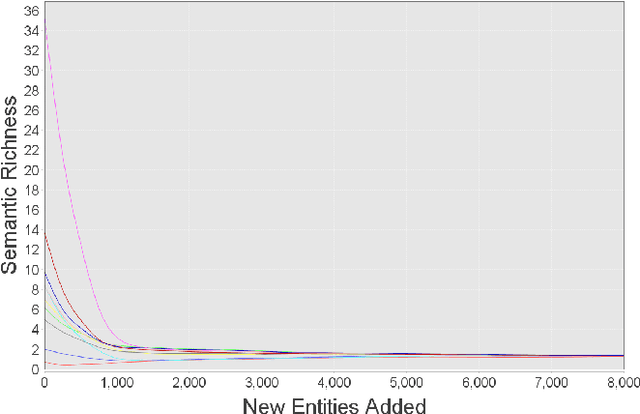
The increasing amount of available Linked Data resources is laying the foundations for more advanced Semantic Web applications. One of their main limitations, however, remains the general low level of data quality. In this paper we focus on a measure of quality which is negatively affected by the increase of the available resources. We propose a measure of semantic richness of Linked Data concepts and we demonstrate our hypothesis that the more a concept is reused, the less semantically rich it becomes. This is a significant scalability issue, as one of the core aspects of Linked Data is the propagation of semantic information on the Web by reusing common terms. We prove our hypothesis with respect to our measure of semantic richness and we validate our model empirically. Finally, we suggest possible future directions to address this scalability problem.
Autonomous Fault Detection in Self-Healing Systems using Restricted Boltzmann Machines
Jan 07, 2015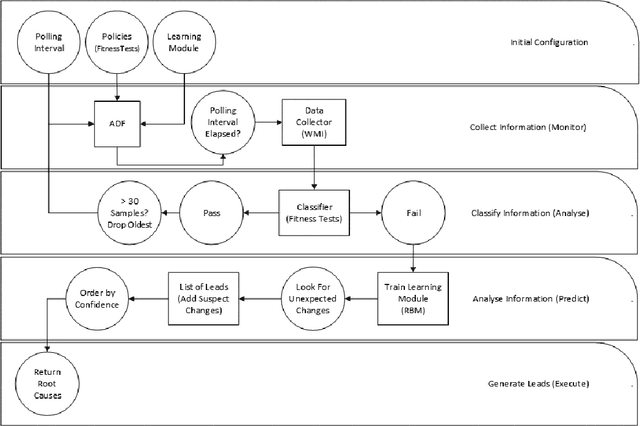
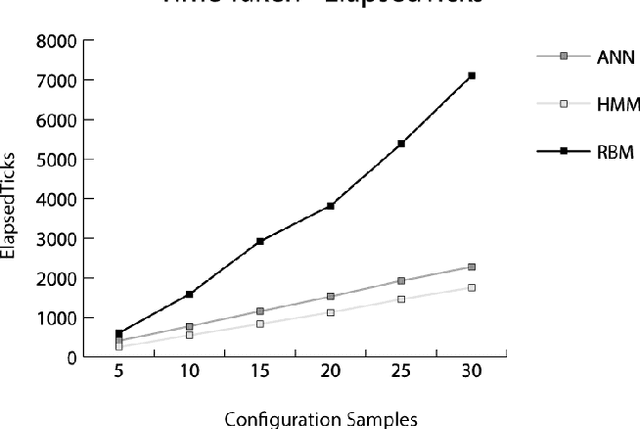
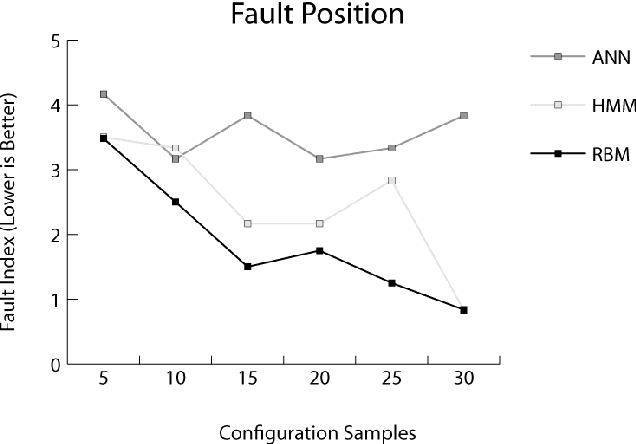
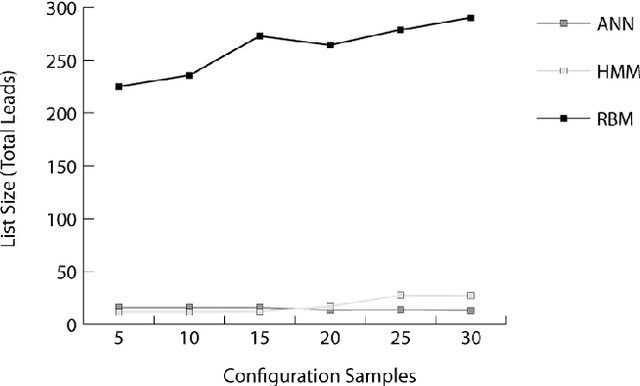
Autonomously detecting and recovering from faults is one approach for reducing the operational complexity and costs associated with managing computing environments. We present a novel methodology for autonomously generating investigation leads that help identify systems faults, and extends our previous work in this area by leveraging Restricted Boltzmann Machines (RBMs) and contrastive divergence learning to analyse changes in historical feature data. This allows us to heuristically identify the root cause of a fault, and demonstrate an improvement to the state of the art by showing feature data can be predicted heuristically beyond a single instance to include entire sequences of information.
A Semantic Web of Know-How: Linked Data for Community-Centric Tasks
Oct 29, 2014
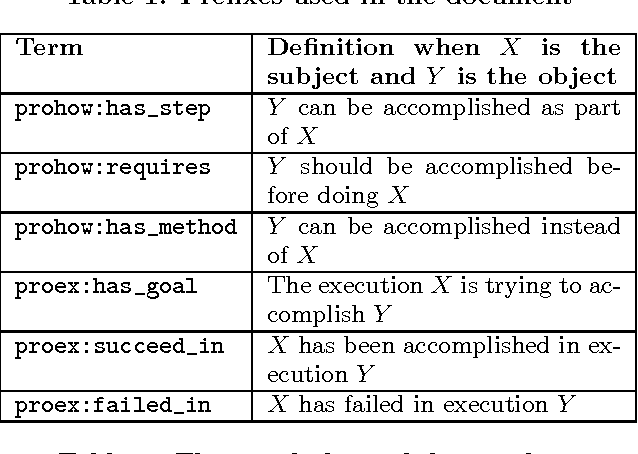
This paper proposes a novel framework for representing community know-how on the Semantic Web. Procedural knowledge generated by web communities typically takes the form of natural language instructions or videos and is largely unstructured. The absence of semantic structure impedes the deployment of many useful applications, in particular the ability to discover and integrate know-how automatically. We discuss the characteristics of community know-how and argue that existing knowledge representation frameworks fail to represent it adequately. We present a novel framework for representing the semantic structure of community know-how and demonstrate the feasibility of our approach by providing a concrete implementation which includes a method for automatically acquiring procedural knowledge for real-world tasks.
The Royal Birth of 2013: Analysing and Visualising Public Sentiment in the UK Using Twitter
Aug 16, 2013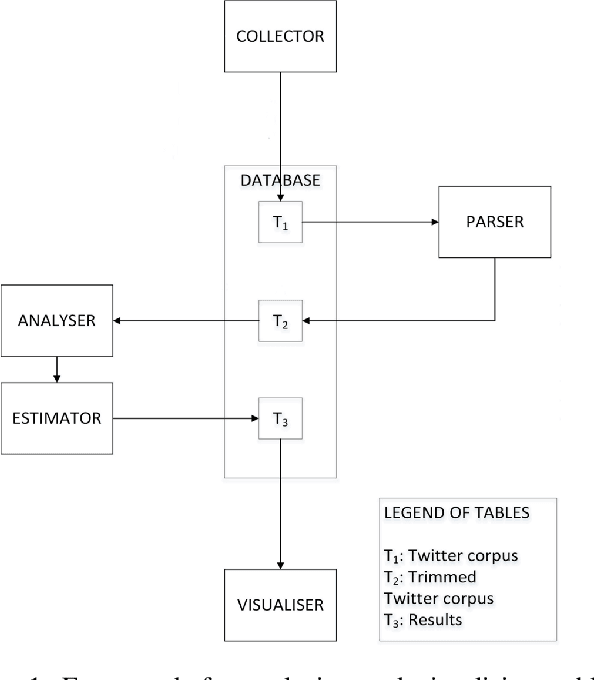



Analysis of information retrieved from microblogging services such as Twitter can provide valuable insight into public sentiment in a geographic region. This insight can be enriched by visualising information in its geographic context. Two underlying approaches for sentiment analysis are dictionary-based and machine learning. The former is popular for public sentiment analysis, and the latter has found limited use for aggregating public sentiment from Twitter data. The research presented in this paper aims to extend the machine learning approach for aggregating public sentiment. To this end, a framework for analysing and visualising public sentiment from a Twitter corpus is developed. A dictionary-based approach and a machine learning approach are implemented within the framework and compared using one UK case study, namely the royal birth of 2013. The case study validates the feasibility of the framework for analysis and rapid visualisation. One observation is that there is good correlation between the results produced by the popular dictionary-based approach and the machine learning approach when large volumes of tweets are analysed. However, for rapid analysis to be possible faster methods need to be developed using big data techniques and parallel methods.