 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Performance Modelling of MapReduce Communication Pattern
May 23, 2020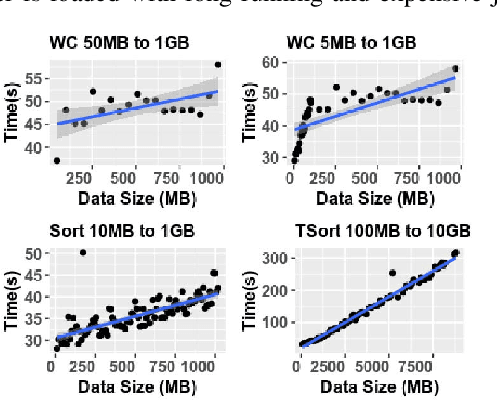



Understanding and predicting the performance of big data applications running in the cloud or on-premises could help minimise the overall cost of operations and provide opportunities in efforts to identify performance bottlenecks. The complexity of the low-level internals of big data frameworks and the ubiquity of application and workload configuration parameters makes it challenging and expensive to come up with comprehensive performance modelling solutions. In this paper, instead of focusing on a wide range of configurable parameters, we studied the low-level internals of the MapReduce communication pattern and used a minimal set of performance drivers to develop a set of phase level parametric models for approximating the execution time of a given application on a given cluster. Models can be used to infer the performance of unseen applications and approximate their performance when an arbitrary dataset is used as input. Our approach is validated by running empirical experiments in two setups. On average the error rate in both setups is plus or minus 10% from the measured values.
* 8 pages, 10 figures