 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs
Apr 03, 2026Recent advances in Multimodal Large Language Models (MLLMs) have expanded reasoning capabilities into 3D domains, enabling fine-grained spatial understanding. However, the substantial size of 3D MLLMs and the high dimensionality of input features introduce considerable inference overhead, which limits practical deployment on resource constrained platforms. To overcome this limitation, this paper presents Efficient3D, a unified framework for visual token pruning that accelerates 3D MLLMs while maintaining competitive accuracy. The proposed framework introduces a Debiased Visual Token Importance Estimator (DVTIE) module, which considers the influence of shallow initial layers during attention aggregation, thereby producing more reliable importance predictions for visual tokens. In addition, an Adaptive Token Rebalancing (ATR) strategy is developed to dynamically adjust pruning strength based on scene complexity, preserving semantic completeness and maintaining balanced attention across layers. Together, they enable context-aware token reduction that maintains essential semantics with lower computation. Comprehensive experiments conducted on five representative 3D vision and language benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D, demonstrate that Efficient3D achieves superior performance compared with unpruned baselines, with a +2.57% CIDEr improvement on the Scan2Cap dataset. Therefore, Efficient3D provides a scalable and effective solution for efficient inference in 3D MLLMs. The code is released at: https://github.com/sol924/Efficient3D
Graph Mamba for Efficient Whole Slide Image Understanding
May 23, 2025Whole Slide Images (WSIs) in histopathology present a significant challenge for large-scale medical image analysis due to their high resolution, large size, and complex tile relationships. Existing Multiple Instance Learning (MIL) methods, such as Graph Neural Networks (GNNs) and Transformer-based models, face limitations in scalability and computational cost. To bridge this gap, we propose the WSI-GMamba framework, which synergistically combines the relational modeling strengths of GNNs with the efficiency of Mamba, the State Space Model designed for sequence learning. The proposed GMamba block integrates Message Passing, Graph Scanning & Flattening, and feature aggregation via a Bidirectional State Space Model (Bi-SSM), achieving Transformer-level performance with 7* fewer FLOPs. By leveraging the complementary strengths of lightweight GNNs and Mamba, the WSI-GMamba framework delivers a scalable solution for large-scale WSI analysis, offering both high accuracy and computational efficiency for slide-level classification.
MV-GMN: State Space Model for Multi-View Action Recognition
Jan 23, 2025



Recent advancements in multi-view action recognition have largely relied on Transformer-based models. While effective and adaptable, these models often require substantial computational resources, especially in scenarios with multiple views and multiple temporal sequences. Addressing this limitation, this paper introduces the MV-GMN model, a state-space model specifically designed to efficiently aggregate multi-modal data (RGB and skeleton), multi-view perspectives, and multi-temporal information for action recognition with reduced computational complexity. The MV-GMN model employs an innovative Multi-View Graph Mamba network comprising a series of MV-GMN blocks. Each block includes a proposed Bidirectional State Space Block and a GCN module. The Bidirectional State Space Block introduces four scanning strategies, including view-prioritized and time-prioritized approaches. The GCN module leverages rule-based and KNN-based methods to construct the graph network, effectively integrating features from different viewpoints and temporal instances. Demonstrating its efficacy, MV-GMN outperforms the state-of-the-arts on several datasets, achieving notable accuracies of 97.3\% and 96.7\% on the NTU RGB+D 120 dataset in cross-subject and cross-view scenarios, respectively. MV-GMN also surpasses Transformer-based baselines while requiring only linear inference complexity, underscoring the model's ability to reduce computational load and enhance the scalability and applicability of multi-view action recognition technologies.
Event USKT : U-State Space Model in Knowledge Transfer for Event Cameras
Nov 22, 2024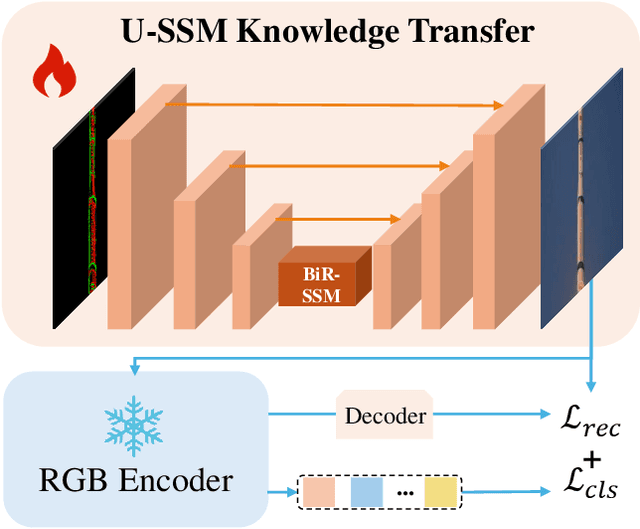



Event cameras, as an emerging imaging technology, offer distinct advantages over traditional RGB cameras, including reduced energy consumption and higher frame rates. However, the limited quantity of available event data presents a significant challenge, hindering their broader development. To alleviate this issue, we introduce a tailored U-shaped State Space Model Knowledge Transfer (USKT) framework for Event-to-RGB knowledge transfer. This framework generates inputs compatible with RGB frames, enabling event data to effectively reuse pre-trained RGB models and achieve competitive performance with minimal parameter tuning. Within the USKT architecture, we also propose a bidirectional reverse state space model. Unlike conventional bidirectional scanning mechanisms, the proposed Bidirectional Reverse State Space Model (BiR-SSM) leverages a shared weight strategy, which facilitates efficient modeling while conserving computational resources. In terms of effectiveness, integrating USKT with ResNet50 as the backbone improves model performance by 0.95%, 3.57%, and 2.9% on DVS128 Gesture, N-Caltech101, and CIFAR-10-DVS datasets, respectively, underscoring USKT's adaptability and effectiveness. The code will be made available upon acceptance.
Benchmarking and Performance Modelling of MapReduce Communication Pattern
May 23, 2020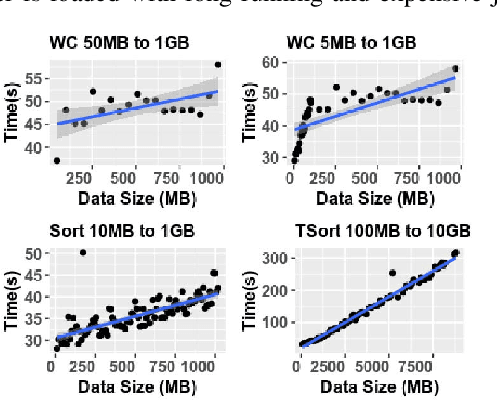



Understanding and predicting the performance of big data applications running in the cloud or on-premises could help minimise the overall cost of operations and provide opportunities in efforts to identify performance bottlenecks. The complexity of the low-level internals of big data frameworks and the ubiquity of application and workload configuration parameters makes it challenging and expensive to come up with comprehensive performance modelling solutions. In this paper, instead of focusing on a wide range of configurable parameters, we studied the low-level internals of the MapReduce communication pattern and used a minimal set of performance drivers to develop a set of phase level parametric models for approximating the execution time of a given application on a given cluster. Models can be used to infer the performance of unseen applications and approximate their performance when an arbitrary dataset is used as input. Our approach is validated by running empirical experiments in two setups. On average the error rate in both setups is plus or minus 10% from the measured values.
* 8 pages, 10 figures