 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Evidence Generation for Assurance Cases for Robotic Software Models
Feb 03, 2026Robotics and Autonomous Systems are increasingly deployed in safety-critical domains, so that demonstrating their safety is essential. Assurance Cases (ACs) provide structured arguments supported by evidence, but generating and maintaining this evidence is labour-intensive, error-prone, and difficult to keep consistent as systems evolve. We present a model-based approach to systematically generating AC evidence by embedding formal verification into the assurance workflow. The approach addresses three challenges: systematically deriving formal assertions from natural language requirements using templates, orchestrating multiple formal verification tools to handle diverse property types, and integrating formal evidence production into the workflow. Leveraging RoboChart, a domain-specific modelling language with formal semantics, we combine model checking and theorem proving in our approach. Structured requirements are automatically transformed into formal assertions using predefined templates, and verification results are automatically integrated as evidence. Case studies demonstrate the effectiveness of our approach.
Rank-Aware Agglomeration of Foundation Models for Immunohistochemistry Image Cell Counting
Nov 16, 2025Accurate cell counting in immunohistochemistry (IHC) images is critical for quantifying protein expression and aiding cancer diagnosis. However, the task remains challenging due to the chromogen overlap, variable biomarker staining, and diverse cellular morphologies. Regression-based counting methods offer advantages over detection-based ones in handling overlapped cells, yet rarely support end-to-end multi-class counting. Moreover, the potential of foundation models remains largely underexplored in this paradigm. To address these limitations, we propose a rank-aware agglomeration framework that selectively distills knowledge from multiple strong foundation models, leveraging their complementary representations to handle IHC heterogeneity and obtain a compact yet effective student model, CountIHC. Unlike prior task-agnostic agglomeration strategies that either treat all teachers equally or rely on feature similarity, we design a Rank-Aware Teacher Selecting (RATS) strategy that models global-to-local patch rankings to assess each teacher's inherent counting capacity and enable sample-wise teacher selection. For multi-class cell counting, we introduce a fine-tuning stage that reformulates the task as vision-language alignment. Discrete semantic anchors derived from structured text prompts encode both category and quantity information, guiding the regression of class-specific density maps and improving counting for overlapping cells. Extensive experiments demonstrate that CountIHC surpasses state-of-the-art methods across 12 IHC biomarkers and 5 tissue types, while exhibiting high agreement with pathologists' assessments. Its effectiveness on H&E-stained data further confirms the scalability of the proposed method.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Graph Mamba for Efficient Whole Slide Image Understanding
May 23, 2025Whole Slide Images (WSIs) in histopathology present a significant challenge for large-scale medical image analysis due to their high resolution, large size, and complex tile relationships. Existing Multiple Instance Learning (MIL) methods, such as Graph Neural Networks (GNNs) and Transformer-based models, face limitations in scalability and computational cost. To bridge this gap, we propose the WSI-GMamba framework, which synergistically combines the relational modeling strengths of GNNs with the efficiency of Mamba, the State Space Model designed for sequence learning. The proposed GMamba block integrates Message Passing, Graph Scanning & Flattening, and feature aggregation via a Bidirectional State Space Model (Bi-SSM), achieving Transformer-level performance with 7* fewer FLOPs. By leveraging the complementary strengths of lightweight GNNs and Mamba, the WSI-GMamba framework delivers a scalable solution for large-scale WSI analysis, offering both high accuracy and computational efficiency for slide-level classification.
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
Cost-effective Instruction Learning for Pathology Vision and Language Analysis
Jul 25, 2024
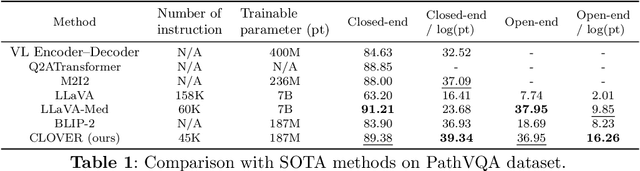
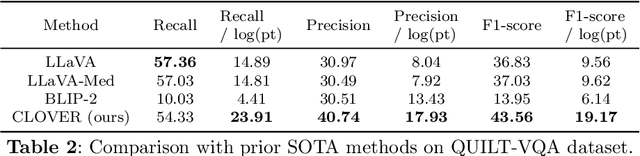

The advent of vision-language models fosters the interactive conversations between AI-enabled models and humans. Yet applying these models into clinics must deal with daunting challenges around large-scale training data, financial, and computational resources. Here we propose a cost-effective instruction learning framework for conversational pathology named as CLOVER. CLOVER only trains a lightweight module and uses instruction tuning while freezing the parameters of the large language model. Instead of using costly GPT-4, we propose well-designed prompts on GPT-3.5 for building generation-based instructions, emphasizing the utility of pathological knowledge derived from the Internet source. To augment the use of instructions, we construct a high-quality set of template-based instructions in the context of digital pathology. From two benchmark datasets, our findings reveal the strength of hybrid-form instructions in the visual question-answer in pathology. Extensive results show the cost-effectiveness of CLOVER in answering both open-ended and closed-ended questions, where CLOVER outperforms strong baselines that possess 37 times more training parameters and use instruction data generated from GPT-4. Through the instruction tuning, CLOVER exhibits robustness of few-shot learning in the external clinical dataset. These findings demonstrate that cost-effective modeling of CLOVER could accelerate the adoption of rapid conversational applications in the landscape of digital pathology.
PathoTune: Adapting Visual Foundation Model to Pathological Specialists
Mar 25, 2024As natural image understanding moves towards the pretrain-finetune era, research in pathology imaging is concurrently evolving. Despite the predominant focus on pretraining pathological foundation models, how to adapt foundation models to downstream tasks is little explored. For downstream adaptation, we propose the existence of two domain gaps, i.e., the Foundation-Task Gap and the Task-Instance Gap. To mitigate these gaps, we introduce PathoTune, a framework designed to efficiently adapt pathological or even visual foundation models to pathology-specific tasks via multi-modal prompt tuning. The proposed framework leverages Task-specific Visual Prompts and Task-specific Textual Prompts to identify task-relevant features, along with Instance-specific Visual Prompts for encoding single pathological image features. Results across multiple datasets at both patch-level and WSI-level demonstrate its superior performance over single-modality prompt tuning approaches. Significantly, PathoTune facilitates the direct adaptation of natural visual foundation models to pathological tasks, drastically outperforming pathological foundation models with simple linear probing. The code will be available upon acceptance.
PathoDuet: Foundation Models for Pathological Slide Analysis of H&E and IHC Stains
Dec 15, 2023



Large amounts of digitized histopathological data display a promising future for developing pathological foundation models via self-supervised learning methods. Foundation models pretrained with these methods serve as a good basis for downstream tasks. However, the gap between natural and histopathological images hinders the direct application of existing methods. In this work, we present PathoDuet, a series of pretrained models on histopathological images, and a new self-supervised learning framework in histopathology. The framework is featured by a newly-introduced pretext token and later task raisers to explicitly utilize certain relations between images, like multiple magnifications and multiple stains. Based on this, two pretext tasks, cross-scale positioning and cross-stain transferring, are designed to pretrain the model on Hematoxylin and Eosin (H\&E) images and transfer the model to immunohistochemistry (IHC) images, respectively. To validate the efficacy of our models, we evaluate the performance over a wide variety of downstream tasks, including patch-level colorectal cancer subtyping and whole slide image (WSI)-level classification in H\&E field, together with expression level prediction of IHC marker and tumor identification in IHC field. The experimental results show the superiority of our models over most tasks and the efficacy of proposed pretext tasks. The codes and models are available at https://github.com/openmedlab/PathoDuet.
Integrated Age Estimation Mechanism
Mar 11, 2021
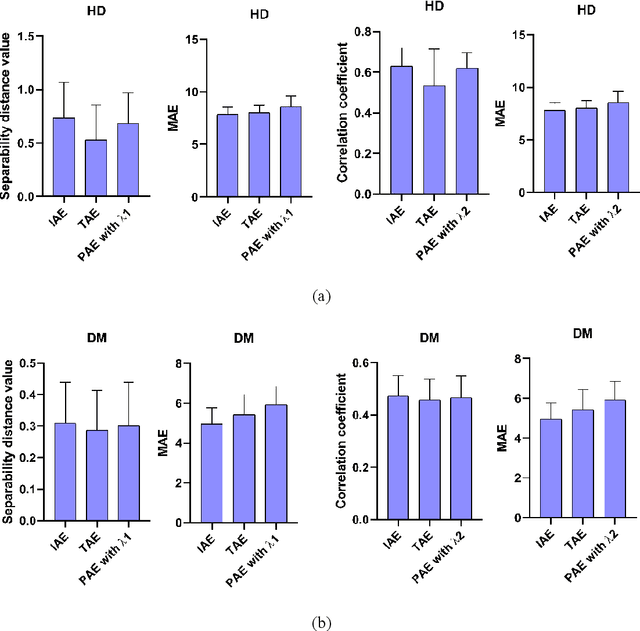
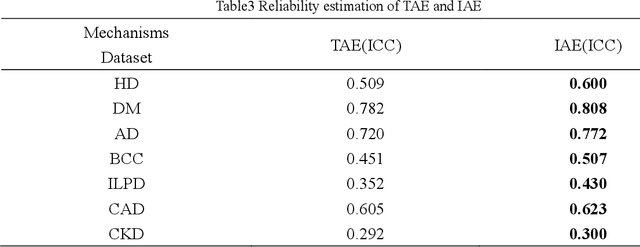
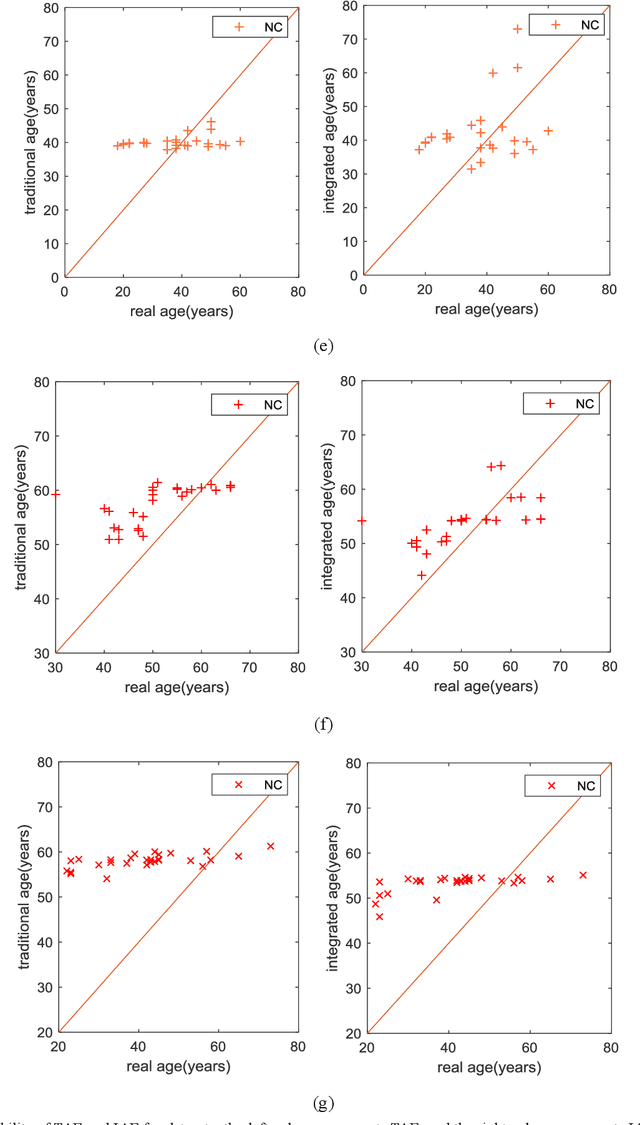
Machine-learning-based age estimation has received lots of attention. Traditional age estimation mechanism focuses estimation age error, but ignores that there is a deviation between the estimated age and real age due to disease. Pathological age estimation mechanism the author proposed before introduces age deviation to solve the above problem and improves classification capability of the estimated age significantly. However,it does not consider the age estimation error of the normal control (NC) group and results in a larger error between the estimated age and real age of NC group. Therefore, an integrated age estimation mechanism based on Decision-Level fusion of error and deviation orientation model is proposed to solve the problem.Firstly, the traditional age estimation and pathological age estimation mechanisms are weighted together.Secondly, their optimal weights are obtained by minimizing mean absolute error (MAE) between the estimated age and real age of normal people. In the experimental section, several representative age-related datasets are used for verification of the proposed method. The results show that the proposed age estimation mechanism achieves a good tradeoff effect of age estimation. It not only improves the classification ability of the estimated age, but also reduces the age estimation error of the NC group. In general, the proposed age estimation mechanism is effective. Additionally, the mechanism is a framework mechanism that can be used to construct different specific age estimation algorithms, contributing to relevant research.