 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriftGuard: Mitigating Asynchronous Data Drift in Federated Learning
Mar 19, 2026In real-world Federated Learning (FL) deployments, data distributions on devices that participate in training evolve over time. This leads to asynchronous data drift, where different devices shift at different times and toward different distributions. Mitigating such drift is challenging: frequent retraining incurs high computational cost on resource-constrained devices, while infrequent retraining degrades performance on drifting devices. We propose DriftGuard, a federated continual learning framework that efficiently adapts to asynchronous data drift. DriftGuard adopts a Mixture-of-Experts (MoE) inspired architecture that separates shared parameters, which capture globally transferable knowledge, from local parameters that adapt to group-specific distributions. This design enables two complementary retraining strategies: (i) global retraining, which updates the shared parameters when system-wide drift is identified, and (ii) group retraining, which selectively updates local parameters for clusters of devices identified via MoE gating patterns, without sharing raw data. Experiments across multiple datasets and models show that DriftGuard matches or exceeds state-of-the-art accuracy while reducing total retraining cost by up to 83%. As a result, it achieves the highest accuracy per unit retraining cost, improving over the strongest baseline by up to 2.3x. DriftGuard is available for download from https://github.com/blessonvar/DriftGuard.
Multi-DNN Inference of Sparse Models on Edge SoCs
Mar 10, 2026Modern edge applications increasingly require multi-DNN inference systems to execute tasks on heterogeneous processors, gaining performance from both concurrent execution and from matching each model to the most suited accelerator. However, existing systems support only a single model (or a few sparse variants) per task, which impedes the efficiency of this matching and results in high Service Level Objective violation rates. We introduce model stitching for multi-DNN inference systems, which creates model variants by recombining subgraphs from sparse models without re-training. We present a demonstrator system, SparseLoom, that shows model stitching can be deployed to SoCs. We show experimentally that SparseLoom reduces SLO violation rates by up to 74%, improves throughput by up to 2.31x, and lowers memory overhead by an average of 28% compared to state-of-the-art multi-DNN inference systems.
Mosaic: Composite Projection Pruning for Resource-efficient LLMs
Apr 08, 2025Extensive compute and memory requirements limit the deployment of large language models (LLMs) on any hardware. Compression methods, such as pruning, can reduce model size, which in turn reduces resource requirements. State-of-the-art pruning is based on coarse-grained methods. They are time-consuming and inherently remove critical model parameters, adversely impacting the quality of the pruned model. This paper introduces projection pruning, a novel fine-grained method for pruning LLMs. In addition, LLM projection pruning is enhanced by a new approach we refer to as composite projection pruning - the synergistic combination of unstructured pruning that retains accuracy and structured pruning that reduces model size. We develop Mosaic, a novel system to create and deploy pruned LLMs using composite projection pruning. Mosaic is evaluated using a range of performance and quality metrics on multiple hardware platforms, LLMs, and datasets. Mosaic is 7.19x faster in producing models than existing approaches. Mosaic models achieve up to 84.2% lower perplexity and 31.4% higher accuracy than models obtained from coarse-grained pruning. Up to 67% faster inference and 68% lower GPU memory use is noted for Mosaic models.
EMO: Edge Model Overlays to Scale Model Size in Federated Learning
Apr 01, 2025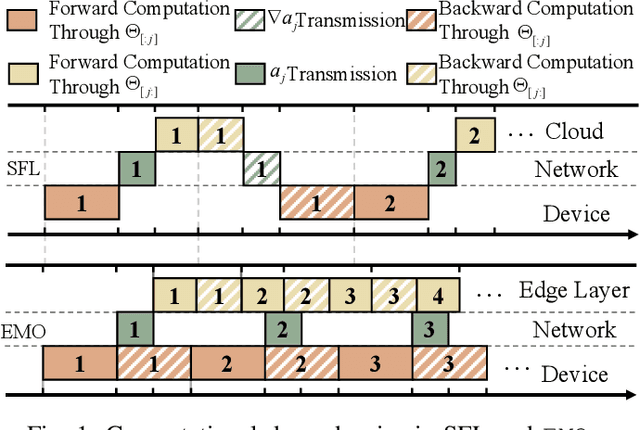
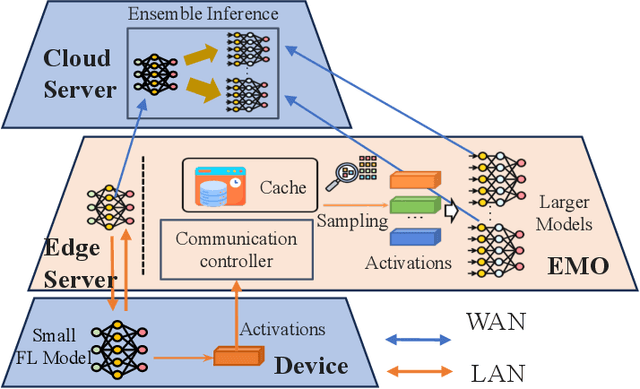
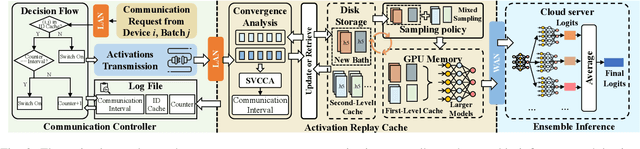
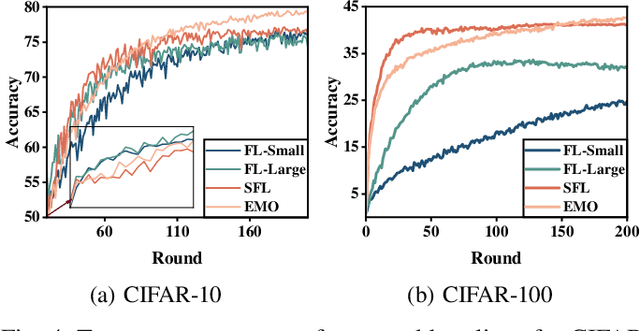
Federated Learning (FL) trains machine learning models on edge devices with distributed data. However, the computational and memory limitations of these devices restrict the training of large models using FL. Split Federated Learning (SFL) addresses this challenge by distributing the model across the device and server, but it introduces a tightly coupled data flow, leading to computational bottlenecks and high communication costs. We propose EMO as a solution to enable the training of large models in FL while mitigating the challenges of SFL. EMO introduces Edge Model Overlay(s) between the device and server, enabling the creation of a larger ensemble model without modifying the FL workflow. The key innovation in EMO is Augmented Federated Learning (AFL), which builds an ensemble model by connecting the original (smaller) FL model with model(s) trained in the overlay(s) to facilitate horizontal or vertical scaling. This is accomplished through three key modules: a hierarchical activation replay cache to decouple AFL from FL, a convergence-aware communication controller to optimize communication overhead, and an ensemble inference module. Evaluations on a real-world prototype show that EMO improves accuracy by up to 17.77% compared to FL, and reduces communication costs by up to 7.17x and decreases training time by up to 6.9x compared to SFL.
Signal Collapse in One-Shot Pruning: When Sparse Models Fail to Distinguish Neural Representations
Feb 18, 2025Neural network pruning is essential for reducing model complexity to enable deployment on resource constrained hardware. While performance loss of pruned networks is often attributed to the removal of critical parameters, we identify signal collapse a reduction in activation variance across layers as the root cause. Existing one shot pruning methods focus on weight selection strategies and rely on computationally expensive second order approximations. In contrast, we demonstrate that mitigating signal collapse, rather than optimizing weight selection, is key to improving accuracy of pruned networks. We propose REFLOW that addresses signal collapse without updating trainable weights, revealing high quality sparse sub networks within the original parameter space. REFLOW enables magnitude pruning to achieve state of the art performance, restoring ResNeXt101 accuracy from under 4.1% to 78.9% on ImageNet with only 20% of the weights retained, surpassing state of the art approaches.
Rapid Deployment of DNNs for Edge Computing via Structured Pruning at Initialization
Apr 22, 2024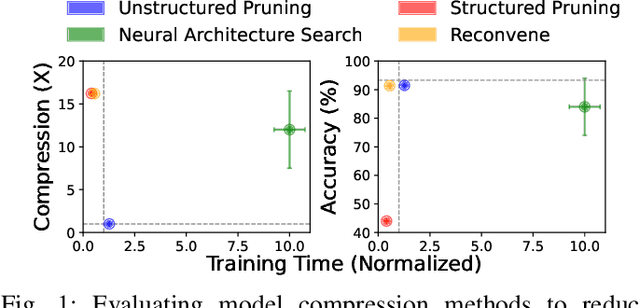
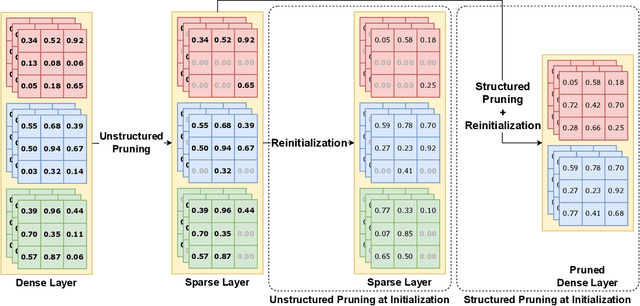
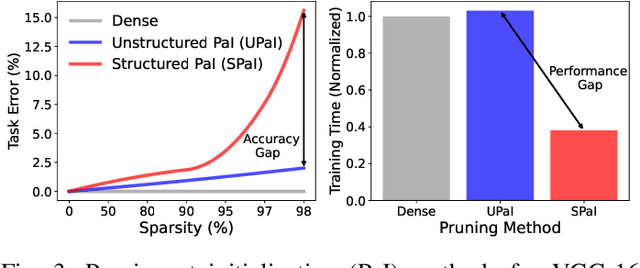
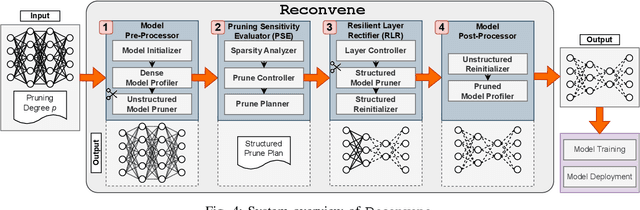
Edge machine learning (ML) enables localized processing of data on devices and is underpinned by deep neural networks (DNNs). However, DNNs cannot be easily run on devices due to their substantial computing, memory and energy requirements for delivering performance that is comparable to cloud-based ML. Therefore, model compression techniques, such as pruning, have been considered. Existing pruning methods are problematic for edge ML since they: (1) Create compressed models that have limited runtime performance benefits (using unstructured pruning) or compromise the final model accuracy (using structured pruning), and (2) Require substantial compute resources and time for identifying a suitable compressed DNN model (using neural architecture search). In this paper, we explore a new avenue, referred to as Pruning-at-Initialization (PaI), using structured pruning to mitigate the above problems. We develop Reconvene, a system for rapidly generating pruned models suited for edge deployments using structured PaI. Reconvene systematically identifies and prunes DNN convolution layers that are least sensitive to structured pruning. Reconvene rapidly creates pruned DNNs within seconds that are up to 16.21x smaller and 2x faster while maintaining the same accuracy as an unstructured PaI counterpart.
DRIVE: Dual Gradient-Based Rapid Iterative Pruning
Apr 01, 2024
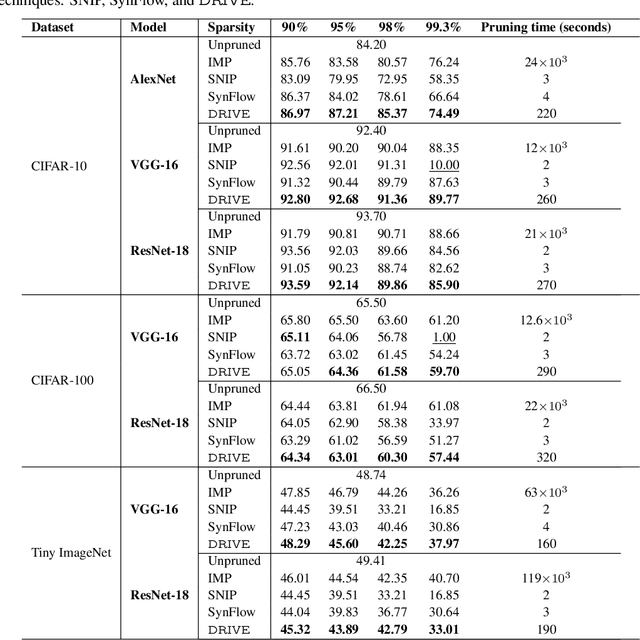
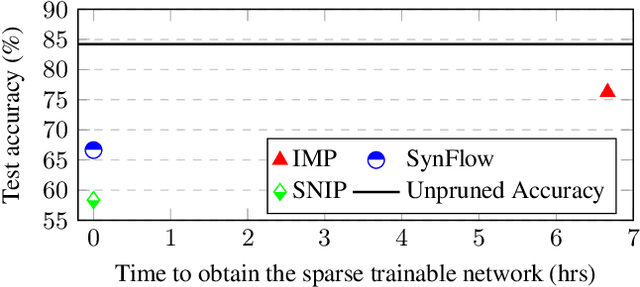
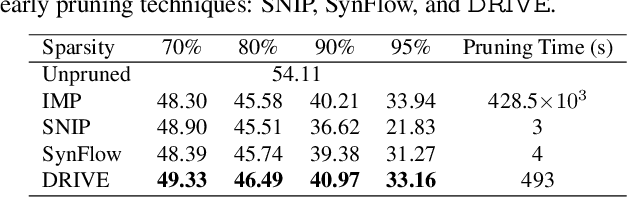
Modern deep neural networks (DNNs) consist of millions of parameters, necessitating high-performance computing during training and inference. Pruning is one solution that significantly reduces the space and time complexities of DNNs. Traditional pruning methods that are applied post-training focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training. Pruning methods, such as iterative magnitude-based pruning (IMP) achieve up to a 90% parameter reduction while retaining accuracy comparable to the original model. However, this leads to impractical runtime as it relies on multiple train-prune-reset cycles to identify and eliminate redundant parameters. In contrast, training agnostic early pruning methods, such as SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities. To bridge this gap, we present Dual Gradient-Based Rapid Iterative Pruning (DRIVE), which leverages dense training for initial epochs to counteract the randomness inherent at the initialization. Subsequently, it employs a unique dual gradient-based metric for parameter ranking. It has been experimentally demonstrated for VGG and ResNet architectures on CIFAR-10/100 and Tiny ImageNet, and ResNet on ImageNet that DRIVE consistently has superior performance over other training-agnostic early pruning methods in accuracy. Notably, DRIVE is 43$\times$ to 869$\times$ faster than IMP for pruning.
NeuroFlux: Memory-Efficient CNN Training Using Adaptive Local Learning
Mar 04, 2024



Efficient on-device Convolutional Neural Network (CNN) training in resource-constrained mobile and edge environments is an open challenge. Backpropagation is the standard approach adopted, but it is GPU memory intensive due to its strong inter-layer dependencies that demand intermediate activations across the entire CNN model to be retained in GPU memory. This necessitates smaller batch sizes to make training possible within the available GPU memory budget, but in turn, results in substantially high and impractical training time. We introduce NeuroFlux, a novel CNN training system tailored for memory-constrained scenarios. We develop two novel opportunities: firstly, adaptive auxiliary networks that employ a variable number of filters to reduce GPU memory usage, and secondly, block-specific adaptive batch sizes, which not only cater to the GPU memory constraints but also accelerate the training process. NeuroFlux segments a CNN into blocks based on GPU memory usage and further attaches an auxiliary network to each layer in these blocks. This disrupts the typical layer dependencies under a new training paradigm - $\textit{`adaptive local learning'}$. Moreover, NeuroFlux adeptly caches intermediate activations, eliminating redundant forward passes over previously trained blocks, further accelerating the training process. The results are twofold when compared to Backpropagation: on various hardware platforms, NeuroFlux demonstrates training speed-ups of 2.3$\times$ to 6.1$\times$ under stringent GPU memory budgets, and NeuroFlux generates streamlined models that have 10.9$\times$ to 29.4$\times$ fewer parameters.
DNNShifter: An Efficient DNN Pruning System for Edge Computing
Sep 13, 2023Deep neural networks (DNNs) underpin many machine learning applications. Production quality DNN models achieve high inference accuracy by training millions of DNN parameters which has a significant resource footprint. This presents a challenge for resources operating at the extreme edge of the network, such as mobile and embedded devices that have limited computational and memory resources. To address this, models are pruned to create lightweight, more suitable variants for these devices. Existing pruning methods are unable to provide similar quality models compared to their unpruned counterparts without significant time costs and overheads or are limited to offline use cases. Our work rapidly derives suitable model variants while maintaining the accuracy of the original model. The model variants can be swapped quickly when system and network conditions change to match workload demand. This paper presents DNNShifter, an end-to-end DNN training, spatial pruning, and model switching system that addresses the challenges mentioned above. At the heart of DNNShifter is a novel methodology that prunes sparse models using structured pruning. The pruned model variants generated by DNNShifter are smaller in size and thus faster than dense and sparse model predecessors, making them suitable for inference at the edge while retaining near similar accuracy as of the original dense model. DNNShifter generates a portfolio of model variants that can be swiftly interchanged depending on operational conditions. DNNShifter produces pruned model variants up to 93x faster than conventional training methods. Compared to sparse models, the pruned model variants are up to 5.14x smaller and have a 1.67x inference latency speedup, with no compromise to sparse model accuracy. In addition, DNNShifter has up to 11.9x lower overhead for switching models and up to 3.8x lower memory utilisation than existing approaches.
ROMA: Run-Time Object Detection To Maximize Real-Time Accuracy
Oct 28, 2022This paper analyzes the effects of dynamically varying video contents and detection latency on the real-time detection accuracy of a detector and proposes a new run-time accuracy variation model, ROMA, based on the findings from the analysis. ROMA is designed to select an optimal detector out of a set of detectors in real time without label information to maximize real-time object detection accuracy. ROMA utilizing four YOLOv4 detectors on an NVIDIA Jetson Nano shows real-time accuracy improvements by 4 to 37% for a scenario of dynamically varying video contents and detection latency consisting of MOT17Det and MOT20Det datasets, compared to individual YOLOv4 detectors and two state-of-the-art runtime techniques.