 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGuard-v1: Safety Guardrail for Large Language Models
Nov 16, 2025We present SGuard-v1, a lightweight safety guardrail for Large Language Models (LLMs), which comprises two specialized models to detect harmful content and screen adversarial prompts in human-AI conversational settings. The first component, ContentFilter, is trained to identify safety risks in LLM prompts and responses in accordance with the MLCommons hazard taxonomy, a comprehensive framework for trust and safety assessment of AI. The second component, JailbreakFilter, is trained with a carefully designed curriculum over integrated datasets and findings from prior work on adversarial prompting, covering 60 major attack types while mitigating false-unsafe classification. SGuard-v1 is built on the 2B-parameter Granite-3.3-2B-Instruct model that supports 12 languages. We curate approximately 1.4 million training instances from both collected and synthesized data and perform instruction tuning on the base model, distributing the curated data across the two component according to their designated functions. Through extensive evaluation on public and proprietary safety benchmarks, SGuard-v1 achieves state-of-the-art safety performance while remaining lightweight, thereby reducing deployment overhead. SGuard-v1 also improves interpretability for downstream use by providing multi-class safety predictions and their binary confidence scores. We release the SGuard-v1 under the Apache-2.0 License to enable further research and practical deployment in AI safety.
Fast, Scalable, Energy-Efficient Non-element-wise Matrix Multiplication on FPGA
Jul 02, 2024



Modern Neural Network (NN) architectures heavily rely on vast numbers of multiply-accumulate arithmetic operations, constituting the predominant computational cost. Therefore, this paper proposes a high-throughput, scalable and energy efficient non-element-wise matrix multiplication unit on FPGAs as a basic component of the NNs. We firstly streamline inter-layer and intra-layer redundancies of MADDNESS algorithm, a LUT-based approximate matrix multiplication, to design a fast, efficient scalable approximate matrix multiplication module termed "Approximate Multiplication Unit (AMU)". The AMU optimizes LUT-based matrix multiplications further through dedicated memory management and access design, decoupling computational overhead from input resolution and boosting FPGA-based NN accelerator efficiency significantly. The experimental results show that using our AMU achieves up to 9x higher throughput and 112x higher energy efficiency over the state-of-the-art solutions for the FPGA-based Quantised Neural Network (QNN) accelerators.
ROMA: Run-Time Object Detection To Maximize Real-Time Accuracy
Oct 28, 2022This paper analyzes the effects of dynamically varying video contents and detection latency on the real-time detection accuracy of a detector and proposes a new run-time accuracy variation model, ROMA, based on the findings from the analysis. ROMA is designed to select an optimal detector out of a set of detectors in real time without label information to maximize real-time object detection accuracy. ROMA utilizing four YOLOv4 detectors on an NVIDIA Jetson Nano shows real-time accuracy improvements by 4 to 37% for a scenario of dynamically varying video contents and detection latency consisting of MOT17Det and MOT20Det datasets, compared to individual YOLOv4 detectors and two state-of-the-art runtime techniques.
Resource-Efficient Deep Learning: A Survey on Model-, Arithmetic-, and Implementation-Level Techniques
Dec 30, 2021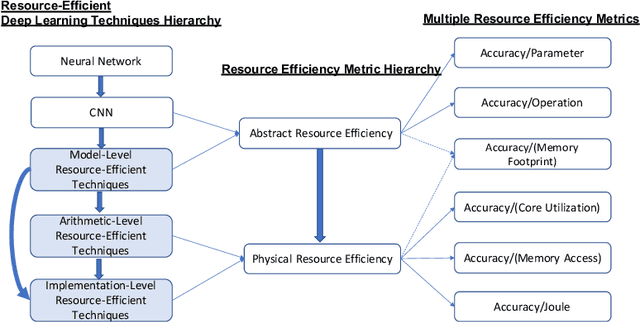
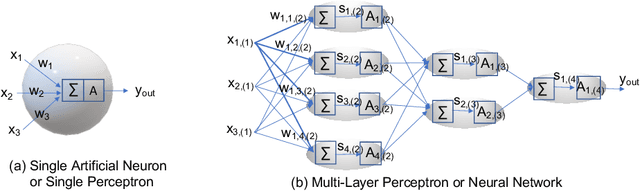
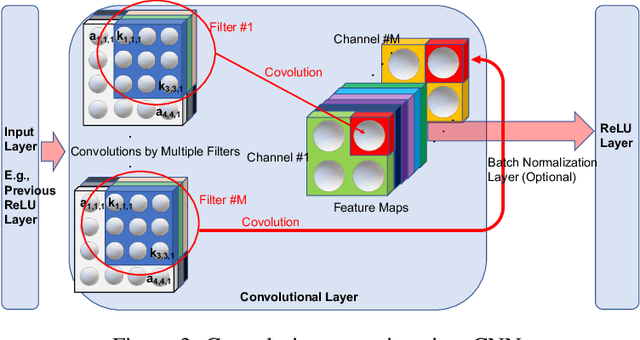
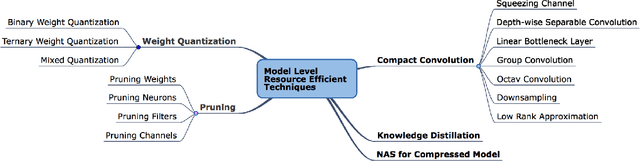
Deep learning is pervasive in our daily life, including self-driving cars, virtual assistants, social network services, healthcare services, face recognition, etc. However, deep neural networks demand substantial compute resources during training and inference. The machine learning community has mainly focused on model-level optimizations such as architectural compression of deep learning models, while the system community has focused on implementation-level optimization. In between, various arithmetic-level optimization techniques have been proposed in the arithmetic community. This article provides a survey on resource-efficient deep learning techniques in terms of model-, arithmetic-, and implementation-level techniques and identifies the research gaps for resource-efficient deep learning techniques across the three different level techniques. Our survey clarifies the influence from higher to lower-level techniques based on our resource-efficiency metric definition and discusses the future trend for resource-efficient deep learning research.