 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Scalable, Energy-Efficient Non-element-wise Matrix Multiplication on FPGA
Jul 02, 2024



Modern Neural Network (NN) architectures heavily rely on vast numbers of multiply-accumulate arithmetic operations, constituting the predominant computational cost. Therefore, this paper proposes a high-throughput, scalable and energy efficient non-element-wise matrix multiplication unit on FPGAs as a basic component of the NNs. We firstly streamline inter-layer and intra-layer redundancies of MADDNESS algorithm, a LUT-based approximate matrix multiplication, to design a fast, efficient scalable approximate matrix multiplication module termed "Approximate Multiplication Unit (AMU)". The AMU optimizes LUT-based matrix multiplications further through dedicated memory management and access design, decoupling computational overhead from input resolution and boosting FPGA-based NN accelerator efficiency significantly. The experimental results show that using our AMU achieves up to 9x higher throughput and 112x higher energy efficiency over the state-of-the-art solutions for the FPGA-based Quantised Neural Network (QNN) accelerators.
Multi-Technique Sequential Information Consistency For Dynamic Visual Place Recognition In Changing Environments
Jan 16, 2024Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance driven by different daily illumination, seasonal weather variations and diverse viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings, and therefore combining multiple techniques can achieve more reliable VPR performance. Present multi-method approaches either rely on online ground-truth information, which is often not available, or on brute-force technique combination, potentially lowering performance with high variance technique sets. Addressing these shortcomings, we propose a VPR system dubbed Multi-Sequential Information Consistency (MuSIC) which leverages sequential information to select the most cohesive technique on an online per-frame basis. For each technique in a set, MuSIC computes their respective sequential consistencies by analysing the frame-to-frame continuity of their top match candidates, which are then directly compared to select the optimal technique for the current query image. The use of sequential information to select between VPR methods results in an overall VPR performance increase across different benchmark datasets, while avoiding the need for extra ground-truth of the runtime environment.
Aggregating Multiple Bio-Inspired Image Region Classifiers For Effective And Lightweight Visual Place Recognition
Dec 20, 2023



Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While VPR techniques built upon a Convolutional Neural Network (CNN) backbone dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms equipped with low-end hardware. Recently, a lightweight VPR system based on multiple bio-inspired classifiers, dubbed DrosoNets, has been proposed, achieving great computational efficiency at the cost of reduced absolute place retrieval performance. In this work, we propose a novel multi-DrosoNet localization system, dubbed RegionDrosoNet, with significantly improved VPR performance, while preserving a low-computational profile. Our approach relies on specializing distinct groups of DrosoNets on differently sliced partitions of the original image, increasing extrinsic model differentiation. Furthermore, we introduce a novel voting module to combine the outputs of all DrosoNets into the final place prediction which considers multiple top refence candidates from each DrosoNet. RegionDrosoNet outperforms other lightweight VPR techniques when dealing with both appearance changes and viewpoint variations. Moreover, it competes with computationally expensive methods on some benchmark datasets at a small fraction of their online inference time.
Patch-DrosoNet: Classifying Image Partitions With Fly-Inspired Models For Lightweight Visual Place Recognition
May 09, 2023



Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While Convolution Neural Networks (CNNs) currently dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms with budget or size constraints. This has spurred the development of lightweight algorithms, such as DrosoNet, which employs a voting system based on multiple bio-inspired units. In this paper, we present a novel training approach for DrosoNet, wherein separate models are trained on distinct regions of a reference image, allowing them to specialize in the visual features of that specific section. Additionally, we introduce a convolutional-like prediction method, in which each DrosoNet unit generates a set of place predictions for each portion of the query image. These predictions are then combined using the previously introduced voting system. Our approach significantly improves upon the VPR performance of previous work while maintaining an extremely compact and lightweight algorithm, making it suitable for resource-constrained platforms.
A-MuSIC: An Adaptive Ensemble System For Visual Place Recognition In Changing Environments
Mar 24, 2023



Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance under different illumination throughout the day, with seasonal weather and when observed from different viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings. As a result, VPR systems combining multiple techniques achieve more reliable VPR performance in changing environments, at the cost of higher computational loads. Addressing this shortcoming, we propose an adaptive VPR system dubbed Adaptive Multi-Self Identification and Correction (A-MuSIC). We start by developing a method to collect information of the runtime performance of a VPR technique by analysing the frame-to-frame continuity of matched queries. We then demonstrate how to operate the method on a static ensemble of techniques, generating data on which techniques are contributing the most for the current environment. A-MuSIC uses the collected information to both select a minimal subset of techniques and to decide when a re-selection is required during navigation. A-MuSIC matches or beats state-of-the-art VPR performance across all tested benchmark datasets while maintaining its computational load on par with individual techniques.
Merging Classification Predictions with Sequential Information for Lightweight Visual Place Recognition in Changing Environments
Oct 03, 2022
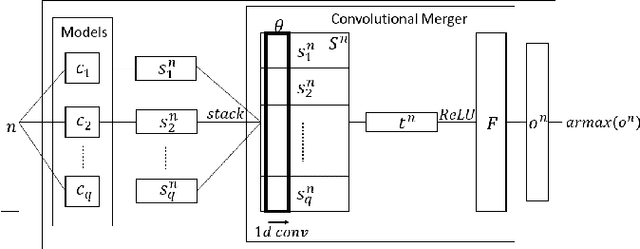
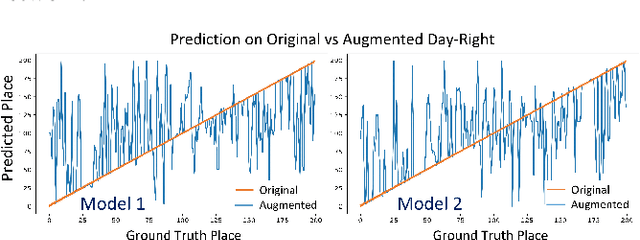

Low-overhead visual place recognition (VPR) is a highly active research topic. Mobile robotics applications often operate under low-end hardware, and even more hardware capable systems can still benefit from freeing up onboard system resources for other navigation tasks. This work addresses lightweight VPR by proposing a novel system based on the combination of binary-weighted classifier networks with a one-dimensional convolutional network, dubbed merger. Recent work in fusing multiple VPR techniques has mainly focused on increasing VPR performance, with computational efficiency not being highly prioritized. In contrast, we design our technique prioritizing low inference times, taking inspiration from the machine learning literature where the efficient combination of classifiers is a heavily researched topic. Our experiments show that the merger achieves inference times as low as 1 millisecond, being significantly faster than other well-established lightweight VPR techniques, while achieving comparable or superior VPR performance on several visual changes such as seasonal variations and viewpoint lateral shifts.
Highly-Efficient Binary Neural Networks for Visual Place Recognition
Feb 24, 2022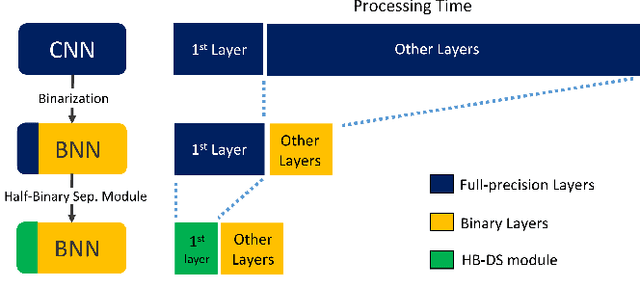
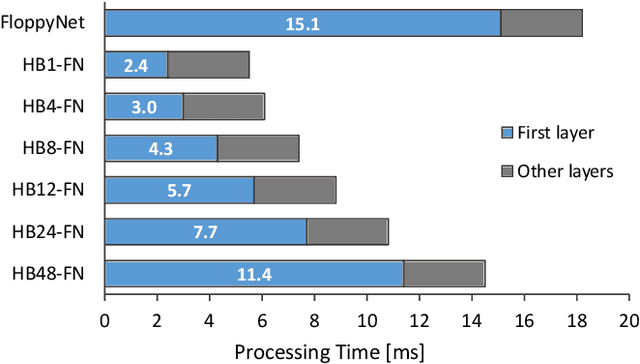

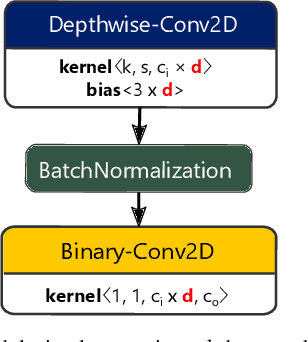
VPR is a fundamental task for autonomous navigation as it enables a robot to localize itself in the workspace when a known location is detected. Although accuracy is an essential requirement for a VPR technique, computational and energy efficiency are not less important for real-world applications. CNN-based techniques archive state-of-the-art VPR performance but are computationally intensive and energy demanding. Binary neural networks (BNN) have been recently proposed to address VPR efficiently. Although a typical BNN is an order of magnitude more efficient than a CNN, its processing time and energy usage can be further improved. In a typical BNN, the first convolution is not completely binarized for the sake of accuracy. Consequently, the first layer is the slowest network stage, requiring a large share of the entire computational effort. This paper presents a class of BNNs for VPR that combines depthwise separable factorization and binarization to replace the first convolutional layer to improve computational and energy efficiency. Our best model achieves state-of-the-art VPR performance while spending considerably less time and energy to process an image than a BNN using a non-binary convolution as a first stage.
An Efficient and Scalable Collection of Fly-inspired Voting Units for Visual Place Recognition in Changing Environments
Sep 22, 2021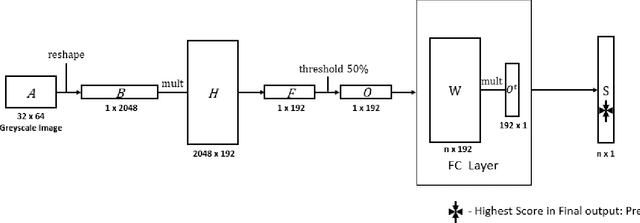


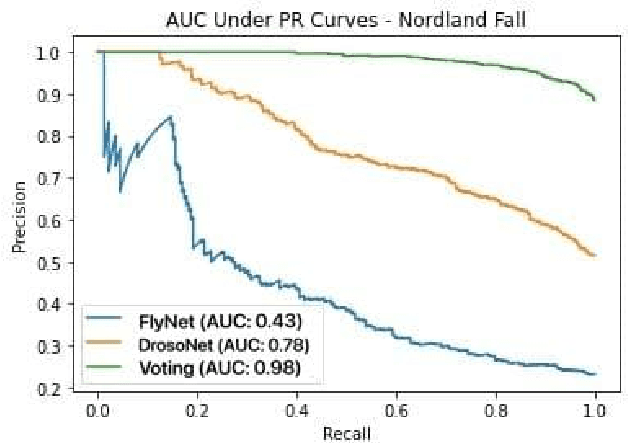
State-of-the-art visual place recognition performance is currently being achieved utilizing deep learning based approaches. Despite the recent efforts in designing lightweight convolutional neural network based models, these can still be too expensive for the most hardware restricted robot applications. Low-overhead VPR techniques would not only enable platforms equipped with low-end, cheap hardware but also reduce computation on more powerful systems, allowing these resources to be allocated for other navigation tasks. In this work, our goal is to provide an algorithm of extreme compactness and efficiency while achieving state-of-the-art robustness to appearance changes and small point-of-view variations. Our first contribution is DrosoNet, an exceptionally compact model inspired by the odor processing abilities of the fruit fly, Drosophyla melanogaster. Our second and main contribution is a voting mechanism that leverages multiple small and efficient classifiers to achieve more robust and consistent VPR compared to a single one. We use DrosoNet as the baseline classifier for the voting mechanism and evaluate our models on five benchmark datasets, assessing moderate to extreme appearance changes and small to moderate viewpoint variations. We then compare the proposed algorithms to state-of-the-art methods, both in terms of precision-recall AUC results and computational efficiency.
Scene Retrieval for Contextual Visual Mapping
Feb 25, 2021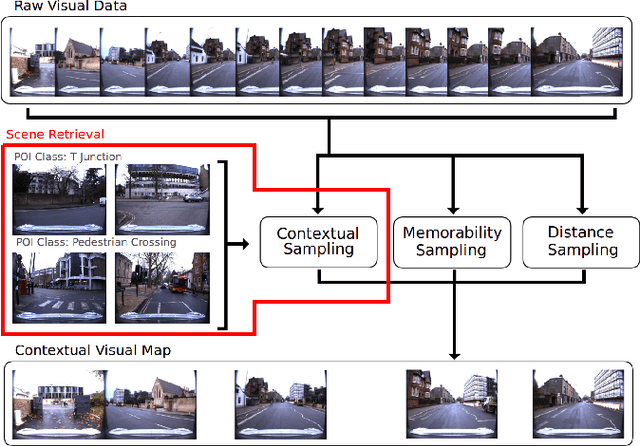

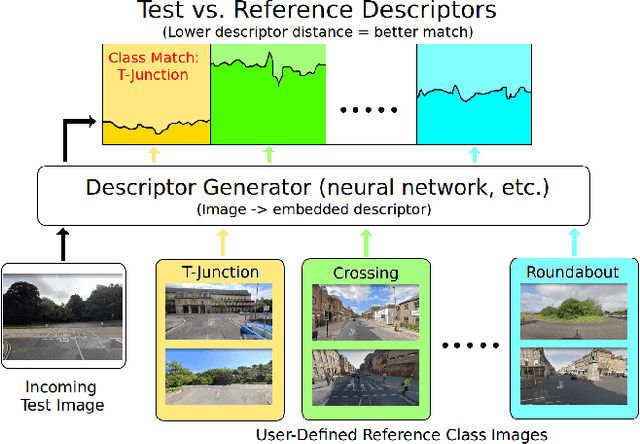
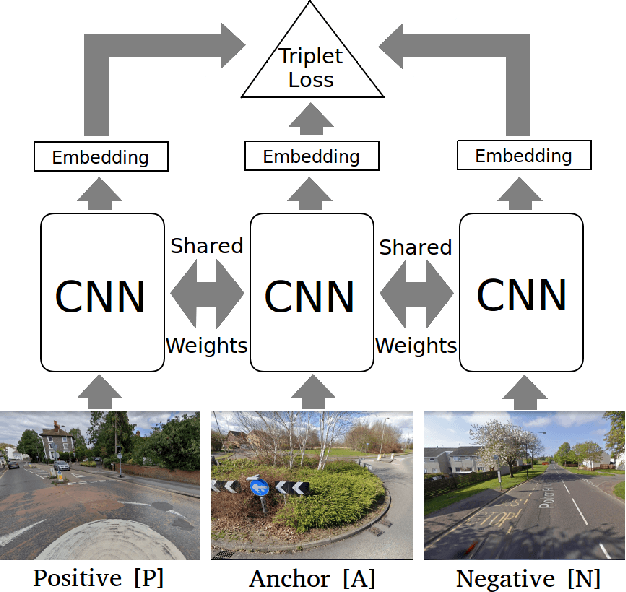
Visual navigation localizes a query place image against a reference database of place images, also known as a `visual map'. Localization accuracy requirements for specific areas of the visual map, `scene classes', vary according to the context of the environment and task. State-of-the-art visual mapping is unable to reflect these requirements by explicitly targetting scene classes for inclusion in the map. Four different scene classes, including pedestrian crossings and stations, are identified in each of the Nordland and St. Lucia datasets. Instead of re-training separate scene classifiers which struggle with these overlapping scene classes we make our first contribution: defining the problem of `scene retrieval'. Scene retrieval extends image retrieval to classification of scenes defined at test time by associating a single query image to reference images of scene classes. Our second contribution is a triplet-trained convolutional neural network (CNN) to address this problem which increases scene classification accuracy by up to 7% against state-of-the-art networks pre-trained for scene recognition. The second contribution is an algorithm `DMC' that combines our scene classification with distance and memorability for visual mapping. Our analysis shows that DMC includes 64% more images of our chosen scene classes in a visual map than just using distance interval mapping. State-of-the-art visual place descriptors AMOS-Net, Hybrid-Net and NetVLAD are finally used to show that DMC improves scene class localization accuracy by a mean of 3% and localization accuracy of the remaining map images by a mean of 10% across both datasets.
Improving Visual Place Recognition Performance by Maximising Complementarity
Feb 16, 2021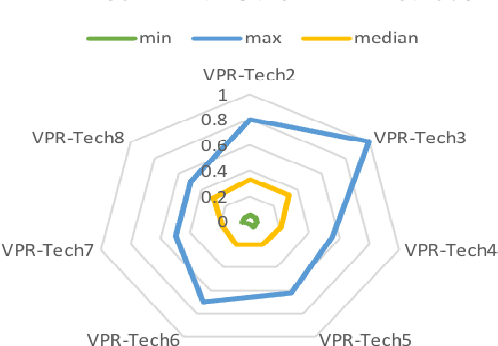
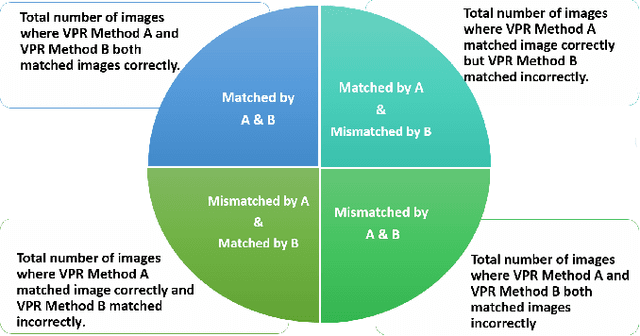
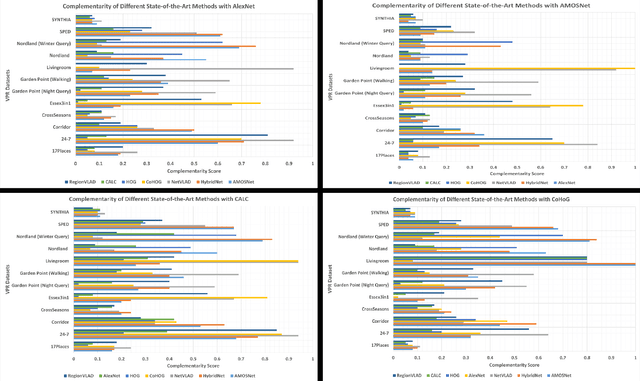
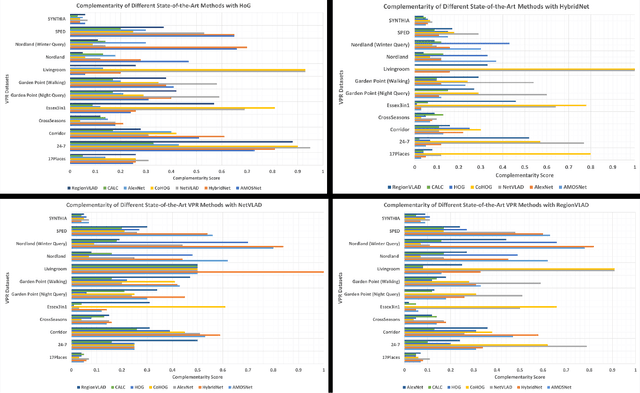
Visual place recognition (VPR) is the problem of recognising a previously visited location using visual information. Many attempts to improve the performance of VPR methods have been made in the literature. One approach that has received attention recently is the multi-process fusion where different VPR methods run in parallel and their outputs are combined in an effort to achieve better performance. The multi-process fusion, however, does not have a well-defined criterion for selecting and combining different VPR methods from a wide range of available options. To the best of our knowledge, this paper investigates the complementarity of state-of-the-art VPR methods systematically for the first time and identifies those combinations which can result in better performance. The paper presents a well-defined framework which acts as a sanity check to find the complementarity between two techniques by utilising a McNemar's test-like approach. The framework allows estimation of upper and lower complementarity bounds for the VPR techniques to be combined, along with an estimate of maximum VPR performance that may be achieved. Based on this framework, results are presented for eight state-of-the-art VPR methods on ten widely-used VPR datasets showing the potential of different combinations of techniques for achieving better performance.