 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Multiple Bio-Inspired Image Region Classifiers For Effective And Lightweight Visual Place Recognition
Dec 20, 2023



Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While VPR techniques built upon a Convolutional Neural Network (CNN) backbone dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms equipped with low-end hardware. Recently, a lightweight VPR system based on multiple bio-inspired classifiers, dubbed DrosoNets, has been proposed, achieving great computational efficiency at the cost of reduced absolute place retrieval performance. In this work, we propose a novel multi-DrosoNet localization system, dubbed RegionDrosoNet, with significantly improved VPR performance, while preserving a low-computational profile. Our approach relies on specializing distinct groups of DrosoNets on differently sliced partitions of the original image, increasing extrinsic model differentiation. Furthermore, we introduce a novel voting module to combine the outputs of all DrosoNets into the final place prediction which considers multiple top refence candidates from each DrosoNet. RegionDrosoNet outperforms other lightweight VPR techniques when dealing with both appearance changes and viewpoint variations. Moreover, it competes with computationally expensive methods on some benchmark datasets at a small fraction of their online inference time.
DisplaceNet: Recognising Displaced People from Images by Exploiting Dominance Level
May 03, 2019
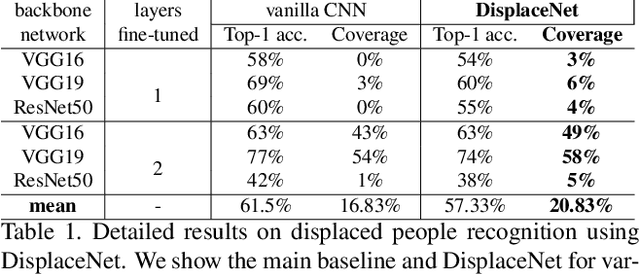


Every year millions of men, women and children are forced to leave their homes and seek refuge from wars, human rights violations, persecution, and natural disasters. The number of forcibly displaced people came at a record rate of 44,400 every day throughout 2017, raising the cumulative total to 68.5 million at the years end, overtaken the total population of the United Kingdom. Up to 85% of the forcibly displaced find refuge in low- and middle-income countries, calling for increased humanitarian assistance worldwide. To reduce the amount of manual labour required for human-rights-related image analysis, we introduce DisplaceNet, a novel model which infers potential displaced people from images by integrating the control level of the situation and conventional convolutional neural network (CNN) classifier into one framework for image classification. Experimental results show that DisplaceNet achieves up to 4% coverage-the proportion of a data set for which a classifier is able to produce a prediction-gain over the sole use of a CNN classifier. Our dataset, codes and trained models will be available online at https://github.com/GKalliatakis/DisplaceNet.
GET-AID: Visual Recognition of Human Rights Abuses via Global Emotional Traits
Feb 11, 2019


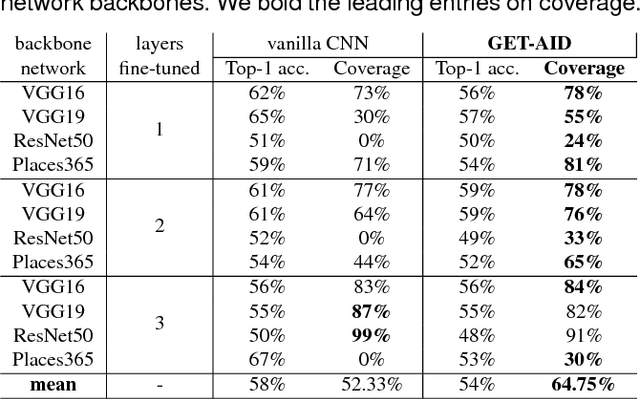
In the era of social media and big data, the use of visual evidence to document conflict and human rights abuse has become an important element for human rights organizations and advocates. In this paper, we address the task of detecting two types of human rights abuses in challenging, everyday photos: (1) child labour, and (2) displaced populations. We propose a novel model that is driven by a human-centric approach. Our hypothesis is that the emotional state of a person -- how positive or pleasant an emotion is, and the control level of the situation by the person -- are powerful cues for perceiving potential human rights violations. To exploit these cues, our model learns to predict global emotional traits over a given image based on the joint analysis of every detected person and the whole scene. By integrating these predictions with a data-driven convolutional neural network (CNN) classifier, our system efficiently infers potential human rights abuses in a clean, end-to-end system we call GET-AID (from Global Emotional Traits for Abuse IDentification). Extensive experiments are performed to verify our method on the recently introduced subset of Human Rights Archive (HRA) dataset (2 violation categories with the same number of positive and negative samples), where we show quantitatively compelling results. Compared with previous works and the sole use of a CNN classifier, this paper improves the coverage up to 23.73% for child labour and 57.21% for displaced populations. Our dataset, codes and trained models are available online at https://github.com/GKalliatakis/GET-AID.
Detection of Human Rights Violations in Images: Can Convolutional Neural Networks help?
Mar 16, 2017
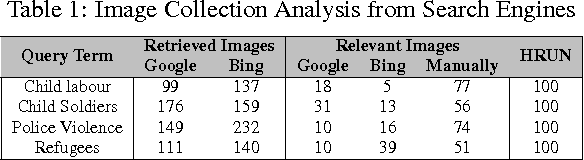
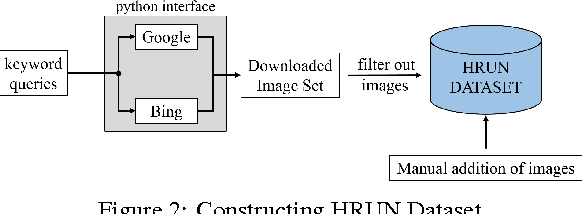
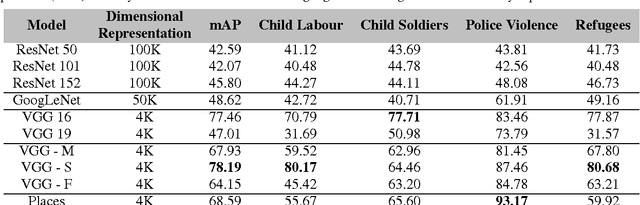
After setting the performance benchmarks for image, video, speech and audio processing, deep convolutional networks have been core to the greatest advances in image recognition tasks in recent times. This raises the question of whether there are any benefit in targeting these remarkable deep architectures with the unattempted task of recognising human rights violations through digital images. Under this perspective, we introduce a new, well-sampled human rights-centric dataset called Human Rights Understanding (HRUN). We conduct a rigorous evaluation on a common ground by combining this dataset with different state-of-the-art deep convolutional architectures in order to achieve recognition of human rights violations. Experimental results on the HRUN dataset have shown that the best performing CNN architectures can achieve up to 88.10\% mean average precision. Additionally, our experiments demonstrate that increasing the size of the training samples is crucial for achieving an improvement on mean average precision principally when utilising very deep networks.