 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation and Ranking of Different Voting Schemes for Improved Visual Place Recognition
May 09, 2023

Visual Place Recognition has recently seen a surge of endeavours utilizing different ensemble approaches to improve VPR performance. Ideas like multi-process fusion or switching involve combining different VPR techniques together, utilizing different strategies. One major aspect often common to many of these strategies is voting. Voting is widely used in many ensemble methods, so it is potentially a relevant subject to explore in terms of its application and significance for improving VPR performance. This paper attempts to looks into detail and analyze a variety of voting schemes to evaluate which voting technique is optimal for an ensemble VPR set up. We take inspiration from a variety of voting schemes that exist and are widely employed in other research fields such as politics and sociology. The idea is inspired by an observation that different voting methods result in different outcomes for the same type of data and each voting scheme is utilized for specific cases in different academic fields. Some of these voting schemes include Condorcet voting, Broda Count and Plurality voting. Voting employed in any aspect requires that a fair system be established, that outputs the best and most favourable results which in our case would involve improving VPR performance. We evaluate some of these voting techniques in a standardized testing of different VPR techniques, using a variety of VPR data sets. We aim to determine whether a single optimal voting scheme exists or, much like in other fields of research, the selection of a voting technique is relative to its application and environment. We also aim to propose a ranking of these different voting methods from best to worst according to our results as this will allow for better selection of voting schemes.
Visual Place Recognition with Low-Resolution Images
May 09, 2023



Images incorporate a wealth of information from a robot's surroundings. With the widespread availability of compact cameras, visual information has become increasingly popular for addressing the localisation problem, which is then termed as Visual Place Recognition (VPR). While many applications use high-resolution cameras and high-end systems to achieve optimal place-matching performance, low-end commercial systems face limitations due to resource constraints and relatively low-resolution and low-quality cameras. In this paper, we analyse the effects of image resolution on the accuracy and robustness of well-established handcrafted VPR pipelines. Handcrafted designs have low computational demands and can adapt to flexible image resolutions, making them a suitable approach to scale to any image source and to operate under resource limitations. This paper aims to help academic researchers and companies in the hardware and software industry co-design VPR solutions and expand the use of VPR algorithms in commercial products.
A Complementarity-Based Switch-Fuse System for Improved Visual Place Recognition
Mar 01, 2023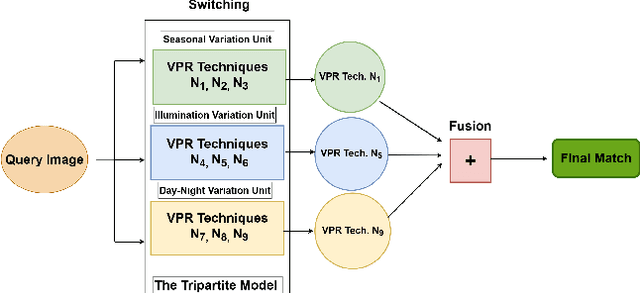
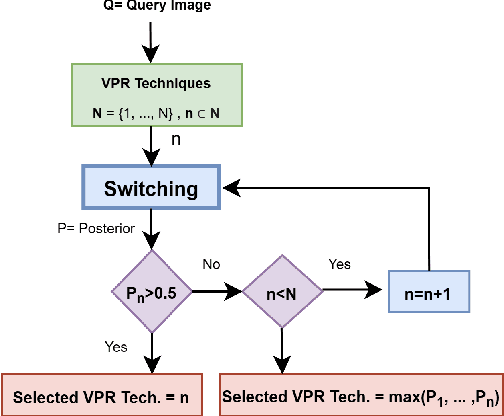
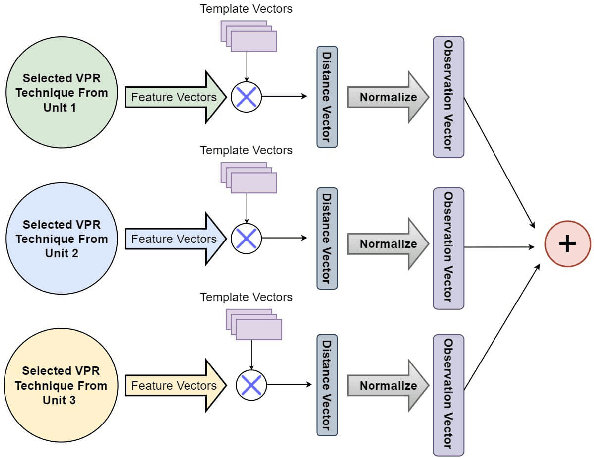

Recently several fusion and switching based approaches have been presented to solve the problem of Visual Place Recognition. In spite of these systems demonstrating significant boost in VPR performance they each have their own set of limitations. The multi-process fusion systems usually involve employing brute force and running all available VPR techniques simultaneously while the switching method attempts to negate this practise by only selecting the best suited VPR technique for given query image. But switching does fail at times when no available suitable technique can be identified. An innovative solution would be an amalgamation of the two otherwise discrete approaches to combine their competitive advantages while negating their shortcomings. The proposed, Switch-Fuse system, is an interesting way to combine both the robustness of switching VPR techniques based on complementarity and the force of fusing the carefully selected techniques to significantly improve performance. Our system holds a structure superior to the basic fusion methods as instead of simply fusing all or any random techniques, it is structured to first select the best possible VPR techniques for fusion, according to the query image. The system combines two significant processes, switching and fusing VPR techniques, which together as a hybrid model substantially improve performance on all major VPR data sets illustrated using PR curves.
Data-Efficient Sequence-Based Visual Place Recognition with Highly Compressed JPEG Images
Feb 26, 2023



Visual Place Recognition (VPR) is a fundamental task that allows a robotic platform to successfully localise itself in the environment. For decentralised VPR applications where the visual data has to be transmitted between several agents, the communication channel may restrict the localisation process when limited bandwidth is available. JPEG is an image compression standard that can employ high compression ratios to facilitate lower data transmission for VPR applications. However, when applying high levels of JPEG compression, both the image clarity and size are drastically reduced. In this paper, we incorporate sequence-based filtering in a number of well-established, learnt and non-learnt VPR techniques to overcome the performance loss resulted from introducing high levels of JPEG compression. The sequence length that enables 100% place matching performance is reported and an analysis of the amount of data required for each VPR technique to perform the transfer on the entire spectrum of JPEG compression is provided. Moreover, the time required by each VPR technique to perform place matching is investigated, on both uniformly and non-uniformly JPEG compressed data. The results show that it is beneficial to use a highly compressed JPEG dataset with an increased sequence length, as similar levels of VPR performance are reported at a significantly reduced bandwidth. The results presented in this paper also emphasize that there is a trade-off between the amount of data transferred and the total time required to perform VPR. Our experiments also suggest that is often favourable to compress the query images to the same quality of the map, as more efficient place matching can be performed. The experiments are conducted on several VPR datasets, under mild to extreme JPEG compression.
Data Efficient Visual Place Recognition Using Extremely JPEG-Compressed Images
Sep 17, 2022
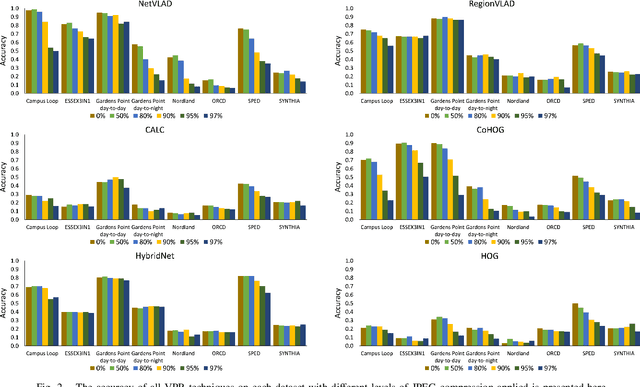
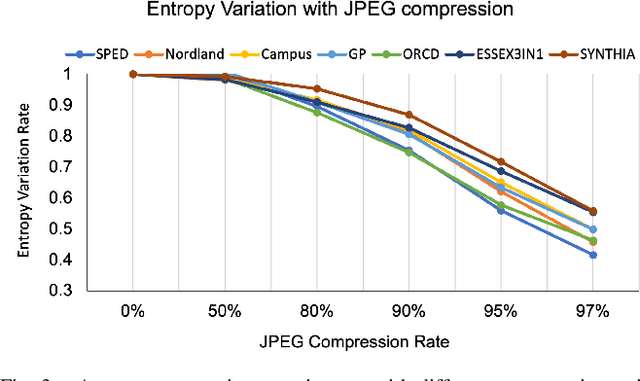

Visual Place Recognition (VPR) is the ability of a robotic platform to correctly interpret visual stimuli from its on-board cameras in order to determine whether it is currently located in a previously visited place, despite different viewpoint, illumination and appearance changes. JPEG is a widely used image compression standard that is capable of significantly reducing the size of an image at the cost of image clarity. For applications where several robotic platforms are simultaneously deployed, the visual data gathered must be transmitted remotely between each robot. Hence, JPEG compression can be employed to drastically reduce the amount of data transmitted over a communication channel, as working with limited bandwidth for VPR can be proven to be a challenging task. However, the effects of JPEG compression on the performance of current VPR techniques have not been previously studied. For this reason, this paper presents an in-depth study of JPEG compression in VPR related scenarios. We use a selection of well-established VPR techniques on 8 datasets with various amounts of compression applied. We show that by introducing compression, the VPR performance is drastically reduced, especially in the higher spectrum of compression. To overcome the negative effects of JPEG compression on the VPR performance, we present a fine-tuned CNN which is optimized for JPEG compressed data and show that it performs more consistently with the image transformations detected in extremely compressed JPEG images.
SwitchHit: A Probabilistic, Complementarity-Based Switching System for Improved Visual Place Recognition in Changing Environments
Mar 01, 2022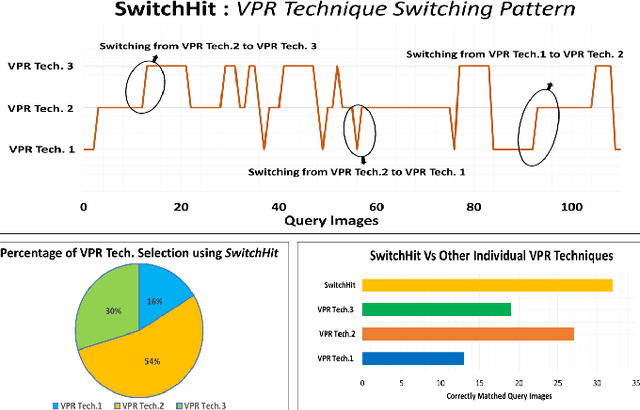
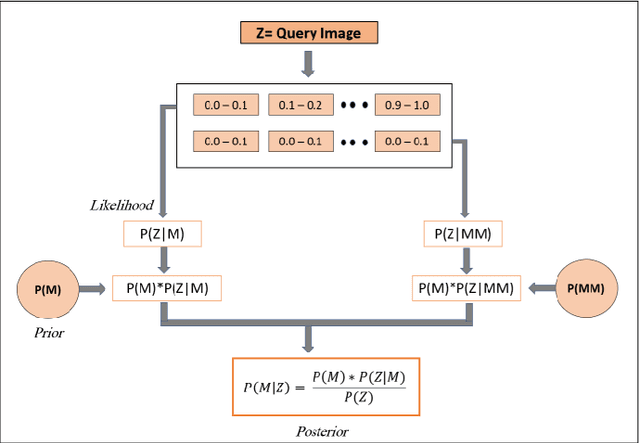
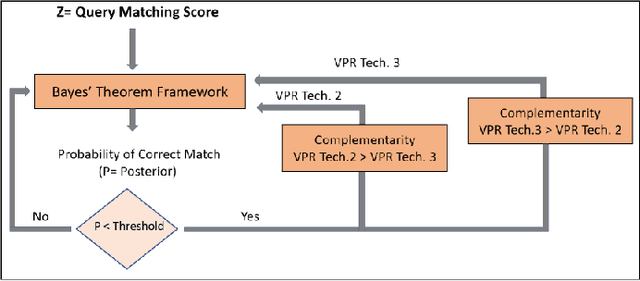
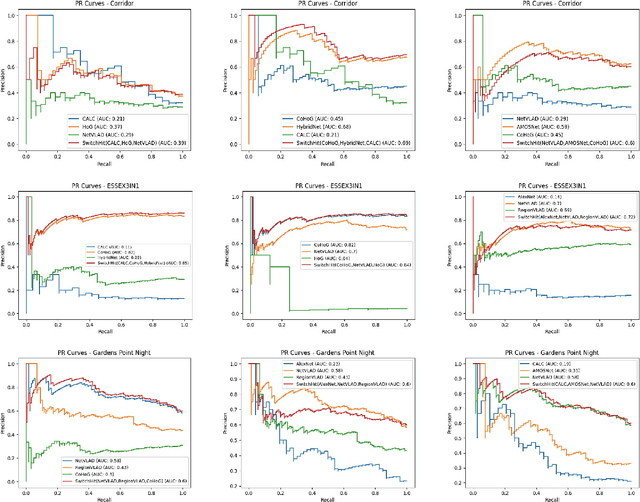
Visual place recognition (VPR), a fundamental task in computer vision and robotics, is the problem of identifying a place mainly based on visual information. Viewpoint and appearance changes, such as due to weather and seasonal variations, make this task challenging. Currently, there is no universal VPR technique that can work in all types of environments, on a variety of robotic platforms, and under a wide range of viewpoint and appearance changes. Recent work has shown the potential of combining different VPR methods intelligently by evaluating complementarity for some specific VPR datasets to achieve better performance. This, however, requires ground truth information (correct matches) which is not available when a robot is deployed in a real-world scenario. Moreover, running multiple VPR techniques in parallel may be prohibitive for resource-constrained embedded platforms. To overcome these limitations, this paper presents a probabilistic complementarity based switching VPR system, SwitchHit. Our proposed system consists of multiple VPR techniques, however, it does not simply run all techniques at once, rather predicts the probability of correct match for an incoming query image and dynamically switches to another complementary technique if the probability of correctly matching the query is below a certain threshold. This innovative use of multiple VPR techniques allow our system to be more efficient and robust than other combined VPR approaches employing brute force and running multiple VPR techniques at once. Thus making it more suitable for resource constrained embedded systems and achieving an overall superior performance from what any individual VPR method in the system could have by achieved running independently.
Using Machine Learning for Anomaly Detection on a System-on-Chip under Gamma Radiation
Jan 05, 2022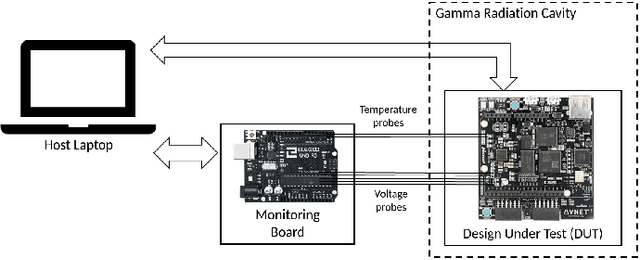
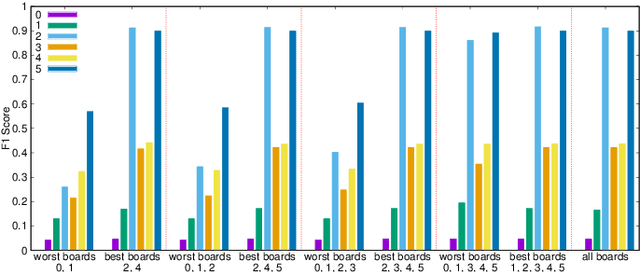
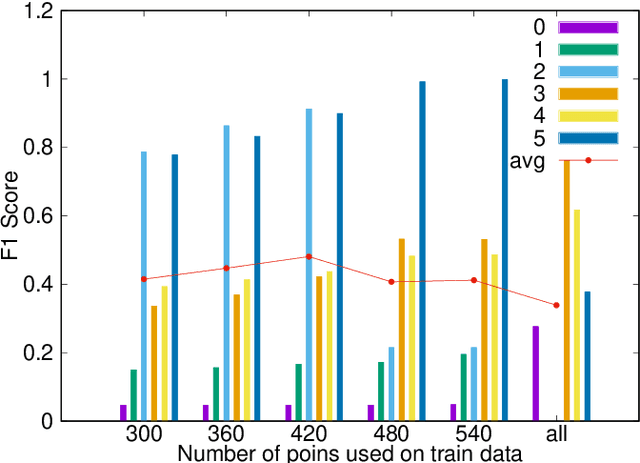
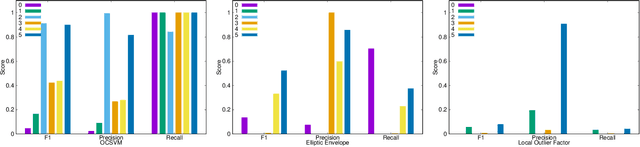
The emergence of new nanoscale technologies has imposed significant challenges to designing reliable electronic systems in radiation environments. A few types of radiation like Total Ionizing Dose (TID) effects often cause permanent damages on such nanoscale electronic devices, and current state-of-the-art technologies to tackle TID make use of expensive radiation-hardened devices. This paper focuses on a novel and different approach: using machine learning algorithms on consumer electronic level Field Programmable Gate Arrays (FPGAs) to tackle TID effects and monitor them to replace before they stop working. This condition has a research challenge to anticipate when the board results in a total failure due to TID effects. We observed internal measurements of the FPGA boards under gamma radiation and used three different anomaly detection machine learning (ML) algorithms to detect anomalies in the sensor measurements in a gamma-radiated environment. The statistical results show a highly significant relationship between the gamma radiation exposure levels and the board measurements. Moreover, our anomaly detection results have shown that a One-Class Support Vector Machine with Radial Basis Function Kernel has an average Recall score of 0.95. Also, all anomalies can be detected before the boards stop working.
A Benchmark Comparison of Visual Place Recognition Techniques for Resource-Constrained Embedded Platforms
Sep 22, 2021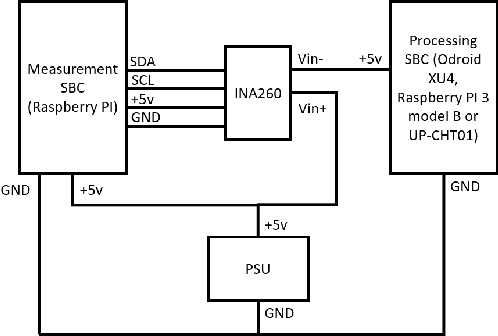
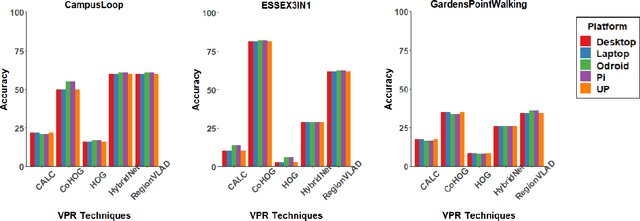
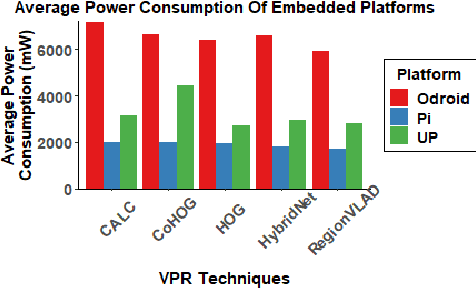
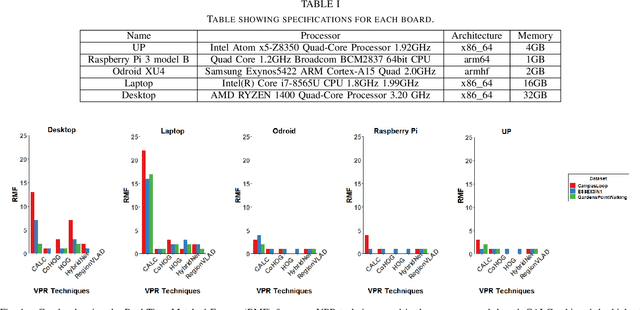
Visual Place Recognition (VPR) has been a subject of significant research over the last 15 to 20 years. VPR is a fundamental task for autonomous navigation as it enables self-localization within an environment. Although robots are often equipped with resource-constrained hardware, the computational requirements of and effects on VPR techniques have received little attention. In this work, we present a hardware-focused benchmark evaluation of a number of state-of-the-art VPR techniques on public datasets. We consider popular single board computers, including ODroid, UP and Raspberry Pi 3, in addition to a commodity desktop and laptop for reference. We present our analysis based on several key metrics, including place-matching accuracy, image encoding time, descriptor matching time and memory needs. Key questions addressed include: (1) How does the performance accuracy of a VPR technique change with processor architecture? (2) How does power consumption vary for different VPR techniques and embedded platforms? (3) How much does descriptor size matter in comparison to today's embedded platforms' storage? (4) How does the performance of a high-end platform relate to an on-board low-end embedded platform for VPR? The extensive analysis and results in this work serve not only as a benchmark for the VPR community, but also provide useful insights for real-world adoption of VPR applications.
Sequence-Based Filtering for Visual Route-Based Navigation: Analysing the Benefits, Trade-offs and Design Choices
Mar 02, 2021
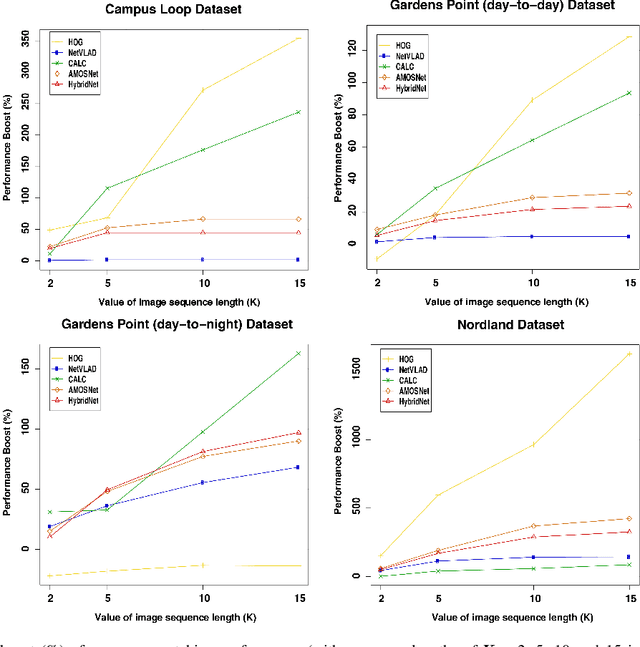
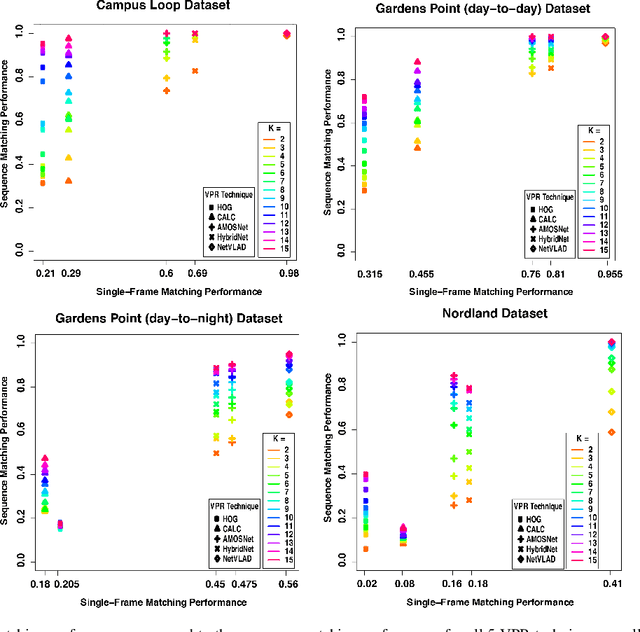
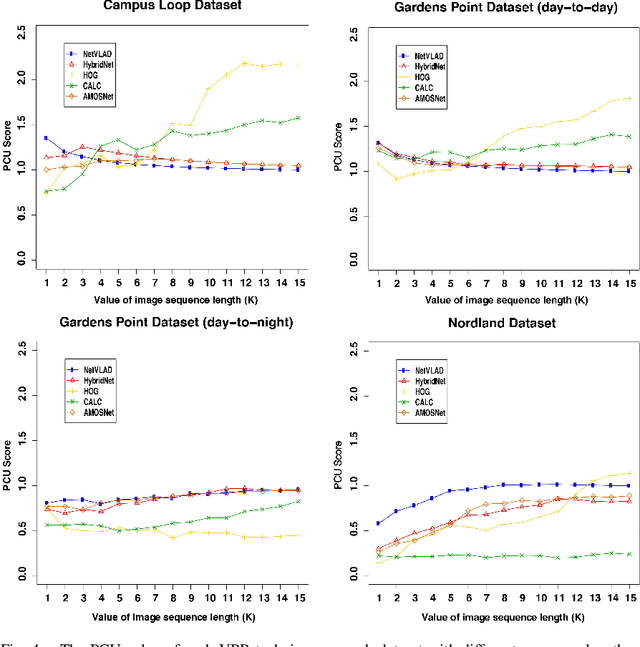
Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place using visual information under environmental, viewpoint and appearance changes. An emerging trend in VPR is the use of sequence-based filtering methods on top of single-frame-based place matching techniques for route-based navigation. The combination leads to varying levels of potential place matching performance boosts at increased computational costs. This raises a number of interesting research questions: How does performance boost (due to sequential filtering) vary along the entire spectrum of single-frame-based matching methods? How does sequence matching length affect the performance curve? Which specific combinations provide a good trade-off between performance and computation? However, there is lack of previous work looking at these important questions and most of the sequence-based filtering work to date has been used without a systematic approach. To bridge this research gap, this paper conducts an in-depth investigation of the relationship between the performance of single-frame-based place matching techniques and the use of sequence-based filtering on top of those methods. It analyzes individual trade-offs, properties and limitations for different combinations of single-frame-based and sequential techniques. A number of state-of-the-art VPR methods and widely used public datasets are utilized to present the findings that contain a number of meaningful insights for the VPR community.
ConvSequential-SLAM: A Sequence-based, Training-less Visual Place Recognition Technique for Changing Environments
Sep 28, 2020



Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place under changing viewpoints and appearances. A large number of handcrafted and deep-learning-based VPR techniques exist, where the former suffer from appearance changes and the latter have significant computational needs. In this paper, we present a new handcrafted VPR technique that achieves state-of-the-art place matching performance under challenging conditions. Our technique combines the best of 2 existing trainingless VPR techniques, SeqSLAM and CoHOG, which are each robust to conditional and viewpoint changes, respectively. This blend, namely ConvSequential-SLAM, utilises sequential information and block-normalisation to handle appearance changes, while using regional-convolutional matching to achieve viewpoint-invariance. We analyse content-overlap in-between query frames to find a minimum sequence length, while also re-using the image entropy information for environment-based sequence length tuning. State-of-the-art performance is reported in contrast to 8 contemporary VPR techniques on 4 public datasets. Qualitative insights and an ablation study on sequence length are also provided.