 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Channel to Rule Them All: Rethinking Input Representation for Visual Place Recognition
May 31, 2026Visual Place Recognition (VPR) is fundamental to long-term robot localization and SLAM, yet current systems overwhelmingly rely on RGB input, implicitly assuming color is necessary for global place recognition. We challenge this assumption, investigating the role of chromatic information across training regimes, model architectures and standard benchmarks under real-world appearance variation. We find that grayscale matches RGB performance generally and outperforms it under severe appearance shifts where color invariance is insufficiently learned, while color provides meaningful gains only where persistent and discriminative chromatic cues are present. Across selected benchmarks, a fully gray-trained MixVPR model achieves an average 82.4% Recall@1 compared to 81.2% for its RGB counterpart. In some cases, lightweight grayscale variants with 60% fewer parameters can outperform heavier RGB models. Grayscale further offers practical advantages in storage, bandwidth and alignment with resource-constrained systems. We conclude that for global VPR where scenes vary across illumination, weather, season and setting, color contributes minimally, and grayscale alone is sufficient for reliable place recognition.
Assessing the Geolocation Capabilities, Limitations and Societal Risks of Generative Vision-Language Models
Aug 27, 2025Geo-localization is the task of identifying the location of an image using visual cues alone. It has beneficial applications, such as improving disaster response, enhancing navigation, and geography education. Recently, Vision-Language Models (VLMs) are increasingly demonstrating capabilities as accurate image geo-locators. This brings significant privacy risks, including those related to stalking and surveillance, considering the widespread uses of AI models and sharing of photos on social media. The precision of these models is likely to improve in the future. Despite these risks, there is little work on systematically evaluating the geolocation precision of Generative VLMs, their limits and potential for unintended inferences. To bridge this gap, we conduct a comprehensive assessment of the geolocation capabilities of 25 state-of-the-art VLMs on four benchmark image datasets captured in diverse environments. Our results offer insight into the internal reasoning of VLMs and highlight their strengths, limitations, and potential societal risks. Our findings indicate that current VLMs perform poorly on generic street-level images yet achieve notably high accuracy (61\%) on images resembling social media content, raising significant and urgent privacy concerns.
VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization
Jul 23, 2025Geo-localization from a single image at planet scale (essentially an advanced or extreme version of the kidnapped robot problem) is a fundamental and challenging task in applications such as navigation, autonomous driving and disaster response due to the vast diversity of locations, environmental conditions, and scene variations. Traditional retrieval-based methods for geo-localization struggle with scalability and perceptual aliasing, while classification-based approaches lack generalization and require extensive training data. Recent advances in vision-language models (VLMs) offer a promising alternative by leveraging contextual understanding and reasoning. However, while VLMs achieve high accuracy, they are often prone to hallucinations and lack interpretability, making them unreliable as standalone solutions. In this work, we propose a novel hybrid geo-localization framework that combines the strengths of VLMs with retrieval-based visual place recognition (VPR) methods. Our approach first leverages a VLM to generate a prior, effectively guiding and constraining the retrieval search space. We then employ a retrieval step, followed by a re-ranking mechanism that selects the most geographically plausible matches based on feature similarity and proximity to the initially estimated coordinates. We evaluate our approach on multiple geo-localization benchmarks and show that it consistently outperforms prior state-of-the-art methods, particularly at street (up to 4.51%) and city level (up to 13.52%). Our results demonstrate that VLM-generated geographic priors in combination with VPR lead to scalable, robust, and accurate geo-localization systems.
TAT-VPR: Ternary Adaptive Transformer for Dynamic and Efficient Visual Place Recognition
May 22, 2025TAT-VPR is a ternary-quantized transformer that brings dynamic accuracy-efficiency trade-offs to visual SLAM loop-closure. By fusing ternary weights with a learned activation-sparsity gate, the model can control computation by up to 40% at run-time without degrading performance (Recall@1). The proposed two-stage distillation pipeline preserves descriptor quality, letting it run on micro-UAV and embedded SLAM stacks while matching state-of-the-art localization accuracy.
TeTRA-VPR: A Ternary Transformer Approach for Compact Visual Place Recognition
Mar 04, 2025



Visual Place Recognition (VPR) localizes a query image by matching it against a database of geo-tagged reference images, making it essential for navigation and mapping in robotics. Although Vision Transformer (ViT) solutions deliver high accuracy, their large models often exceed the memory and compute budgets of resource-constrained platforms such as drones and mobile robots. To address this issue, we propose TeTRA, a ternary transformer approach that progressively quantizes the ViT backbone to 2-bit precision and binarizes its final embedding layer, offering substantial reductions in model size and latency. A carefully designed progressive distillation strategy preserves the representational power of a full-precision teacher, allowing TeTRA to retain or even surpass the accuracy of uncompressed convolutional counterparts, despite using fewer resources. Experiments on standard VPR benchmarks demonstrate that TeTRA reduces memory consumption by up to 69% compared to efficient baselines, while lowering inference latency by 35%, with either no loss or a slight improvement in recall@1. These gains enable high-accuracy VPR on power-constrained, memory-limited robotic platforms, making TeTRA an appealing solution for real-world deployment.
Image-based Geo-localization for Robotics: Are Black-box Vision-Language Models there yet?
Jan 28, 2025



The advances in Vision-Language models (VLMs) offer exciting opportunities for robotic applications involving image geo-localization, the problem of identifying the geo-coordinates of a place based on visual data only. Recent research works have focused on using a VLM as embeddings extractor for geo-localization, however, the most sophisticated VLMs may only be available as black boxes that are accessible through an API, and come with a number of limitations: there is no access to training data, model features and gradients; retraining is not possible; the number of predictions may be limited by the API; training on model outputs is often prohibited; and queries are open-ended. The utilization of a VLM as a stand-alone, zero-shot geo-localization system using a single text-based prompt is largely unexplored. To bridge this gap, this paper undertakes the first systematic study, to the best of our knowledge, to investigate the potential of some of the state-of-the-art VLMs as stand-alone, zero-shot geo-localization systems in a black-box setting with realistic constraints. We consider three main scenarios for this thorough investigation: a) fixed text-based prompt; b) semantically-equivalent text-based prompts; and c) semantically-equivalent query images. We also take into account the auto-regressive and probabilistic generation process of the VLMs when investigating their utility for geo-localization task by using model consistency as a metric in addition to traditional accuracy. Our work provides new insights in the capabilities of different VLMs for the above-mentioned scenarios.
On Motion Blur and Deblurring in Visual Place Recognition
Dec 10, 2024



Visual Place Recognition (VPR) in mobile robotics enables robots to localize themselves by recognizing previously visited locations using visual data. While the reliability of VPR methods has been extensively studied under conditions such as changes in illumination, season, weather and viewpoint, the impact of motion blur is relatively unexplored despite its relevance not only in rapid motion scenarios but also in low-light conditions where longer exposure times are necessary. Similarly, the role of image deblurring in enhancing VPR performance under motion blur has received limited attention so far. This paper bridges these gaps by introducing a new benchmark designed to evaluate VPR performance under the influence of motion blur and image deblurring. The benchmark includes three datasets that encompass a wide range of motion blur intensities, providing a comprehensive platform for analysis. Experimental results with several well-established VPR and image deblurring methods provide new insights into the effects of motion blur and the potential improvements achieved through deblurring. Building on these findings, the paper proposes adaptive deblurring strategies for VPR, designed to effectively manage motion blur in dynamic, real-world scenarios.
Structured Pruning for Efficient Visual Place Recognition
Sep 12, 2024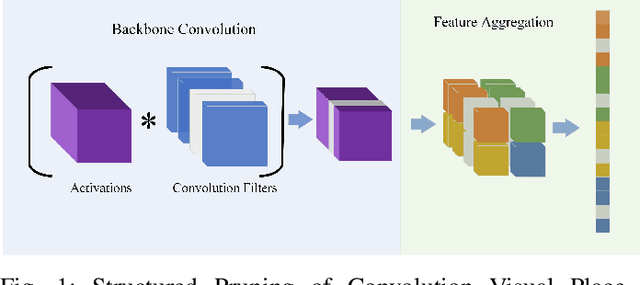
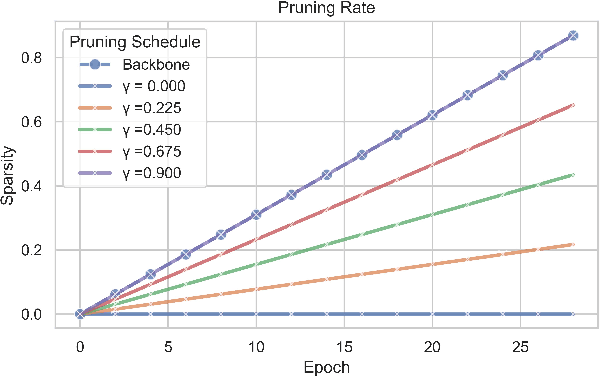
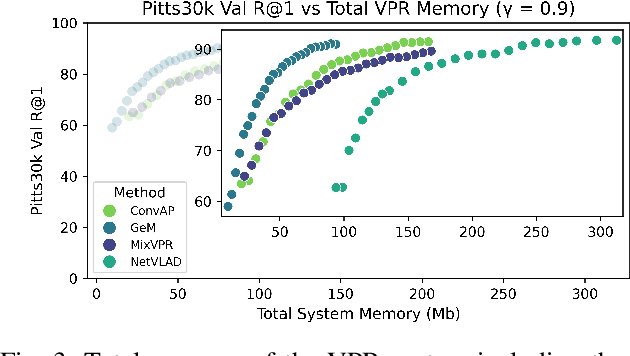
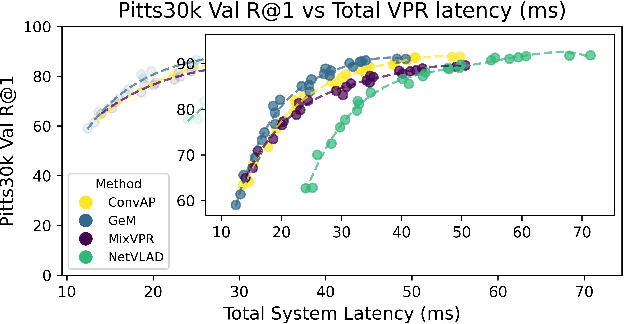
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.
Collective Decision-Making on Task Allocation Feasibility
May 13, 2024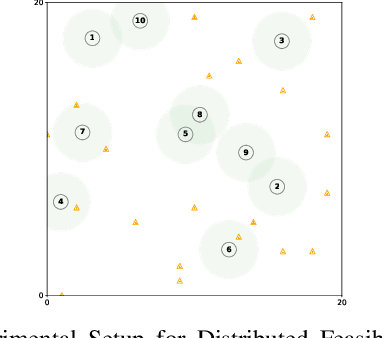
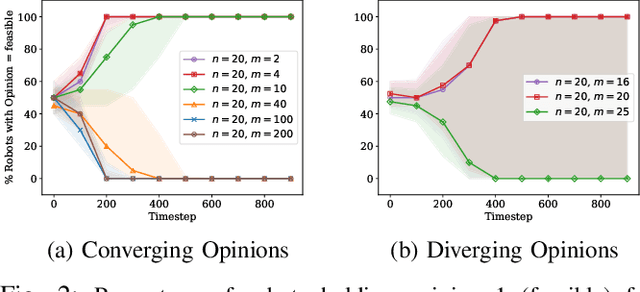
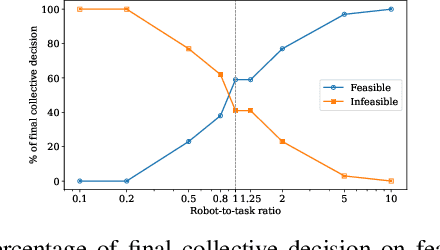
Robot swarms offer the potential to bring several advantages to the real-world applications but deploying them presents challenges in ensuring feasibility across diverse environments. Assessing the feasibility of new tasks for swarms is crucial to ensure the effective utilisation of resources, as well as to provide awareness of the suitability of a swarm solution for a particular task. In this paper, we introduce the concept of distributed feasibility, where the swarm collectively assesses the feasibility of task allocation based on local observations and interactions. We apply Direct Modulation of Majority-based Decisions as our collective decision-making strategy and show that, in a homogeneous setting, the swarm is able to collectively decide whether a given setup has a high or low feasibility as long as the robot-to-task ratio is not near one.
Multi-Technique Sequential Information Consistency For Dynamic Visual Place Recognition In Changing Environments
Jan 16, 2024Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance driven by different daily illumination, seasonal weather variations and diverse viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings, and therefore combining multiple techniques can achieve more reliable VPR performance. Present multi-method approaches either rely on online ground-truth information, which is often not available, or on brute-force technique combination, potentially lowering performance with high variance technique sets. Addressing these shortcomings, we propose a VPR system dubbed Multi-Sequential Information Consistency (MuSIC) which leverages sequential information to select the most cohesive technique on an online per-frame basis. For each technique in a set, MuSIC computes their respective sequential consistencies by analysing the frame-to-frame continuity of their top match candidates, which are then directly compared to select the optimal technique for the current query image. The use of sequential information to select between VPR methods results in an overall VPR performance increase across different benchmark datasets, while avoiding the need for extra ground-truth of the runtime environment.