 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-based Geo-localization for Robotics: Are Black-box Vision-Language Models there yet?
Jan 28, 2025



The advances in Vision-Language models (VLMs) offer exciting opportunities for robotic applications involving image geo-localization, the problem of identifying the geo-coordinates of a place based on visual data only. Recent research works have focused on using a VLM as embeddings extractor for geo-localization, however, the most sophisticated VLMs may only be available as black boxes that are accessible through an API, and come with a number of limitations: there is no access to training data, model features and gradients; retraining is not possible; the number of predictions may be limited by the API; training on model outputs is often prohibited; and queries are open-ended. The utilization of a VLM as a stand-alone, zero-shot geo-localization system using a single text-based prompt is largely unexplored. To bridge this gap, this paper undertakes the first systematic study, to the best of our knowledge, to investigate the potential of some of the state-of-the-art VLMs as stand-alone, zero-shot geo-localization systems in a black-box setting with realistic constraints. We consider three main scenarios for this thorough investigation: a) fixed text-based prompt; b) semantically-equivalent text-based prompts; and c) semantically-equivalent query images. We also take into account the auto-regressive and probabilistic generation process of the VLMs when investigating their utility for geo-localization task by using model consistency as a metric in addition to traditional accuracy. Our work provides new insights in the capabilities of different VLMs for the above-mentioned scenarios.
On Motion Blur and Deblurring in Visual Place Recognition
Dec 10, 2024



Visual Place Recognition (VPR) in mobile robotics enables robots to localize themselves by recognizing previously visited locations using visual data. While the reliability of VPR methods has been extensively studied under conditions such as changes in illumination, season, weather and viewpoint, the impact of motion blur is relatively unexplored despite its relevance not only in rapid motion scenarios but also in low-light conditions where longer exposure times are necessary. Similarly, the role of image deblurring in enhancing VPR performance under motion blur has received limited attention so far. This paper bridges these gaps by introducing a new benchmark designed to evaluate VPR performance under the influence of motion blur and image deblurring. The benchmark includes three datasets that encompass a wide range of motion blur intensities, providing a comprehensive platform for analysis. Experimental results with several well-established VPR and image deblurring methods provide new insights into the effects of motion blur and the potential improvements achieved through deblurring. Building on these findings, the paper proposes adaptive deblurring strategies for VPR, designed to effectively manage motion blur in dynamic, real-world scenarios.
Multi-Technique Sequential Information Consistency For Dynamic Visual Place Recognition In Changing Environments
Jan 16, 2024Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance driven by different daily illumination, seasonal weather variations and diverse viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings, and therefore combining multiple techniques can achieve more reliable VPR performance. Present multi-method approaches either rely on online ground-truth information, which is often not available, or on brute-force technique combination, potentially lowering performance with high variance technique sets. Addressing these shortcomings, we propose a VPR system dubbed Multi-Sequential Information Consistency (MuSIC) which leverages sequential information to select the most cohesive technique on an online per-frame basis. For each technique in a set, MuSIC computes their respective sequential consistencies by analysing the frame-to-frame continuity of their top match candidates, which are then directly compared to select the optimal technique for the current query image. The use of sequential information to select between VPR methods results in an overall VPR performance increase across different benchmark datasets, while avoiding the need for extra ground-truth of the runtime environment.
Aggregating Multiple Bio-Inspired Image Region Classifiers For Effective And Lightweight Visual Place Recognition
Dec 20, 2023



Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While VPR techniques built upon a Convolutional Neural Network (CNN) backbone dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms equipped with low-end hardware. Recently, a lightweight VPR system based on multiple bio-inspired classifiers, dubbed DrosoNets, has been proposed, achieving great computational efficiency at the cost of reduced absolute place retrieval performance. In this work, we propose a novel multi-DrosoNet localization system, dubbed RegionDrosoNet, with significantly improved VPR performance, while preserving a low-computational profile. Our approach relies on specializing distinct groups of DrosoNets on differently sliced partitions of the original image, increasing extrinsic model differentiation. Furthermore, we introduce a novel voting module to combine the outputs of all DrosoNets into the final place prediction which considers multiple top refence candidates from each DrosoNet. RegionDrosoNet outperforms other lightweight VPR techniques when dealing with both appearance changes and viewpoint variations. Moreover, it competes with computationally expensive methods on some benchmark datasets at a small fraction of their online inference time.
Visual Place Recognition with Low-Resolution Images
May 09, 2023



Images incorporate a wealth of information from a robot's surroundings. With the widespread availability of compact cameras, visual information has become increasingly popular for addressing the localisation problem, which is then termed as Visual Place Recognition (VPR). While many applications use high-resolution cameras and high-end systems to achieve optimal place-matching performance, low-end commercial systems face limitations due to resource constraints and relatively low-resolution and low-quality cameras. In this paper, we analyse the effects of image resolution on the accuracy and robustness of well-established handcrafted VPR pipelines. Handcrafted designs have low computational demands and can adapt to flexible image resolutions, making them a suitable approach to scale to any image source and to operate under resource limitations. This paper aims to help academic researchers and companies in the hardware and software industry co-design VPR solutions and expand the use of VPR algorithms in commercial products.
Patch-DrosoNet: Classifying Image Partitions With Fly-Inspired Models For Lightweight Visual Place Recognition
May 09, 2023



Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While Convolution Neural Networks (CNNs) currently dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms with budget or size constraints. This has spurred the development of lightweight algorithms, such as DrosoNet, which employs a voting system based on multiple bio-inspired units. In this paper, we present a novel training approach for DrosoNet, wherein separate models are trained on distinct regions of a reference image, allowing them to specialize in the visual features of that specific section. Additionally, we introduce a convolutional-like prediction method, in which each DrosoNet unit generates a set of place predictions for each portion of the query image. These predictions are then combined using the previously introduced voting system. Our approach significantly improves upon the VPR performance of previous work while maintaining an extremely compact and lightweight algorithm, making it suitable for resource-constrained platforms.
A-MuSIC: An Adaptive Ensemble System For Visual Place Recognition In Changing Environments
Mar 24, 2023



Visual place recognition (VPR) is an essential component of robot navigation and localization systems that allows them to identify a place using only image data. VPR is challenging due to the significant changes in a place's appearance under different illumination throughout the day, with seasonal weather and when observed from different viewpoints. Currently, no single VPR technique excels in every environmental condition, each exhibiting unique benefits and shortcomings. As a result, VPR systems combining multiple techniques achieve more reliable VPR performance in changing environments, at the cost of higher computational loads. Addressing this shortcoming, we propose an adaptive VPR system dubbed Adaptive Multi-Self Identification and Correction (A-MuSIC). We start by developing a method to collect information of the runtime performance of a VPR technique by analysing the frame-to-frame continuity of matched queries. We then demonstrate how to operate the method on a static ensemble of techniques, generating data on which techniques are contributing the most for the current environment. A-MuSIC uses the collected information to both select a minimal subset of techniques and to decide when a re-selection is required during navigation. A-MuSIC matches or beats state-of-the-art VPR performance across all tested benchmark datasets while maintaining its computational load on par with individual techniques.
Data-Efficient Sequence-Based Visual Place Recognition with Highly Compressed JPEG Images
Feb 26, 2023



Visual Place Recognition (VPR) is a fundamental task that allows a robotic platform to successfully localise itself in the environment. For decentralised VPR applications where the visual data has to be transmitted between several agents, the communication channel may restrict the localisation process when limited bandwidth is available. JPEG is an image compression standard that can employ high compression ratios to facilitate lower data transmission for VPR applications. However, when applying high levels of JPEG compression, both the image clarity and size are drastically reduced. In this paper, we incorporate sequence-based filtering in a number of well-established, learnt and non-learnt VPR techniques to overcome the performance loss resulted from introducing high levels of JPEG compression. The sequence length that enables 100% place matching performance is reported and an analysis of the amount of data required for each VPR technique to perform the transfer on the entire spectrum of JPEG compression is provided. Moreover, the time required by each VPR technique to perform place matching is investigated, on both uniformly and non-uniformly JPEG compressed data. The results show that it is beneficial to use a highly compressed JPEG dataset with an increased sequence length, as similar levels of VPR performance are reported at a significantly reduced bandwidth. The results presented in this paper also emphasize that there is a trade-off between the amount of data transferred and the total time required to perform VPR. Our experiments also suggest that is often favourable to compress the query images to the same quality of the map, as more efficient place matching can be performed. The experiments are conducted on several VPR datasets, under mild to extreme JPEG compression.
Merging Classification Predictions with Sequential Information for Lightweight Visual Place Recognition in Changing Environments
Oct 03, 2022
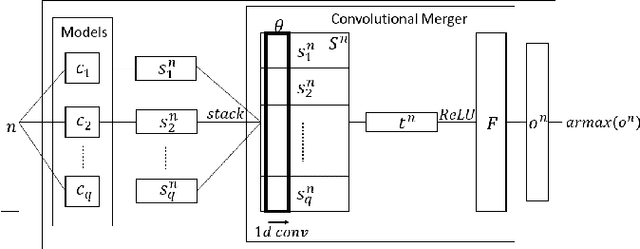
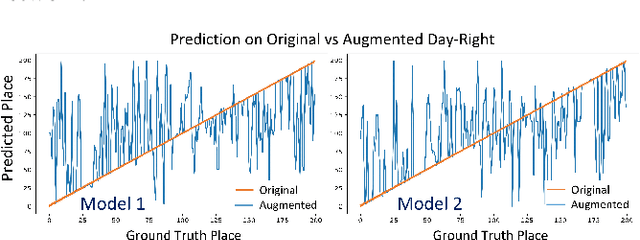

Low-overhead visual place recognition (VPR) is a highly active research topic. Mobile robotics applications often operate under low-end hardware, and even more hardware capable systems can still benefit from freeing up onboard system resources for other navigation tasks. This work addresses lightweight VPR by proposing a novel system based on the combination of binary-weighted classifier networks with a one-dimensional convolutional network, dubbed merger. Recent work in fusing multiple VPR techniques has mainly focused on increasing VPR performance, with computational efficiency not being highly prioritized. In contrast, we design our technique prioritizing low inference times, taking inspiration from the machine learning literature where the efficient combination of classifiers is a heavily researched topic. Our experiments show that the merger achieves inference times as low as 1 millisecond, being significantly faster than other well-established lightweight VPR techniques, while achieving comparable or superior VPR performance on several visual changes such as seasonal variations and viewpoint lateral shifts.
Data Efficient Visual Place Recognition Using Extremely JPEG-Compressed Images
Sep 17, 2022
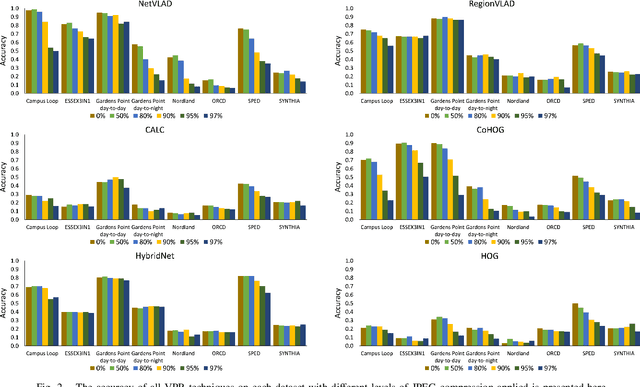
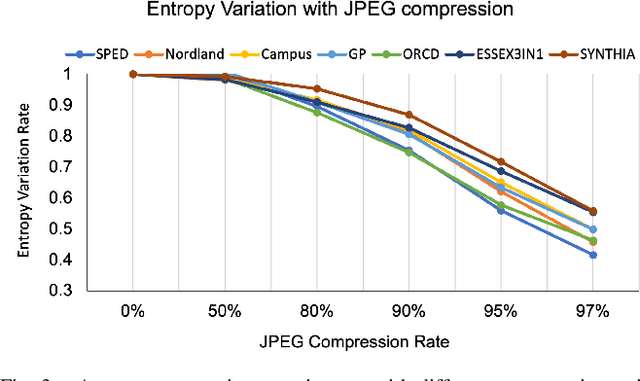

Visual Place Recognition (VPR) is the ability of a robotic platform to correctly interpret visual stimuli from its on-board cameras in order to determine whether it is currently located in a previously visited place, despite different viewpoint, illumination and appearance changes. JPEG is a widely used image compression standard that is capable of significantly reducing the size of an image at the cost of image clarity. For applications where several robotic platforms are simultaneously deployed, the visual data gathered must be transmitted remotely between each robot. Hence, JPEG compression can be employed to drastically reduce the amount of data transmitted over a communication channel, as working with limited bandwidth for VPR can be proven to be a challenging task. However, the effects of JPEG compression on the performance of current VPR techniques have not been previously studied. For this reason, this paper presents an in-depth study of JPEG compression in VPR related scenarios. We use a selection of well-established VPR techniques on 8 datasets with various amounts of compression applied. We show that by introducing compression, the VPR performance is drastically reduced, especially in the higher spectrum of compression. To overcome the negative effects of JPEG compression on the VPR performance, we present a fine-tuned CNN which is optimized for JPEG compressed data and show that it performs more consistently with the image transformations detected in extremely compressed JPEG images.