 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Pruning for Efficient Visual Place Recognition
Paper and Code
Sep 12, 2024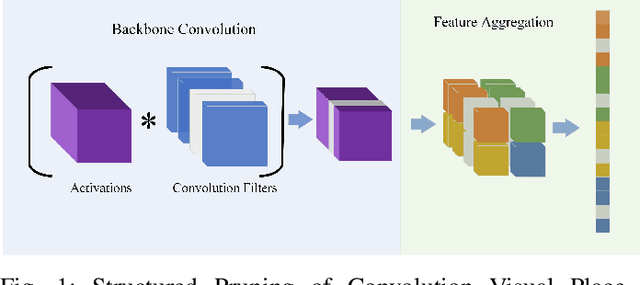
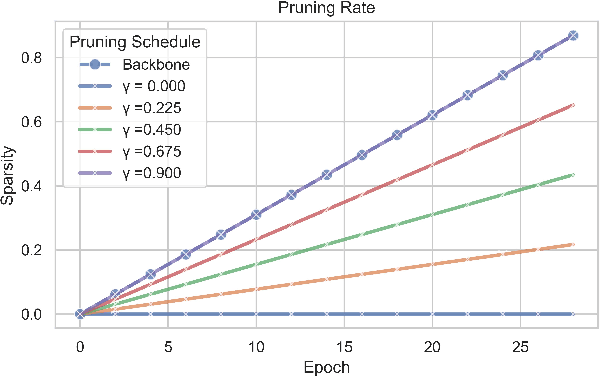
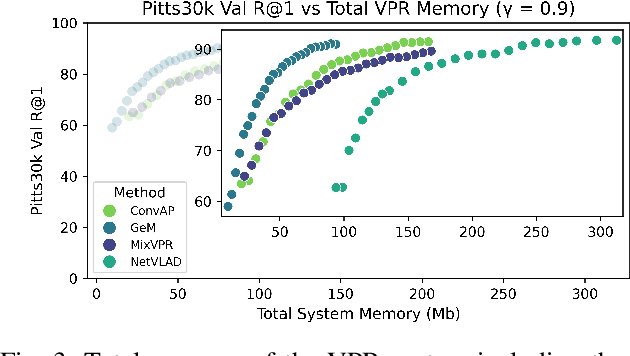
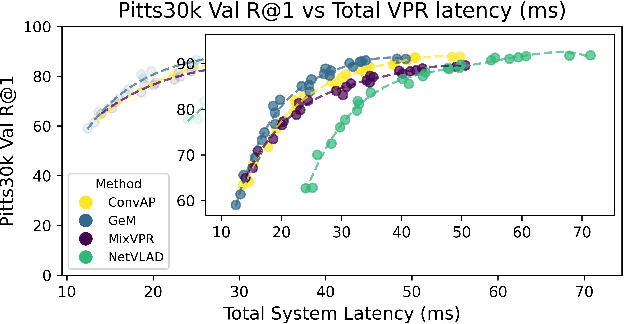
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.