 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian and Diffusion-Based Gaze Redirection
Nov 14, 2025



High-fidelity gaze redirection is critical for generating augmented data to improve the generalization of gaze estimators. 3D Gaussian Splatting (3DGS) models like GazeGaussian represent the state-of-the-art but can struggle with rendering subtle, continuous gaze shifts. In this paper, we propose DiT-Gaze, a framework that enhances 3D gaze redirection models using a novel combination of Diffusion Transformer (DiT), weak supervision across gaze angles, and an orthogonality constraint loss. DiT allows higher-fidelity image synthesis, while our weak supervision strategy using synthetically generated intermediate gaze angles provides a smooth manifold of gaze directions during training. The orthogonality constraint loss mathematically enforces the disentanglement of internal representations for gaze, head pose, and expression. Comprehensive experiments show that DiT-Gaze sets a new state-of-the-art in both perceptual quality and redirection accuracy, reducing the state-of-the-art gaze error by 4.1% to 6.353 degrees, providing a superior method for creating synthetic training data. Our code and models will be made available for the research community to benchmark against.
TAT-VPR: Ternary Adaptive Transformer for Dynamic and Efficient Visual Place Recognition
May 22, 2025TAT-VPR is a ternary-quantized transformer that brings dynamic accuracy-efficiency trade-offs to visual SLAM loop-closure. By fusing ternary weights with a learned activation-sparsity gate, the model can control computation by up to 40% at run-time without degrading performance (Recall@1). The proposed two-stage distillation pipeline preserves descriptor quality, letting it run on micro-UAV and embedded SLAM stacks while matching state-of-the-art localization accuracy.
TeTRA-VPR: A Ternary Transformer Approach for Compact Visual Place Recognition
Mar 04, 2025



Visual Place Recognition (VPR) localizes a query image by matching it against a database of geo-tagged reference images, making it essential for navigation and mapping in robotics. Although Vision Transformer (ViT) solutions deliver high accuracy, their large models often exceed the memory and compute budgets of resource-constrained platforms such as drones and mobile robots. To address this issue, we propose TeTRA, a ternary transformer approach that progressively quantizes the ViT backbone to 2-bit precision and binarizes its final embedding layer, offering substantial reductions in model size and latency. A carefully designed progressive distillation strategy preserves the representational power of a full-precision teacher, allowing TeTRA to retain or even surpass the accuracy of uncompressed convolutional counterparts, despite using fewer resources. Experiments on standard VPR benchmarks demonstrate that TeTRA reduces memory consumption by up to 69% compared to efficient baselines, while lowering inference latency by 35%, with either no loss or a slight improvement in recall@1. These gains enable high-accuracy VPR on power-constrained, memory-limited robotic platforms, making TeTRA an appealing solution for real-world deployment.
Structured Pruning for Efficient Visual Place Recognition
Sep 12, 2024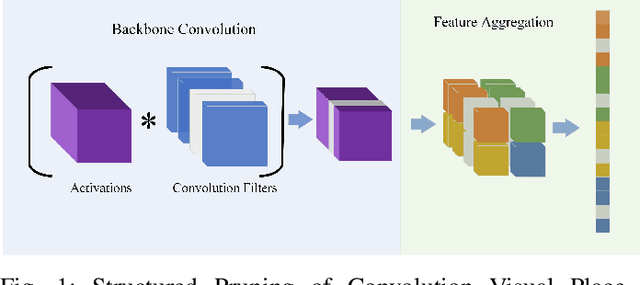
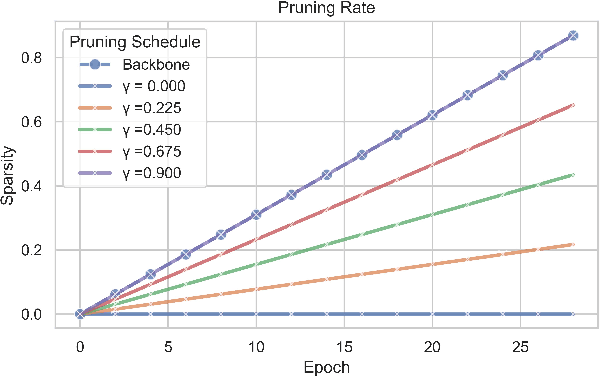
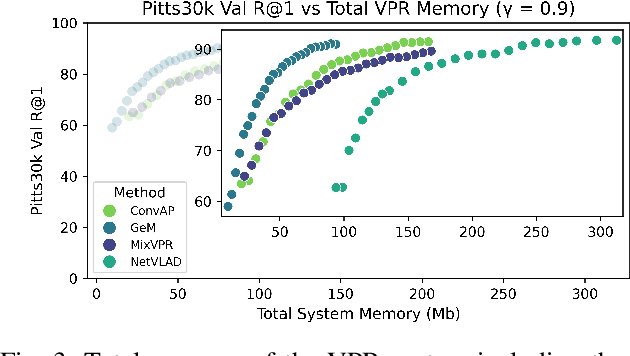
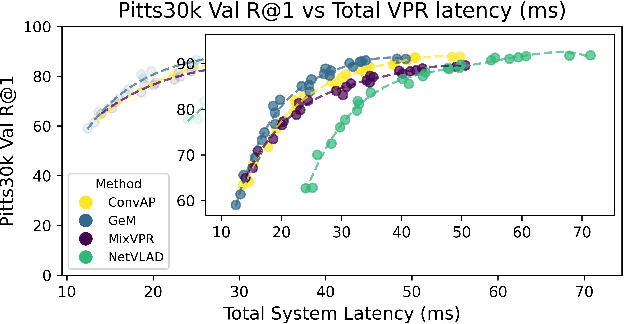
Visual Place Recognition (VPR) is fundamental for the global re-localization of robots and devices, enabling them to recognize previously visited locations based on visual inputs. This capability is crucial for maintaining accurate mapping and localization over large areas. Given that VPR methods need to operate in real-time on embedded systems, it is critical to optimize these systems for minimal resource consumption. While the most efficient VPR approaches employ standard convolutional backbones with fixed descriptor dimensions, these often lead to redundancy in the embedding space as well as in the network architecture. Our work introduces a novel structured pruning method, to not only streamline common VPR architectures but also to strategically remove redundancies within the feature embedding space. This dual focus significantly enhances the efficiency of the system, reducing both map and model memory requirements and decreasing feature extraction and retrieval latencies. Our approach has reduced memory usage and latency by 21% and 16%, respectively, across models, while minimally impacting recall@1 accuracy by less than 1%. This significant improvement enhances real-time applications on edge devices with negligible accuracy loss.
Design Space Exploration of Low-Bit Quantized Neural Networks for Visual Place Recognition
Dec 14, 2023Visual Place Recognition (VPR) is a critical task for performing global re-localization in visual perception systems. It requires the ability to accurately recognize a previously visited location under variations such as illumination, occlusion, appearance and viewpoint. In the case of robotic systems and augmented reality, the target devices for deployment are battery powered edge devices. Therefore whilst the accuracy of VPR methods is important so too is memory consumption and latency. Recently new works have focused on the recall@1 metric as a performance measure with limited focus on resource utilization. This has resulted in methods that use deep learning models too large to deploy on low powered edge devices. We hypothesize that these large models are highly over-parameterized and can be optimized to satisfy the constraints of a low powered embedded system whilst maintaining high recall performance. Our work studies the impact of compact convolutional network architecture design in combination with full-precision and mixed-precision post-training quantization on VPR performance. Importantly we not only measure performance via the recall@1 score but also measure memory consumption and latency. We characterize the design implications on memory, latency and recall scores and provide a number of design recommendations for VPR systems under these resource limitations.