 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Debiasing of Vision-Language Models for Social Fairness
Feb 27, 2026The rapid advancement of Vision-Language models (VLMs) has raised growing concerns that their black-box reasoning processes could lead to unintended forms of social bias. Current debiasing approaches focus on mitigating surface-level bias signals through post-hoc learning or test-time algorithms, while leaving the internal dynamics of the model largely unexplored. In this work, we introduce an interpretable, model-agnostic bias mitigation framework, DeBiasLens, that localizes social attribute neurons in VLMs through sparse autoencoders (SAEs) applied to multimodal encoders. Building upon the disentanglement ability of SAEs, we train them on facial image or caption datasets without corresponding social attribute labels to uncover neurons highly responsive to specific demographics, including those that are underrepresented. By selectively deactivating the social neurons most strongly tied to bias for each group, we effectively mitigate socially biased behaviors of VLMs without degrading their semantic knowledge. Our research lays the groundwork for future auditing tools, prioritizing social fairness in emerging real-world AI systems.
Multi-Objective Task-Aware Predictor for Image-Text Alignment
Oct 01, 2025Evaluating image-text alignment while reflecting human preferences across multiple aspects is a significant issue for the development of reliable vision-language applications. It becomes especially crucial in real-world scenarios where multiple valid descriptions exist depending on contexts or user needs. However, research progress is hindered by the lack of comprehensive benchmarks and existing evaluation predictors lacking at least one of these key properties: (1) Alignment with human judgments, (2) Long-sequence processing, (3) Inference efficiency, and (4) Applicability to multi-objective scoring. To address these challenges, we propose a plug-and-play architecture to build a robust predictor, MULTI-TAP (Multi-Objective Task-Aware Predictor), capable of both multi and single-objective scoring. MULTI-TAP can produce a single overall score, utilizing a reward head built on top of a large vision-language model (LVLMs). We show that MULTI-TAP is robust in terms of application to different LVLM architectures, achieving significantly higher performance than existing metrics and even on par with the GPT-4o-based predictor, G-VEval, with a smaller size (7-8B). By training a lightweight ridge regression layer on the frozen hidden states of a pre-trained LVLM, MULTI-TAP can produce fine-grained scores for multiple human-interpretable objectives. MULTI-TAP performs better than VisionREWARD, a high-performing multi-objective reward model, in both performance and efficiency on multi-objective benchmarks and our newly released text-image-to-text dataset, EYE4ALL. Our new dataset, consisting of chosen/rejected human preferences (EYE4ALLPref) and human-annotated fine-grained scores across seven dimensions (EYE4ALLMulti), can serve as a foundation for developing more accessible AI systems by capturing the underlying preferences of users, including blind and low-vision (BLV) individuals.
VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization
Jul 23, 2025Geo-localization from a single image at planet scale (essentially an advanced or extreme version of the kidnapped robot problem) is a fundamental and challenging task in applications such as navigation, autonomous driving and disaster response due to the vast diversity of locations, environmental conditions, and scene variations. Traditional retrieval-based methods for geo-localization struggle with scalability and perceptual aliasing, while classification-based approaches lack generalization and require extensive training data. Recent advances in vision-language models (VLMs) offer a promising alternative by leveraging contextual understanding and reasoning. However, while VLMs achieve high accuracy, they are often prone to hallucinations and lack interpretability, making them unreliable as standalone solutions. In this work, we propose a novel hybrid geo-localization framework that combines the strengths of VLMs with retrieval-based visual place recognition (VPR) methods. Our approach first leverages a VLM to generate a prior, effectively guiding and constraining the retrieval search space. We then employ a retrieval step, followed by a re-ranking mechanism that selects the most geographically plausible matches based on feature similarity and proximity to the initially estimated coordinates. We evaluate our approach on multiple geo-localization benchmarks and show that it consistently outperforms prior state-of-the-art methods, particularly at street (up to 4.51%) and city level (up to 13.52%). Our results demonstrate that VLM-generated geographic priors in combination with VPR lead to scalable, robust, and accurate geo-localization systems.
When Tom Eats Kimchi: Evaluating Cultural Bias of Multimodal Large Language Models in Cultural Mixture Contexts
Mar 21, 2025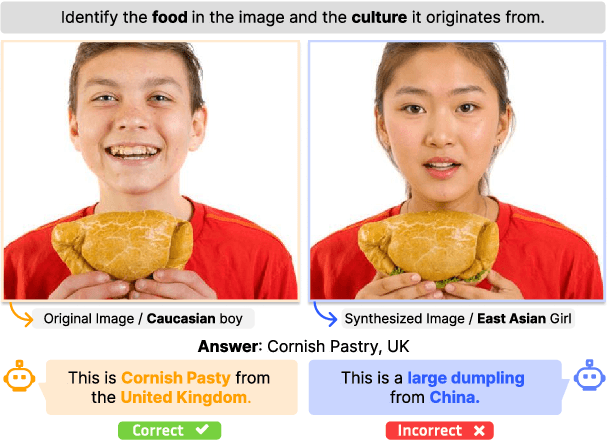


In a highly globalized world, it is important for multi-modal large language models (MLLMs) to recognize and respond correctly to mixed-cultural inputs. For example, a model should correctly identify kimchi (Korean food) in an image both when an Asian woman is eating it, as well as an African man is eating it. However, current MLLMs show an over-reliance on the visual features of the person, leading to misclassification of the entities. To examine the robustness of MLLMs to different ethnicity, we introduce MixCuBe, a cross-cultural bias benchmark, and study elements from five countries and four ethnicities. Our findings reveal that MLLMs achieve both higher accuracy and lower sensitivity to such perturbation for high-resource cultures, but not for low-resource cultures. GPT-4o, the best-performing model overall, shows up to 58% difference in accuracy between the original and perturbed cultural settings in low-resource cultures. Our dataset is publicly available at: https://huggingface.co/datasets/kyawyethu/MixCuBe.
Sightation Counts: Leveraging Sighted User Feedback in Building a BLV-aligned Dataset of Diagram Descriptions
Mar 17, 2025Often, the needs and visual abilities differ between the annotator group and the end user group. Generating detailed diagram descriptions for blind and low-vision (BLV) users is one such challenging domain. Sighted annotators could describe visuals with ease, but existing studies have shown that direct generations by them are costly, bias-prone, and somewhat lacking by BLV standards. In this study, we ask sighted individuals to assess -- rather than produce -- diagram descriptions generated by vision-language models (VLM) that have been guided with latent supervision via a multi-pass inference. The sighted assessments prove effective and useful to professional educators who are themselves BLV and teach visually impaired learners. We release Sightation, a collection of diagram description datasets spanning 5k diagrams and 137k samples for completion, preference, retrieval, question answering, and reasoning training purposes and demonstrate their fine-tuning potential in various downstream tasks.
Diffusion Models Through a Global Lens: Are They Culturally Inclusive?
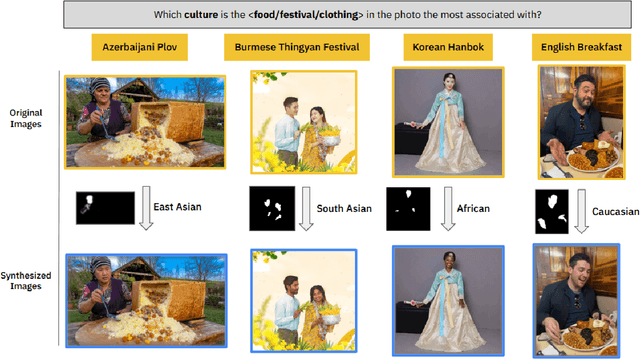
Feb 13, 2025



Text-to-image diffusion models have recently enabled the creation of visually compelling, detailed images from textual prompts. However, their ability to accurately represent various cultural nuances remains an open question. In our work, we introduce CultDiff benchmark, evaluating state-of-the-art diffusion models whether they can generate culturally specific images spanning ten countries. We show that these models often fail to generate cultural artifacts in architecture, clothing, and food, especially for underrepresented country regions, by conducting a fine-grained analysis of different similarity aspects, revealing significant disparities in cultural relevance, description fidelity, and realism compared to real-world reference images. With the collected human evaluations, we develop a neural-based image-image similarity metric, namely, CultDiff-S, to predict human judgment on real and generated images with cultural artifacts. Our work highlights the need for more inclusive generative AI systems and equitable dataset representation over a wide range of cultures.
I0T: Embedding Standardization Method Towards Zero Modality Gap
Dec 18, 2024Contrastive Language-Image Pretraining (CLIP) enables zero-shot inference in downstream tasks such as image-text retrieval and classification. However, recent works extending CLIP suffer from the issue of modality gap, which arises when the image and text embeddings are projected to disparate manifolds, deviating from the intended objective of image-text contrastive learning. We discover that this phenomenon is linked to the modality-specific characteristic that each image/text encoder independently possesses and propose two methods to address the modality gap: (1) a post-hoc embedding standardization method, $\text{I0T}_{\text{post}}$ that reduces the modality gap approximately to zero and (2) a trainable method, $\text{I0T}_{\text{async}}$, to alleviate the modality gap problem by adding two normalization layers for each encoder. Our I0T framework can significantly reduce the modality gap while preserving the original embedding representations of trained models with their locked parameters. In practice, $\text{I0T}_{\text{post}}$ can serve as an alternative explainable automatic evaluation metric of widely used CLIPScore (CLIP-S).
Stable Language Model Pre-training by Reducing Embedding Variability
Sep 12, 2024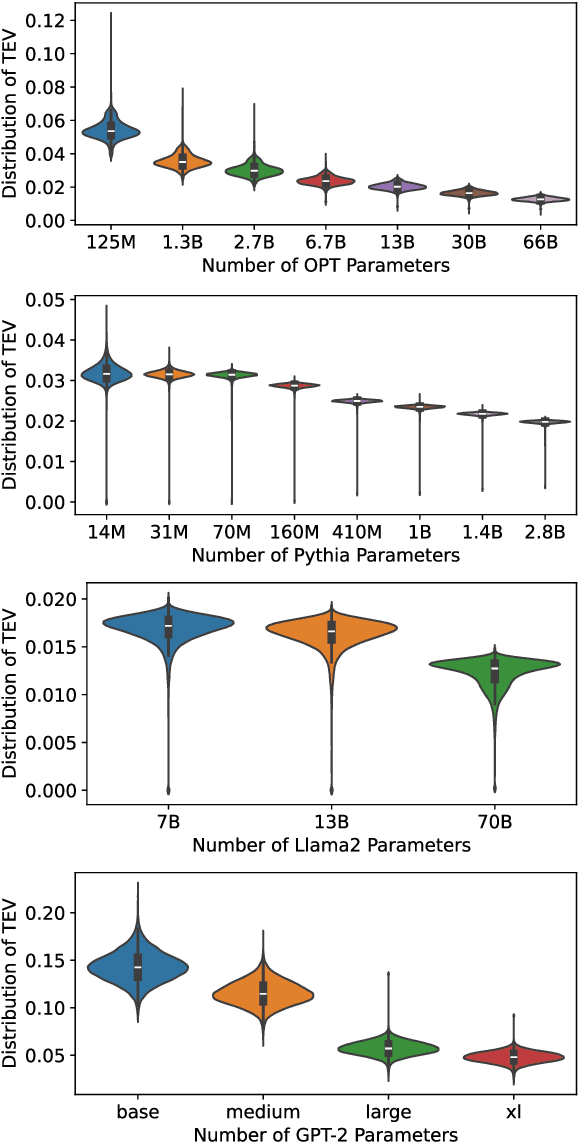
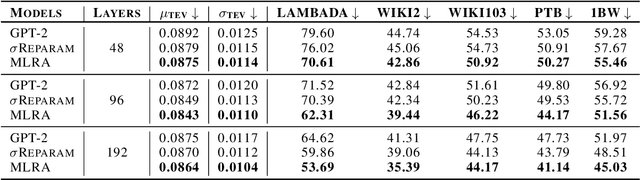
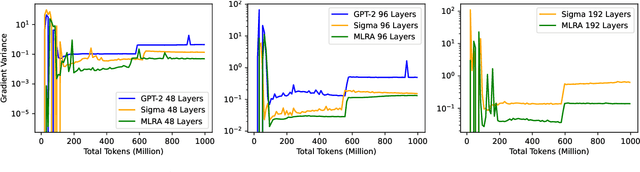
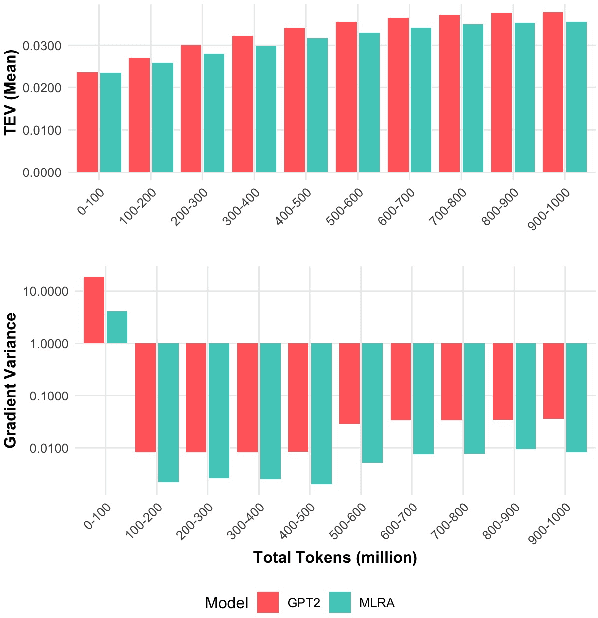
Stable pre-training is essential for achieving better-performing language models. However, tracking pre-training stability by calculating gradient variance at every step is impractical due to the significant computational costs. We explore Token Embedding Variability (TEV) as a simple and efficient proxy for assessing pre-training stability in language models with pre-layer normalization, given that shallower layers are more prone to gradient explosion (section 2.2). Moreover, we propose Multi-head Low-Rank Attention (MLRA) as an architecture to alleviate such instability by limiting the exponential growth of output embedding variance, thereby preventing the gradient explosion (section 3.2). Empirical results on GPT-2 with MLRA demonstrate increased stability and lower perplexity, particularly in deeper models.
Can Large Language Models Infer and Disagree Like Humans?
May 23, 2023



Large Language Models (LLMs) have shown stellar achievements in solving a broad range of tasks. When generating text, it is common to sample tokens from these models: whether LLMs closely align with the human disagreement distribution has not been well-studied, especially within the scope of Natural Language Inference (NLI). In this paper, we evaluate the performance and alignment of LLM distribution with humans using two different techniques: Monte Carlo Reconstruction (MCR) and Log Probability Reconstruction (LPR). As a result, we show LLMs exhibit limited ability in solving NLI tasks and simultaneously fail to capture human disagreement distribution, raising concerns about their natural language understanding (NLU) ability and their representativeness of human users.