 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSightation Counts: Leveraging Sighted User Feedback in Building a BLV-aligned Dataset of Diagram Descriptions
Mar 17, 2025Often, the needs and visual abilities differ between the annotator group and the end user group. Generating detailed diagram descriptions for blind and low-vision (BLV) users is one such challenging domain. Sighted annotators could describe visuals with ease, but existing studies have shown that direct generations by them are costly, bias-prone, and somewhat lacking by BLV standards. In this study, we ask sighted individuals to assess -- rather than produce -- diagram descriptions generated by vision-language models (VLM) that have been guided with latent supervision via a multi-pass inference. The sighted assessments prove effective and useful to professional educators who are themselves BLV and teach visually impaired learners. We release Sightation, a collection of diagram description datasets spanning 5k diagrams and 137k samples for completion, preference, retrieval, question answering, and reasoning training purposes and demonstrate their fine-tuning potential in various downstream tasks.
Curiosity-Driven Multi-Agent Exploration with Mixed Objectives
Oct 29, 2022



Intrinsic rewards have been increasingly used to mitigate the sparse reward problem in single-agent reinforcement learning. These intrinsic rewards encourage the agent to look for novel experiences, guiding the agent to explore the environment sufficiently despite the lack of extrinsic rewards. Curiosity-driven exploration is a simple yet efficient approach that quantifies this novelty as the prediction error of the agent's curiosity module, an internal neural network that is trained to predict the agent's next state given its current state and action. We show here, however, that naively using this curiosity-driven approach to guide exploration in sparse reward cooperative multi-agent environments does not consistently lead to improved results. Straightforward multi-agent extensions of curiosity-driven exploration take into consideration either individual or collective novelty only and thus, they do not provide a distinct but collaborative intrinsic reward signal that is essential for learning in cooperative multi-agent tasks. In this work, we propose a curiosity-driven multi-agent exploration method that has the mixed objective of motivating the agents to explore the environment in ways that are individually and collectively novel. First, we develop a two-headed curiosity module that is trained to predict the corresponding agent's next observation in the first head and the next joint observation in the second head. Second, we design the intrinsic reward formula to be the sum of the individual and joint prediction errors of this curiosity module. We empirically show that the combination of our curiosity module architecture and intrinsic reward formulation guides multi-agent exploration more efficiently than baseline approaches, thereby providing the best performance boost to MARL algorithms in cooperative navigation environments with sparse rewards.
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning
May 14, 2019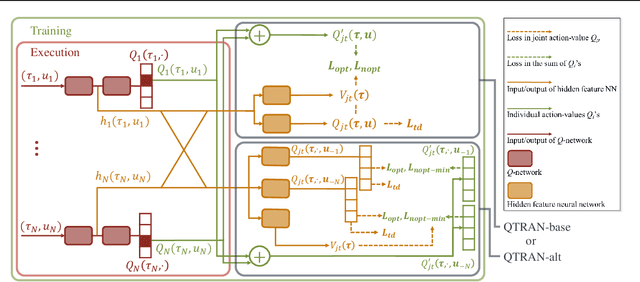
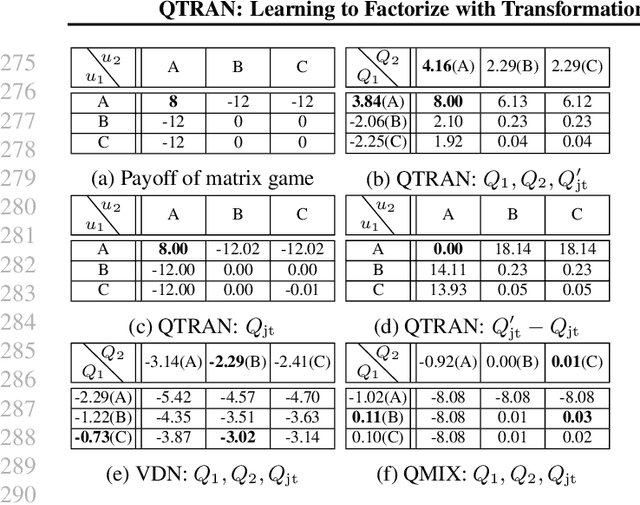
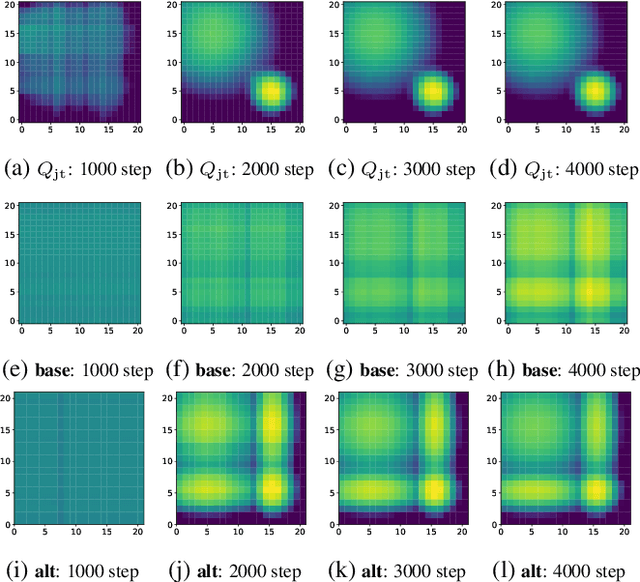
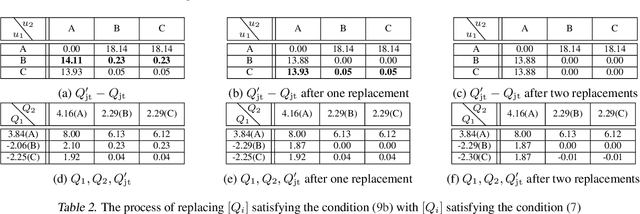
We explore value-based solutions for multi-agent reinforcement learning (MARL) tasks in the centralized training with decentralized execution (CTDE) regime popularized recently. However, VDN and QMIX are representative examples that use the idea of factorization of the joint action-value function into individual ones for decentralized execution. VDN and QMIX address only a fraction of factorizable MARL tasks due to their structural constraint in factorization such as additivity and monotonicity. In this paper, we propose a new factorization method for MARL, QTRAN, which is free from such structural constraints and takes on a new approach to transforming the original joint action-value function into an easily factorizable one, with the same optimal actions. QTRAN guarantees more general factorization than VDN or QMIX, thus covering a much wider class of MARL tasks than does previous methods. Our experiments for the tasks of multi-domain Gaussian-squeeze and modified predator-prey demonstrate QTRAN's superior performance with especially larger margins in games whose payoffs penalize non-cooperative behavior more aggressively.
Learning to Schedule Communication in Multi-agent Reinforcement Learning
Feb 05, 2019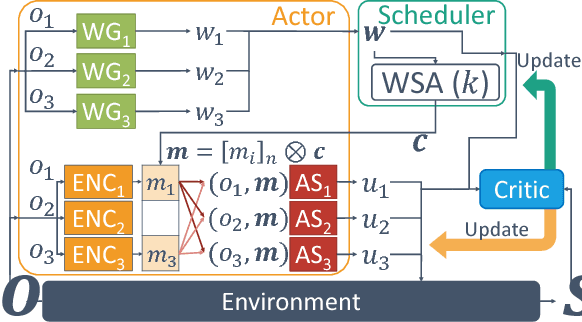

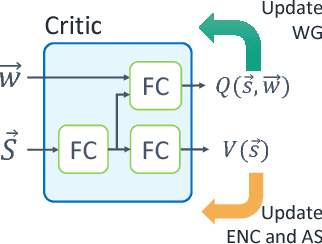

Many real-world reinforcement learning tasks require multiple agents to make sequential decisions under the agents' interaction, where well-coordinated actions among the agents are crucial to achieve the target goal better at these tasks. One way to accelerate the coordination effect is to enable multiple agents to communicate with each other in a distributed manner and behave as a group. In this paper, we study a practical scenario when (i) the communication bandwidth is limited and (ii) the agents share the communication medium so that only a restricted number of agents are able to simultaneously use the medium, as in the state-of-the-art wireless networking standards. This calls for a certain form of communication scheduling. In that regard, we propose a multi-agent deep reinforcement learning framework, called SchedNet, in which agents learn how to schedule themselves, how to encode the messages, and how to select actions based on received messages. SchedNet is capable of deciding which agents should be entitled to broadcasting their (encoded) messages, by learning the importance of each agent's partially observed information. We evaluate SchedNet against multiple baselines under two different applications, namely, cooperative communication and navigation, and predator-prey. Our experiments show a non-negligible performance gap between SchedNet and other mechanisms such as the ones without communication and with vanilla scheduling methods, e.g., round robin, ranging from 32% to 43%.