 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Evidence to Belief: A Bayesian Epistemology Approach to Language Models
Apr 28, 2025This paper investigates the knowledge of language models from the perspective of Bayesian epistemology. We explore how language models adjust their confidence and responses when presented with evidence with varying levels of informativeness and reliability. To study these properties, we create a dataset with various types of evidence and analyze language models' responses and confidence using verbalized confidence, token probability, and sampling. We observed that language models do not consistently follow Bayesian epistemology: language models follow the Bayesian confirmation assumption well with true evidence but fail to adhere to other Bayesian assumptions when encountering different evidence types. Also, we demonstrated that language models can exhibit high confidence when given strong evidence, but this does not always guarantee high accuracy. Our analysis also reveals that language models are biased toward golden evidence and show varying performance depending on the degree of irrelevance, helping explain why they deviate from Bayesian assumptions.
Sightation Counts: Leveraging Sighted User Feedback in Building a BLV-aligned Dataset of Diagram Descriptions
Mar 17, 2025Often, the needs and visual abilities differ between the annotator group and the end user group. Generating detailed diagram descriptions for blind and low-vision (BLV) users is one such challenging domain. Sighted annotators could describe visuals with ease, but existing studies have shown that direct generations by them are costly, bias-prone, and somewhat lacking by BLV standards. In this study, we ask sighted individuals to assess -- rather than produce -- diagram descriptions generated by vision-language models (VLM) that have been guided with latent supervision via a multi-pass inference. The sighted assessments prove effective and useful to professional educators who are themselves BLV and teach visually impaired learners. We release Sightation, a collection of diagram description datasets spanning 5k diagrams and 137k samples for completion, preference, retrieval, question answering, and reasoning training purposes and demonstrate their fine-tuning potential in various downstream tasks.
Context Filtering with Reward Modeling in Question Answering
Dec 16, 2024Question Answering (QA) in NLP is the task of finding answers to a query within a relevant context retrieved by a retrieval system. Yet, the mix of relevant and irrelevant information in these contexts can hinder performance enhancements in QA tasks. To address this, we introduce a context filtering approach that removes non-essential details, summarizing crucial content through Reward Modeling. This method emphasizes keeping vital data while omitting the extraneous during summarization model training. We offer a framework for developing efficient QA models by discerning useful information from dataset pairs, bypassing the need for costly human evaluation. Furthermore, we show that our approach can significantly outperform the baseline, as evidenced by a 6.8-fold increase in the EM Per Token (EPT) metric, which we propose as a measure of token efficiency, indicating a notable token-efficiency boost for low-resource settings.
ProbGate at EHRSQL 2024: Enhancing SQL Query Generation Accuracy through Probabilistic Threshold Filtering and Error Handling
Apr 25, 2024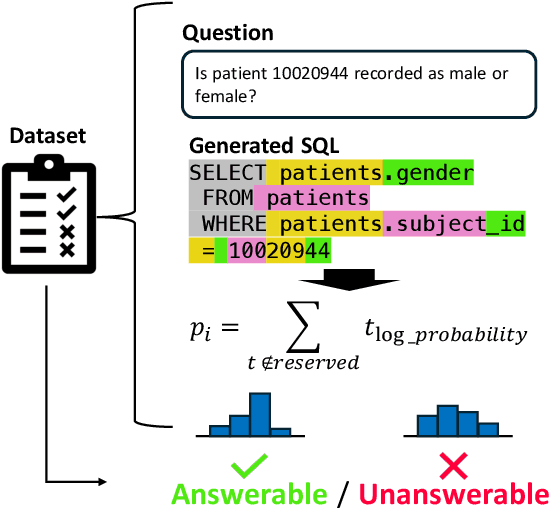
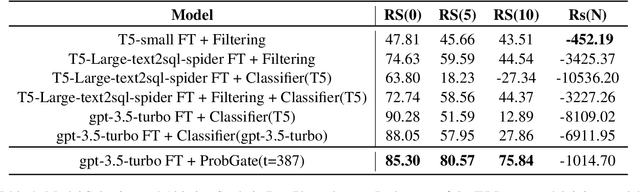
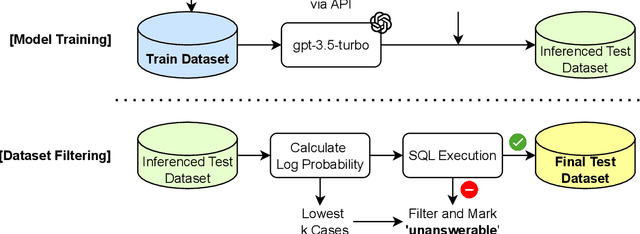
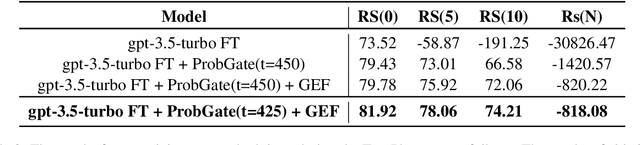
Recently, deep learning-based language models have significantly enhanced text-to-SQL tasks, with promising applications in retrieving patient records within the medical domain. One notable challenge in such applications is discerning unanswerable queries. Through fine-tuning model, we demonstrate the feasibility of converting medical record inquiries into SQL queries. Additionally, we introduce an entropy-based method to identify and filter out unanswerable results. We further enhance result quality by filtering low-confidence SQL through log probability-based distribution, while grammatical and schema errors are mitigated by executing queries on the actual database. We experimentally verified that our method can filter unanswerable questions, which can be widely utilized even when the parameters of the model are not accessible, and that it can be effectively utilized in practice.
Re3val: Reinforced and Reranked Generative Retrieval
Feb 06, 2024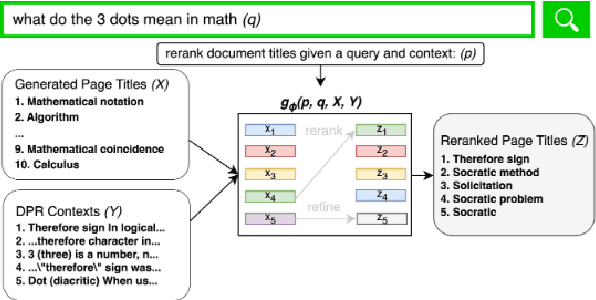
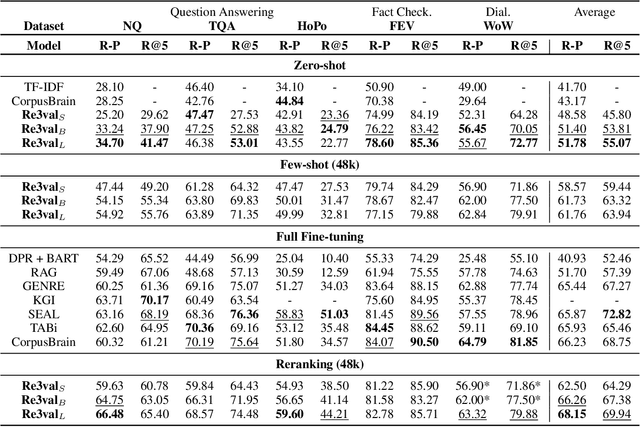
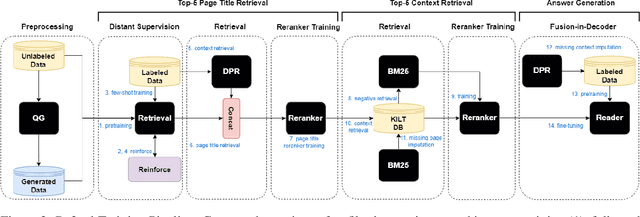
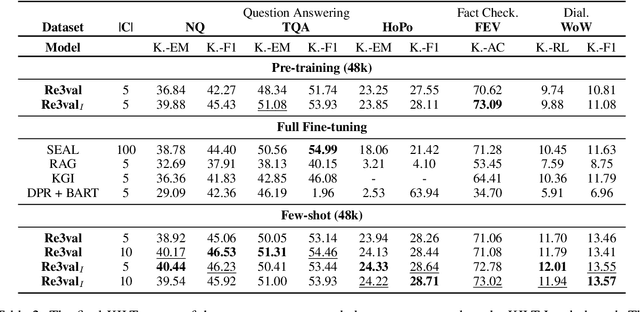
Generative retrieval models encode pointers to information in a corpus as an index within the model's parameters. These models serve as part of a larger pipeline, where retrieved information conditions generation for knowledge-intensive NLP tasks. However, we identify two limitations: the generative retrieval does not account for contextual information. Secondly, the retrieval can't be tuned for the downstream readers as decoding the page title is a non-differentiable operation. This paper introduces Re3val, trained with generative reranking and reinforcement learning using limited data. Re3val leverages context acquired via Dense Passage Retrieval to rerank the retrieved page titles and utilizes REINFORCE to maximize rewards generated by constrained decoding. Additionally, we generate questions from our pre-training dataset to mitigate epistemic uncertainty and bridge the domain gap between the pre-training and fine-tuning datasets. Subsequently, we extract and rerank contexts from the KILT database using the rerank page titles. Upon grounding the top five reranked contexts, Re3val demonstrates the Top 1 KILT scores compared to all other generative retrieval models across five KILT datasets.
eXplainable Bayesian Multi-Perspective Generative Retrieval
Feb 04, 2024Modern deterministic retrieval pipelines prioritize achieving state-of-the-art performance but often lack interpretability in decision-making. These models face challenges in assessing uncertainty, leading to overconfident predictions. To overcome these limitations, we integrate uncertainty calibration and interpretability into a retrieval pipeline. Specifically, we introduce Bayesian methodologies and multi-perspective retrieval to calibrate uncertainty within a retrieval pipeline. We incorporate techniques such as LIME and SHAP to analyze the behavior of a black-box reranker model. The importance scores derived from these explanation methodologies serve as supplementary relevance scores to enhance the base reranker model. We evaluate the resulting performance enhancements achieved through uncertainty calibration and interpretable reranking on Question Answering and Fact Checking tasks. Our methods demonstrate substantial performance improvements across three KILT datasets.