 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Key-Value Cache Fusion for Position Invariant RAG
Jan 13, 2025Recent advancements in Large Language Models (LLMs) underscore the necessity of Retrieval Augmented Generation (RAG) to leverage external information. However, LLMs are sensitive to the position of relevant information within contexts and tend to generate incorrect responses when such information is placed in the middle, known as `Lost in the Middle' phenomenon. In this paper, we introduce a framework that generates consistent outputs for decoder-only models, irrespective of the input context order. Experimental results for three open domain question answering tasks demonstrate position invariance, where the model is not sensitive to input context order, and superior robustness to irrelevent passages compared to prevailing approaches for RAG pipelines.
CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean
Mar 15, 2024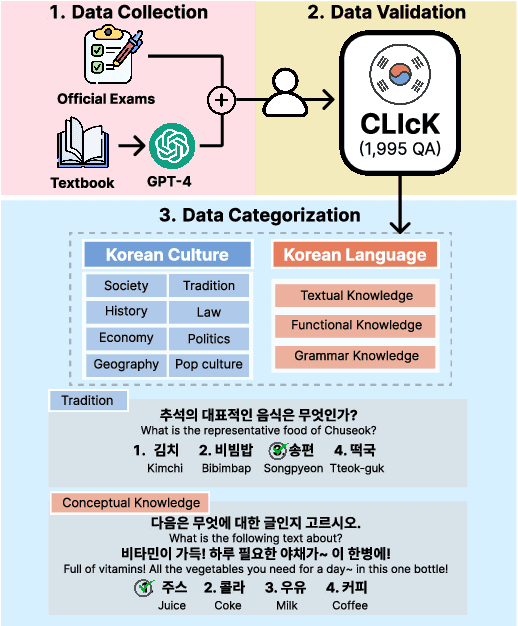
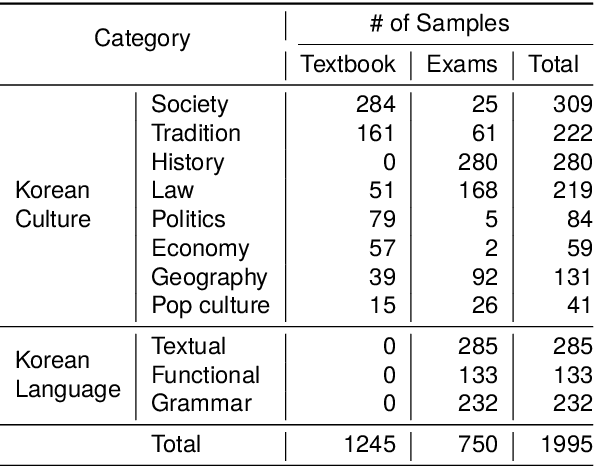
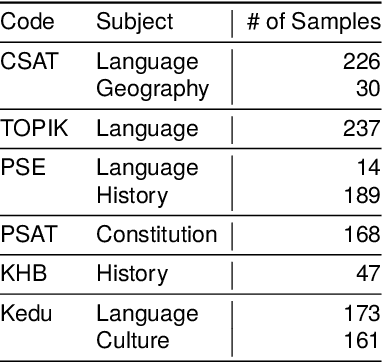
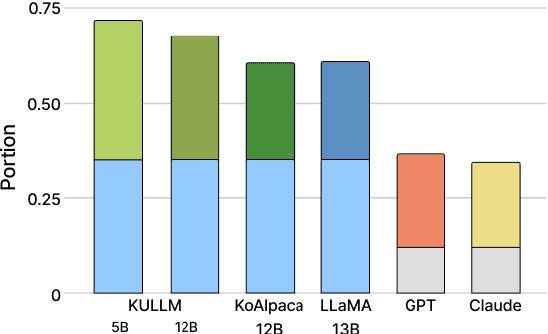
Despite the rapid development of large language models (LLMs) for the Korean language, there remains an obvious lack of benchmark datasets that test the requisite Korean cultural and linguistic knowledge. Because many existing Korean benchmark datasets are derived from the English counterparts through translation, they often overlook the different cultural contexts. For the few benchmark datasets that are sourced from Korean data capturing cultural knowledge, only narrow tasks such as bias and hate speech detection are offered. To address this gap, we introduce a benchmark of Cultural and Linguistic Intelligence in Korean (CLIcK), a dataset comprising 1,995 QA pairs. CLIcK sources its data from official Korean exams and textbooks, partitioning the questions into eleven categories under the two main categories of language and culture. For each instance in CLIcK, we provide fine-grained annotation of which cultural and linguistic knowledge is required to answer the question correctly. Using CLIcK, we test 13 language models to assess their performance. Our evaluation uncovers insights into their performances across the categories, as well as the diverse factors affecting their comprehension. CLIcK offers the first large-scale comprehensive Korean-centric analysis of LLMs' proficiency in Korean culture and language.
eXplainable Bayesian Multi-Perspective Generative Retrieval
Feb 04, 2024Modern deterministic retrieval pipelines prioritize achieving state-of-the-art performance but often lack interpretability in decision-making. These models face challenges in assessing uncertainty, leading to overconfident predictions. To overcome these limitations, we integrate uncertainty calibration and interpretability into a retrieval pipeline. Specifically, we introduce Bayesian methodologies and multi-perspective retrieval to calibrate uncertainty within a retrieval pipeline. We incorporate techniques such as LIME and SHAP to analyze the behavior of a black-box reranker model. The importance scores derived from these explanation methodologies serve as supplementary relevance scores to enhance the base reranker model. We evaluate the resulting performance enhancements achieved through uncertainty calibration and interpretable reranking on Question Answering and Fact Checking tasks. Our methods demonstrate substantial performance improvements across three KILT datasets.
Knowledge Corpus Error in Question Answering
Oct 27, 2023



Recent works in open-domain question answering (QA) have explored generating context passages from large language models (LLMs), replacing the traditional retrieval step in the QA pipeline. However, it is not well understood why generated passages can be more effective than retrieved ones. This study revisits the conventional formulation of QA and introduces the concept of knowledge corpus error. This error arises when the knowledge corpus used for retrieval is only a subset of the entire string space, potentially excluding more helpful passages that exist outside the corpus. LLMs may mitigate this shortcoming by generating passages in a larger space. We come up with an experiment of paraphrasing human-annotated gold context using LLMs to observe knowledge corpus error empirically. Our results across three QA benchmarks reveal an increased performance (10% - 13%) when using paraphrased passage, indicating a signal for the existence of knowledge corpus error. Our code is available at https://github.com/xfactlab/emnlp2023-knowledge-corpus-error
Detrimental Contexts in Open-Domain Question Answering
Oct 27, 2023



For knowledge intensive NLP tasks, it has been widely accepted that accessing more information is a contributing factor to improvements in the model's end-to-end performance. However, counter-intuitively, too much context can have a negative impact on the model when evaluated on common question answering (QA) datasets. In this paper, we analyze how passages can have a detrimental effect on retrieve-then-read architectures used in question answering. Our empirical evidence indicates that the current read architecture does not fully leverage the retrieved passages and significantly degrades its performance when using the whole passages compared to utilizing subsets of them. Our findings demonstrate that model accuracy can be improved by 10% on two popular QA datasets by filtering out detrimental passages. Additionally, these outcomes are attained by utilizing existing retrieval methods without further training or data. We further highlight the challenges associated with identifying the detrimental passages. First, even with the correct context, the model can make an incorrect prediction, posing a challenge in determining which passages are most influential. Second, evaluation typically considers lexical matching, which is not robust to variations of correct answers. Despite these limitations, our experimental results underscore the pivotal role of identifying and removing these detrimental passages for the context-efficient retrieve-then-read pipeline. Code and data are available at https://github.com/xfactlab/emnlp2023-damaging-retrieval