 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriosity-Driven Multi-Agent Exploration with Mixed Objectives
Oct 29, 2022



Intrinsic rewards have been increasingly used to mitigate the sparse reward problem in single-agent reinforcement learning. These intrinsic rewards encourage the agent to look for novel experiences, guiding the agent to explore the environment sufficiently despite the lack of extrinsic rewards. Curiosity-driven exploration is a simple yet efficient approach that quantifies this novelty as the prediction error of the agent's curiosity module, an internal neural network that is trained to predict the agent's next state given its current state and action. We show here, however, that naively using this curiosity-driven approach to guide exploration in sparse reward cooperative multi-agent environments does not consistently lead to improved results. Straightforward multi-agent extensions of curiosity-driven exploration take into consideration either individual or collective novelty only and thus, they do not provide a distinct but collaborative intrinsic reward signal that is essential for learning in cooperative multi-agent tasks. In this work, we propose a curiosity-driven multi-agent exploration method that has the mixed objective of motivating the agents to explore the environment in ways that are individually and collectively novel. First, we develop a two-headed curiosity module that is trained to predict the corresponding agent's next observation in the first head and the next joint observation in the second head. Second, we design the intrinsic reward formula to be the sum of the individual and joint prediction errors of this curiosity module. We empirically show that the combination of our curiosity module architecture and intrinsic reward formulation guides multi-agent exploration more efficiently than baseline approaches, thereby providing the best performance boost to MARL algorithms in cooperative navigation environments with sparse rewards.
QOPT: Optimistic Value Function Decentralization for Cooperative Multi-Agent Reinforcement Learning
Jun 22, 2020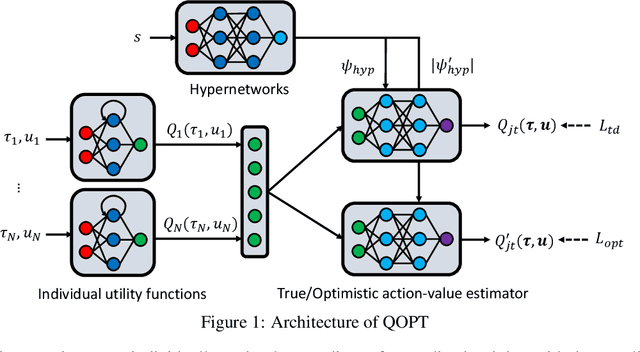

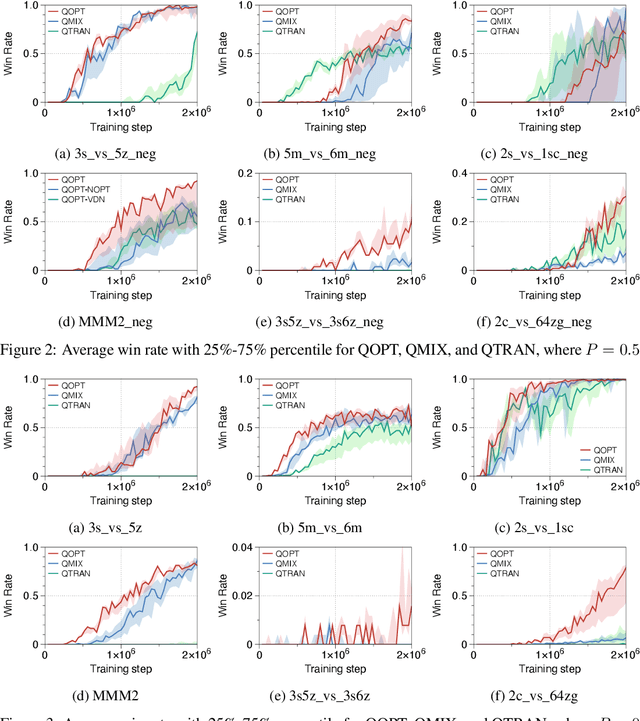

We propose a novel value-based algorithm for cooperative multi-agent reinforcement learning, under the paradigm of centralized training with decentralized execution. The proposed algorithm, coined QOPT, is based on the "optimistic" training scheme using two action-value estimators with separate roles: (i) true action-value estimation and (ii) decentralization of optimal action. By construction, our framework allows the latter action-value estimator to achieve (ii) while representing a richer class of joint action-value estimators than that of the state-of-the-art algorithm, i.e., QMIX. Our experiments demonstrate that QOPT newly achieves state-of-the-art performance in the StarCraft Multi-Agent Challenge environment. In particular, ours significantly outperform the baselines for the case where non-cooperative behaviors are penalized more aggressively.