 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQOPT: Optimistic Value Function Decentralization for Cooperative Multi-Agent Reinforcement Learning
Paper and Code
Jun 22, 2020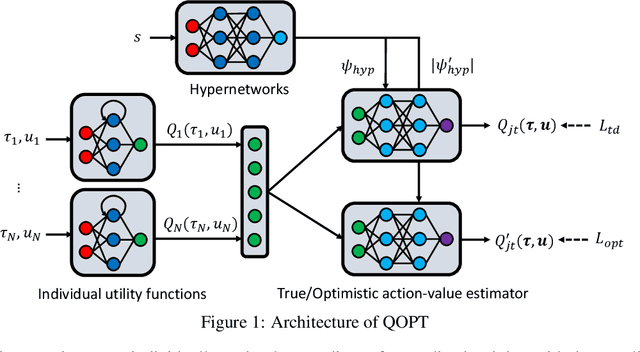

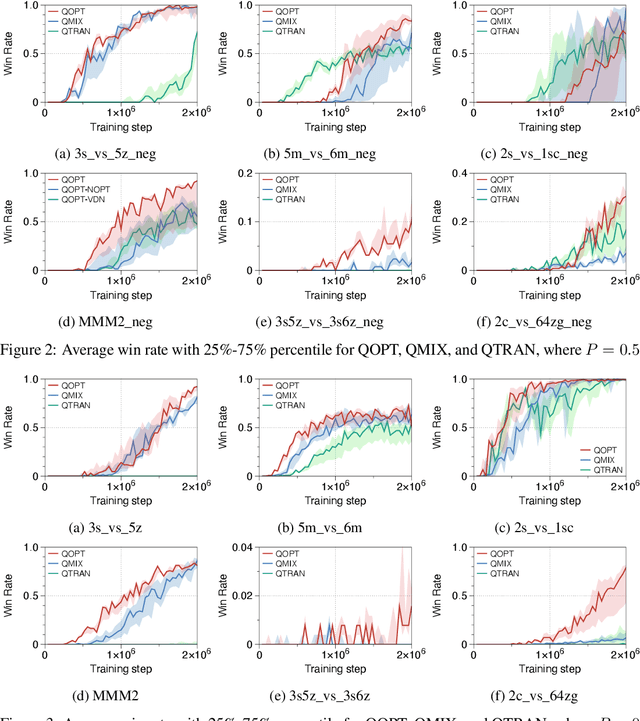

We propose a novel value-based algorithm for cooperative multi-agent reinforcement learning, under the paradigm of centralized training with decentralized execution. The proposed algorithm, coined QOPT, is based on the "optimistic" training scheme using two action-value estimators with separate roles: (i) true action-value estimation and (ii) decentralization of optimal action. By construction, our framework allows the latter action-value estimator to achieve (ii) while representing a richer class of joint action-value estimators than that of the state-of-the-art algorithm, i.e., QMIX. Our experiments demonstrate that QOPT newly achieves state-of-the-art performance in the StarCraft Multi-Agent Challenge environment. In particular, ours significantly outperform the baselines for the case where non-cooperative behaviors are penalized more aggressively.