 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
On the Estimation of Image-matching Uncertainty in Visual Place Recognition
Mar 31, 2024



In Visual Place Recognition (VPR) the pose of a query image is estimated by comparing the image to a map of reference images with known reference poses. As is typical for image retrieval problems, a feature extractor maps the query and reference images to a feature space, where a nearest neighbor search is then performed. However, till recently little attention has been given to quantifying the confidence that a retrieved reference image is a correct match. Highly certain but incorrect retrieval can lead to catastrophic failure of VPR-based localization pipelines. This work compares for the first time the main approaches for estimating the image-matching uncertainty, including the traditional retrieval-based uncertainty estimation, more recent data-driven aleatoric uncertainty estimation, and the compute-intensive geometric verification. We further formulate a simple baseline method, ``SUE'', which unlike the other methods considers the freely-available poses of the reference images in the map. Our experiments reveal that a simple L2-distance between the query and reference descriptors is already a better estimate of image-matching uncertainty than current data-driven approaches. SUE outperforms the other efficient uncertainty estimation methods, and its uncertainty estimates complement the computationally expensive geometric verification approach. Future works for uncertainty estimation in VPR should consider the baselines discussed in this work.
CoPR: Towards Accurate Visual Localization With Continuous Place-descriptor Regression
Apr 14, 2023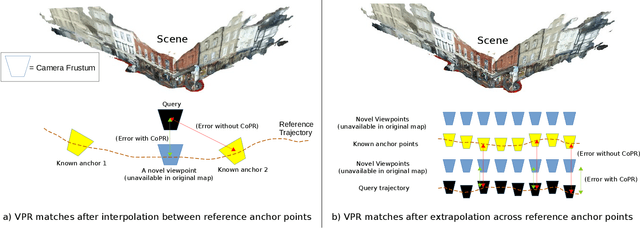



Visual Place Recognition (VPR) is an image-based localization method that estimates the camera location of a query image by retrieving the most similar reference image from a map of geo-tagged reference images. In this work, we look into two fundamental bottlenecks for its localization accuracy: reference map sparseness and viewpoint invariance. Firstly, the reference images for VPR are only available at sparse poses in a map, which enforces an upper bound on the maximum achievable localization accuracy through VPR. We therefore propose Continuous Place-descriptor Regression (CoPR) to densify the map and improve localization accuracy. We study various interpolation and extrapolation models to regress additional VPR feature descriptors from only the existing references. Secondly, we compare different feature encoders and show that CoPR presents value for all of them. We evaluate our models on three existing public datasets and report on average around 30% improvement in VPR-based localization accuracy using CoPR, on top of the 15% increase by using a viewpoint-variant loss for the feature encoder. The complementary relation between CoPR and Relative Pose Estimation is also discussed.
A Benchmark Comparison of Visual Place Recognition Techniques for Resource-Constrained Embedded Platforms
Sep 22, 2021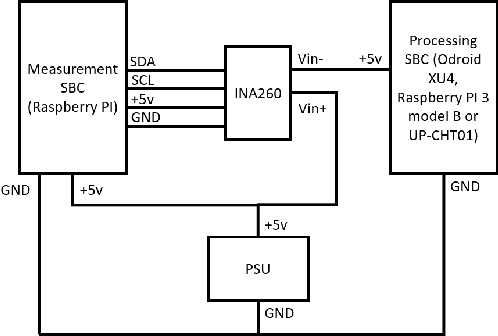
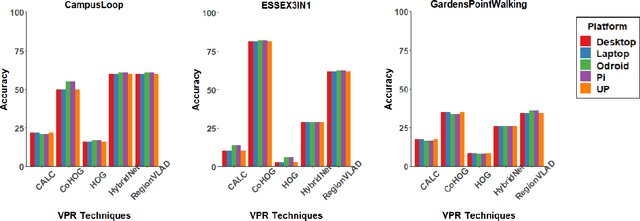
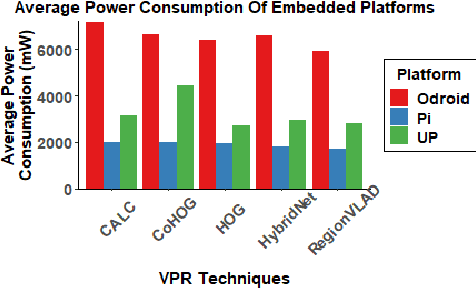
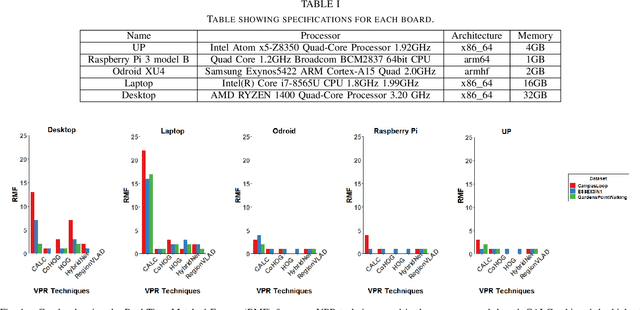
Visual Place Recognition (VPR) has been a subject of significant research over the last 15 to 20 years. VPR is a fundamental task for autonomous navigation as it enables self-localization within an environment. Although robots are often equipped with resource-constrained hardware, the computational requirements of and effects on VPR techniques have received little attention. In this work, we present a hardware-focused benchmark evaluation of a number of state-of-the-art VPR techniques on public datasets. We consider popular single board computers, including ODroid, UP and Raspberry Pi 3, in addition to a commodity desktop and laptop for reference. We present our analysis based on several key metrics, including place-matching accuracy, image encoding time, descriptor matching time and memory needs. Key questions addressed include: (1) How does the performance accuracy of a VPR technique change with processor architecture? (2) How does power consumption vary for different VPR techniques and embedded platforms? (3) How much does descriptor size matter in comparison to today's embedded platforms' storage? (4) How does the performance of a high-end platform relate to an on-board low-end embedded platform for VPR? The extensive analysis and results in this work serve not only as a benchmark for the VPR community, but also provide useful insights for real-world adoption of VPR applications.
Sequence-Based Filtering for Visual Route-Based Navigation: Analysing the Benefits, Trade-offs and Design Choices
Mar 02, 2021
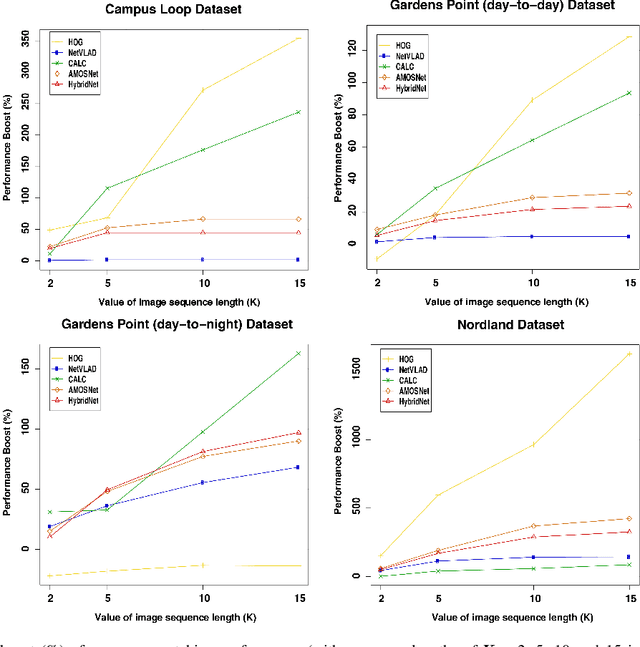
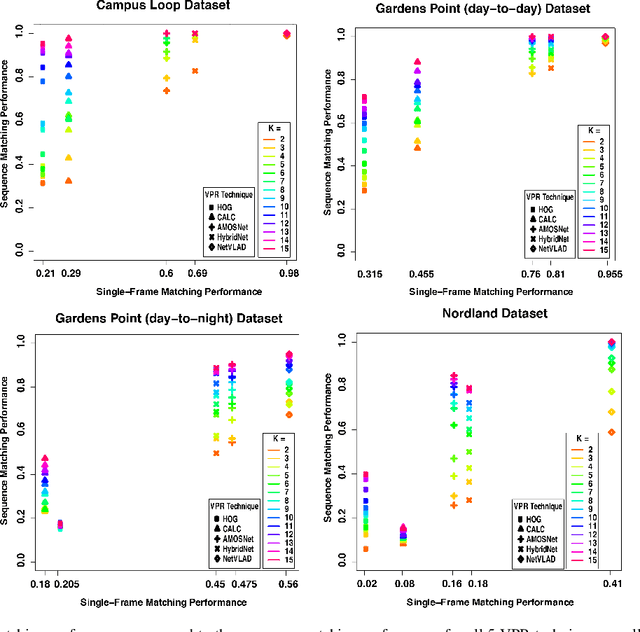
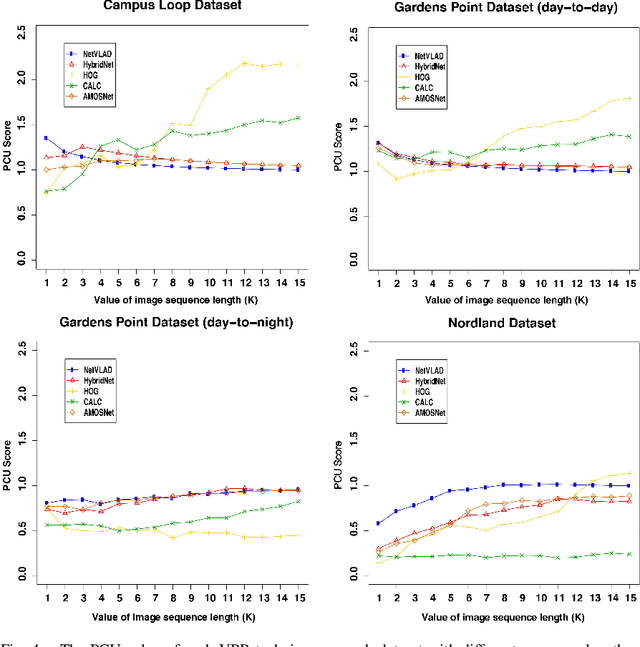
Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place using visual information under environmental, viewpoint and appearance changes. An emerging trend in VPR is the use of sequence-based filtering methods on top of single-frame-based place matching techniques for route-based navigation. The combination leads to varying levels of potential place matching performance boosts at increased computational costs. This raises a number of interesting research questions: How does performance boost (due to sequential filtering) vary along the entire spectrum of single-frame-based matching methods? How does sequence matching length affect the performance curve? Which specific combinations provide a good trade-off between performance and computation? However, there is lack of previous work looking at these important questions and most of the sequence-based filtering work to date has been used without a systematic approach. To bridge this research gap, this paper conducts an in-depth investigation of the relationship between the performance of single-frame-based place matching techniques and the use of sequence-based filtering on top of those methods. It analyzes individual trade-offs, properties and limitations for different combinations of single-frame-based and sequential techniques. A number of state-of-the-art VPR methods and widely used public datasets are utilized to present the findings that contain a number of meaningful insights for the VPR community.
ConvSequential-SLAM: A Sequence-based, Training-less Visual Place Recognition Technique for Changing Environments
Sep 28, 2020



Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place under changing viewpoints and appearances. A large number of handcrafted and deep-learning-based VPR techniques exist, where the former suffer from appearance changes and the latter have significant computational needs. In this paper, we present a new handcrafted VPR technique that achieves state-of-the-art place matching performance under challenging conditions. Our technique combines the best of 2 existing trainingless VPR techniques, SeqSLAM and CoHOG, which are each robust to conditional and viewpoint changes, respectively. This blend, namely ConvSequential-SLAM, utilises sequential information and block-normalisation to handle appearance changes, while using regional-convolutional matching to achieve viewpoint-invariance. We analyse content-overlap in-between query frames to find a minimum sequence length, while also re-using the image entropy information for environment-based sequence length tuning. State-of-the-art performance is reported in contrast to 8 contemporary VPR techniques on 4 public datasets. Qualitative insights and an ablation study on sequence length are also provided.
VPR-Bench: An Open-Source Visual Place Recognition Evaluation Framework with Quantifiable Viewpoint and Appearance Change
May 17, 2020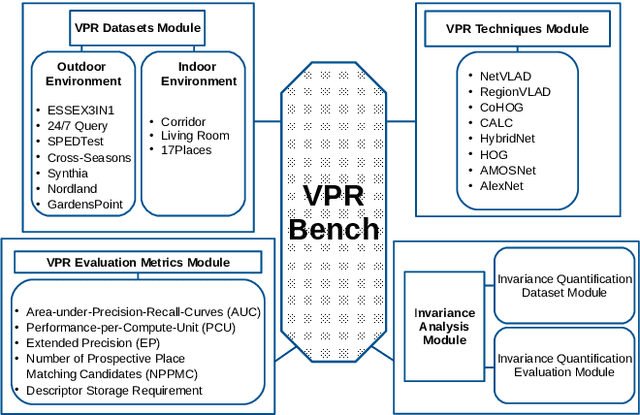
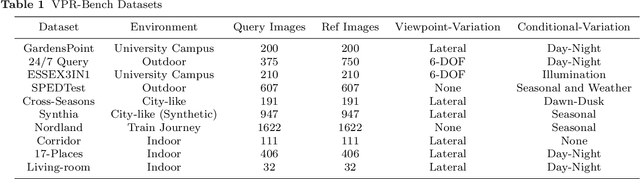

Visual Place Recognition (VPR) is the process of recognising a previously visited place using visual information, often under varying appearance conditions and viewpoint changes and with computational constraints. VPR is a critical component of many autonomous navigation systems ranging from autonomous vehicles to drones. While the concept of place recognition has been around for many years, VPR research has grown rapidly as a field over the past decade due to both improving camera hardware technologies and its suitability for application of deep learning-based techniques. With this growth however has come field fragmentation, lack of standardisation and a disconnect between current performance metrics and the actual utility of a VPR technique at application-deployment. In this paper we address these key challenges through a new comprehensive open-source evaluation framework, dubbed 'VPR-Bench'. VPR-Bench introduces two much-needed capabilities for researchers: firstly, quantification of viewpoint and illumination variation, replacing what has largely been assessed qualitatively in the past, and secondly, new metrics 'Extended precision' (EP), 'Performance-Per-Compute-Unit' (PCU) and 'Number of Prospective Place Matching Candidates' (NPPMC). These new metrics complement the limitations of traditional Precision-Recall curves, by providing measures that are more informative to the wide range of potential VPR applications. Mechanistically, we develop new unified templates that facilitate the implementation, deployment and evaluation of a wide range of VPR techniques and datasets. We incorporate the most comprehensive combination of state-of-the-art VPR techniques and datasets to date into VPR-Bench and demonstrate how it provides a rich range of previously inaccessible insights, such as the nuanced relationship between viewpoint invariance, different types of VPR techniques and datasets.
Are State-of-the-art Visual Place Recognition Techniques any Good for Aerial Robotics?
May 22, 2019



Visual Place Recognition (VPR) has seen significant advances at the frontiers of matching performance and computational superiority over the past few years. However, these evaluations are performed for ground-based mobile platforms and cannot be generalized to aerial platforms. The degree of viewpoint variation experienced by aerial robots is complex, with their processing power and on-board memory limited by payload size and battery ratings. Therefore, in this paper, we collect $8$ state-of-the-art VPR techniques that have been previously evaluated for ground-based platforms and compare them on $2$ recently proposed aerial place recognition datasets with three prime focuses: a) Matching performance b) Processing power consumption c) Projected memory requirements. This gives a birds-eye view of the applicability of contemporary VPR research to aerial robotics and lays down the the nature of challenges for aerial-VPR.
Levelling the Playing Field: A Comprehensive Comparison of Visual Place Recognition Approaches under Changing Conditions
Mar 21, 2019



In recent years there has been significant improvement in the capability of Visual Place Recognition (VPR) methods, building on the success of both hand-crafted and learnt visual features, temporal filtering and usage of semantic scene information. The wide range of approaches and the relatively recent growth in interest in the field has meant that a wide range of datasets and assessment methodologies have been proposed, often with a focus only on precision-recall type metrics, making comparison difficult. In this paper we present a comprehensive approach to evaluating the performance of 10 state-of-the-art recently-developed VPR techniques, which utilizes three standardized metrics: (a) Matching Performance b) Matching Time c) Memory Footprint. Together this analysis provides an up-to-date and widely encompassing snapshot of the various strengths and weaknesses of contemporary approaches to the VPR problem. The aim of this work is to help move this particular research field towards a more mature and unified approach to the problem, enabling better comparison and hence more progress to be made in future research.
Memorable Maps: A Framework for Re-defining Places in Visual Place Recognition
Mar 21, 2019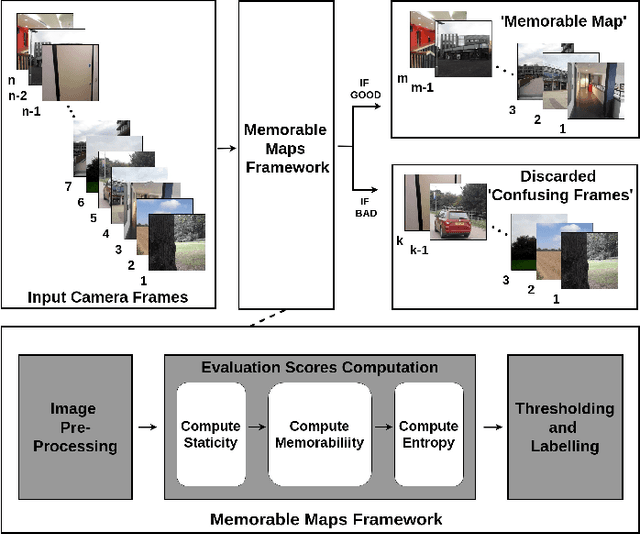


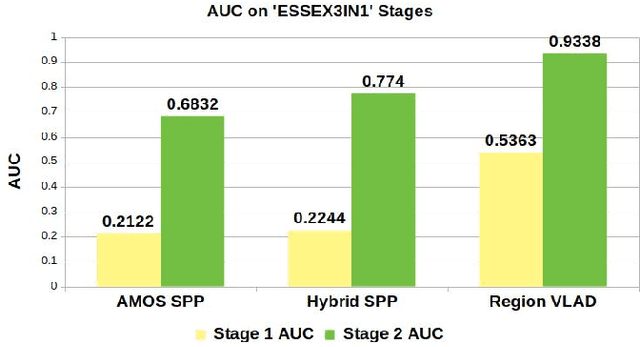
This paper presents a cognition-inspired agnostic framework for building a map for Visual Place Recognition. This framework draws inspiration from human-memorability, utilizes the traditional image entropy concept and computes the static content in an image; thereby presenting a tri-folded criterion to assess the 'memorability' of an image for visual place recognition. A dataset namely 'ESSEX3IN1' is created, composed of highly confusing images from indoor, outdoor and natural scenes for analysis. When used in conjunction with state-of-the-art visual place recognition methods, the proposed framework provides significant performance boost to these techniques, as evidenced by results on ESSEX3IN1 and other public datasets.