 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
UNION: Unsupervised 3D Object Detection using Object Appearance-based Pseudo-Classes
May 24, 2024Unsupervised 3D object detection methods have emerged to leverage vast amounts of data efficiently without requiring manual labels for training. Recent approaches rely on dynamic objects for learning to detect objects but penalize the detections of static instances during training. Multiple rounds of (self) training are used in which detected static instances are added to the set of training targets; this procedure to improve performance is computationally expensive. To address this, we propose the method UNION. We use spatial clustering and self-supervised scene flow to obtain a set of static and dynamic object proposals from LiDAR. Subsequently, object proposals' visual appearances are encoded to distinguish static objects in the foreground and background by selecting static instances that are visually similar to dynamic objects. As a result, static and dynamic foreground objects are obtained together, and existing detectors can be trained with a single training. In addition, we extend 3D object discovery to detection by using object appearance-based cluster labels as pseudo-class labels for training object classification. We conduct extensive experiments on the nuScenes dataset and increase the state-of-the-art performance for unsupervised object discovery, i.e. UNION more than doubles the average precision to 33.9. The code will be made publicly available.
SliceMatch: Geometry-guided Aggregation for Cross-View Pose Estimation
Dec 05, 2022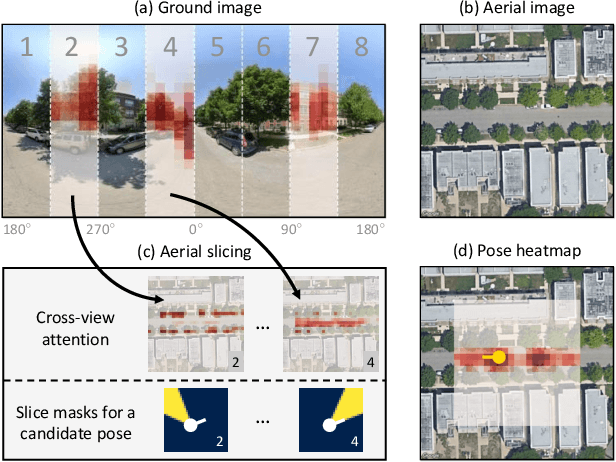

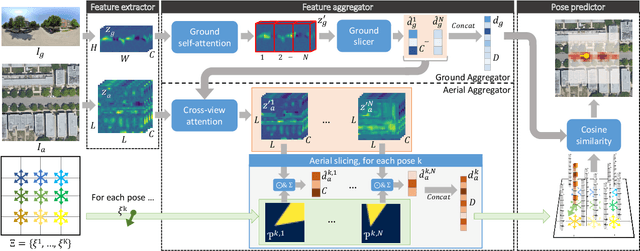

This work addresses cross-view camera pose estimation, i.e., determining the 3-DoF camera pose of a given ground-level image w.r.t. an aerial image of the local area. We propose SliceMatch, which consists of ground and aerial feature extractors, feature aggregators, and a pose predictor. The feature extractors extract dense features from the ground and aerial images. Given a set of candidate camera poses, the feature aggregators construct a single ground descriptor and a set of rotational equivariant pose-dependent aerial descriptors. Notably, our novel aerial feature aggregator has a cross-view attention module for ground-view guided aerial feature selection, and utilizes the geometric projection of the ground camera's viewing frustum on the aerial image to pool features. The efficient construction of aerial descriptors is achieved by using precomputed masks and by re-assembling the aerial descriptors for rotated poses. SliceMatch is trained using contrastive learning and pose estimation is formulated as a similarity comparison between the ground descriptor and the aerial descriptors. SliceMatch outperforms the state-of-the-art by 19% and 62% in median localization error on the VIGOR and KITTI datasets, with 3x FPS of the fastest baseline.