 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Based Filtering for Visual Route-Based Navigation: Analysing the Benefits, Trade-offs and Design Choices
Mar 02, 2021
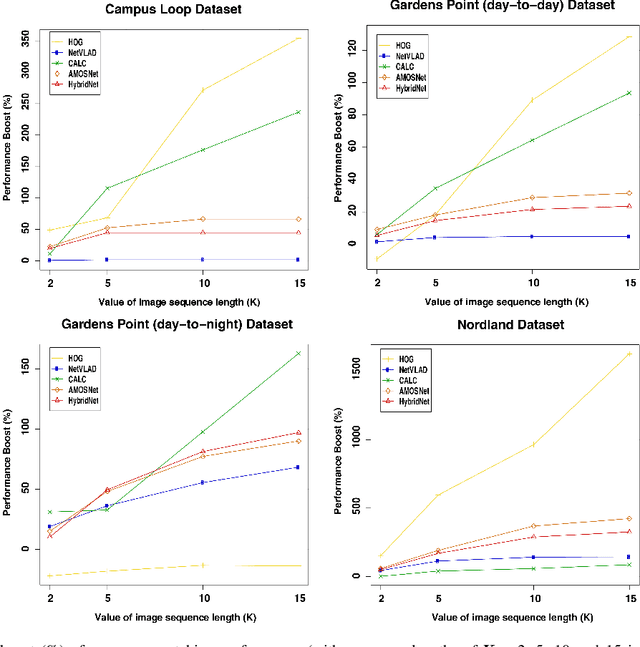
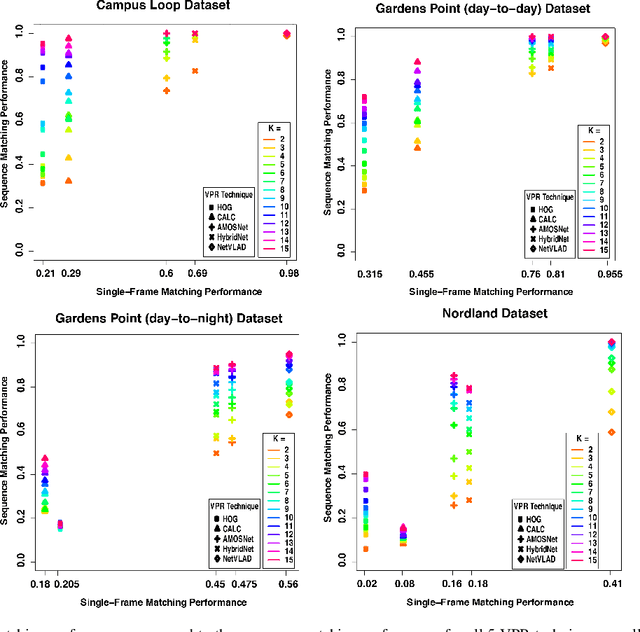
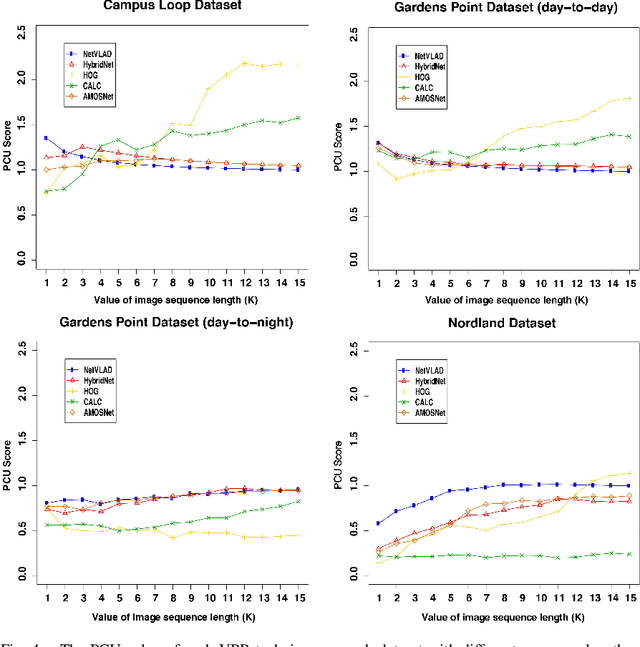
Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place using visual information under environmental, viewpoint and appearance changes. An emerging trend in VPR is the use of sequence-based filtering methods on top of single-frame-based place matching techniques for route-based navigation. The combination leads to varying levels of potential place matching performance boosts at increased computational costs. This raises a number of interesting research questions: How does performance boost (due to sequential filtering) vary along the entire spectrum of single-frame-based matching methods? How does sequence matching length affect the performance curve? Which specific combinations provide a good trade-off between performance and computation? However, there is lack of previous work looking at these important questions and most of the sequence-based filtering work to date has been used without a systematic approach. To bridge this research gap, this paper conducts an in-depth investigation of the relationship between the performance of single-frame-based place matching techniques and the use of sequence-based filtering on top of those methods. It analyzes individual trade-offs, properties and limitations for different combinations of single-frame-based and sequential techniques. A number of state-of-the-art VPR methods and widely used public datasets are utilized to present the findings that contain a number of meaningful insights for the VPR community.
ConvSequential-SLAM: A Sequence-based, Training-less Visual Place Recognition Technique for Changing Environments
Sep 28, 2020



Visual Place Recognition (VPR) is the ability to correctly recall a previously visited place under changing viewpoints and appearances. A large number of handcrafted and deep-learning-based VPR techniques exist, where the former suffer from appearance changes and the latter have significant computational needs. In this paper, we present a new handcrafted VPR technique that achieves state-of-the-art place matching performance under challenging conditions. Our technique combines the best of 2 existing trainingless VPR techniques, SeqSLAM and CoHOG, which are each robust to conditional and viewpoint changes, respectively. This blend, namely ConvSequential-SLAM, utilises sequential information and block-normalisation to handle appearance changes, while using regional-convolutional matching to achieve viewpoint-invariance. We analyse content-overlap in-between query frames to find a minimum sequence length, while also re-using the image entropy information for environment-based sequence length tuning. State-of-the-art performance is reported in contrast to 8 contemporary VPR techniques on 4 public datasets. Qualitative insights and an ablation study on sequence length are also provided.