 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Inception-Residual-Based Architecture with Multi-Objective Loss for Detecting Respiratory Anomalies
Mar 07, 2023
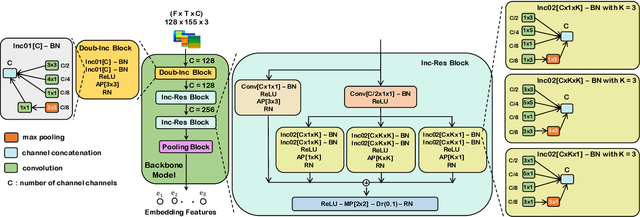

This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Initially, our system begins with audio feature extraction using Gammatone and Continuous Wavelet transformation. This step aims to transform the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed system integrates Inception-residual-based backbone models combined with multi-head attention and multi-objective loss to classify respiratory anomalies. In this work, we conducted experiments over the benchmark dataset of SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) proposed by the IEEE BioCAS 2022 challenge. As regards the Score computed by an average between the average score and harmonic score, our proposed system gained significant improvements of 9.7%, 15.8%, 17.0%, and 9.4% in Task 1-1, Task 1-2, Task 2-1, and Task 2-2 compared to the challenge baseline system. Notably, we achieved the Top-1 performance in Task 2-1 with the highest Score of 73.7%.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Mar 02, 2022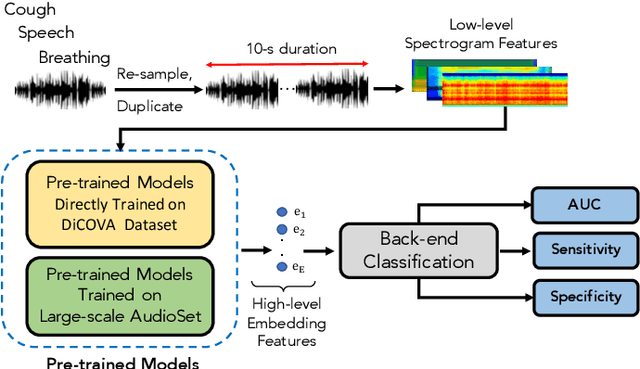

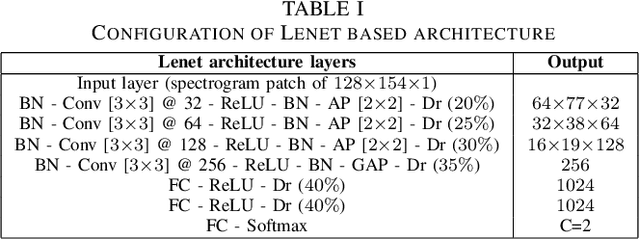
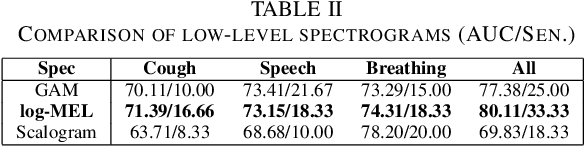
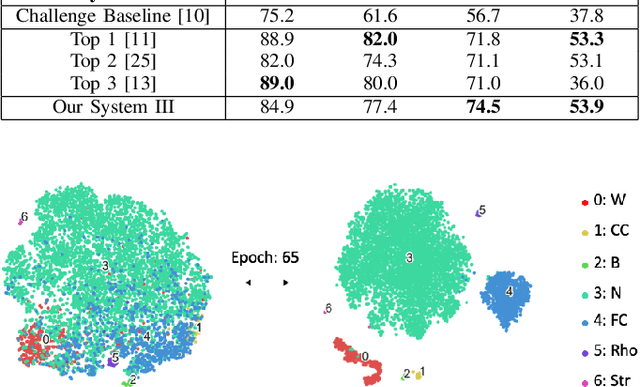
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
Using Machine Learning for Anomaly Detection on a System-on-Chip under Gamma Radiation
Jan 05, 2022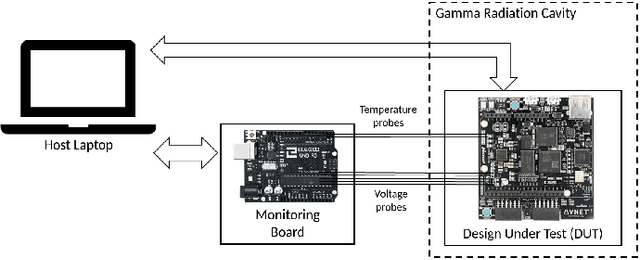
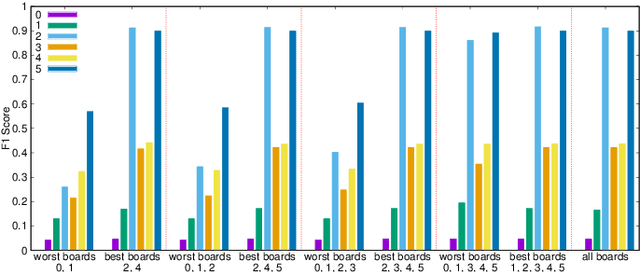
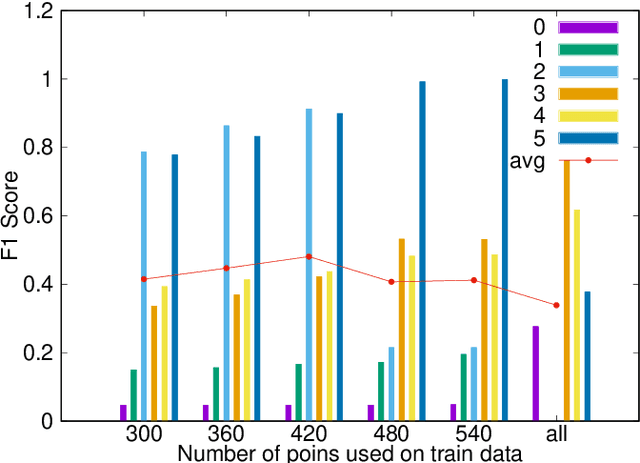
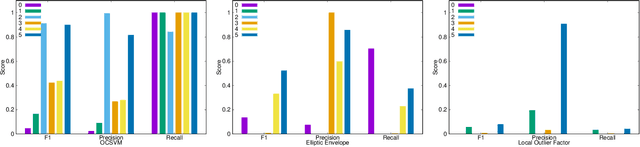
The emergence of new nanoscale technologies has imposed significant challenges to designing reliable electronic systems in radiation environments. A few types of radiation like Total Ionizing Dose (TID) effects often cause permanent damages on such nanoscale electronic devices, and current state-of-the-art technologies to tackle TID make use of expensive radiation-hardened devices. This paper focuses on a novel and different approach: using machine learning algorithms on consumer electronic level Field Programmable Gate Arrays (FPGAs) to tackle TID effects and monitor them to replace before they stop working. This condition has a research challenge to anticipate when the board results in a total failure due to TID effects. We observed internal measurements of the FPGA boards under gamma radiation and used three different anomaly detection machine learning (ML) algorithms to detect anomalies in the sensor measurements in a gamma-radiated environment. The statistical results show a highly significant relationship between the gamma radiation exposure levels and the board measurements. Moreover, our anomaly detection results have shown that a One-Class Support Vector Machine with Radial Basis Function Kernel has an average Recall score of 0.95. Also, all anomalies can be detected before the boards stop working.
A Deep Multi-View Learning Framework for City Event Extraction from Twitter Data Streams
May 28, 2017

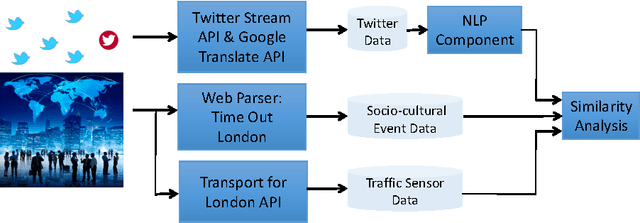
Cities have been a thriving place for citizens over the centuries due to their complex infrastructure. The emergence of the Cyber-Physical-Social Systems (CPSS) and context-aware technologies boost a growing interest in analysing, extracting and eventually understanding city events which subsequently can be utilised to leverage the citizen observations of their cities. In this paper, we investigate the feasibility of using Twitter textual streams for extracting city events. We propose a hierarchical multi-view deep learning approach to contextualise citizen observations of various city systems and services. Our goal has been to build a flexible architecture that can learn representations useful for tasks, thus avoiding excessive task-specific feature engineering. We apply our approach on a real-world dataset consisting of event reports and tweets of over four months from San Francisco Bay Area dataset and additional datasets collected from London. The results of our evaluations show that our proposed solution outperforms the existing models and can be used for extracting city related events with an averaged accuracy of 81% over all classes. To further evaluate the impact of our Twitter event extraction model, we have used two sources of authorised reports through collecting road traffic disruptions data from Transport for London API, and parsing the Time Out London website for sociocultural events. The analysis showed that 49.5% of the Twitter traffic comments are reported approximately five hours prior to the authorities official records. Moreover, we discovered that amongst the scheduled sociocultural event topics; tweets reporting transportation, cultural and social events are 31.75% more likely to influence the distribution of the Twitter comments than sport, weather and crime topics.