 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Based Deep Learning Frameworks for Detecting COVID-19
Mar 02, 2022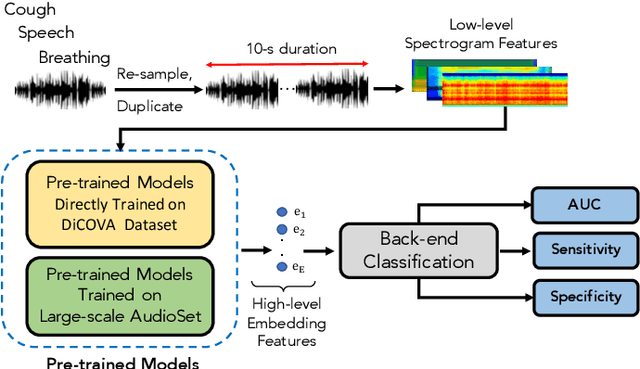

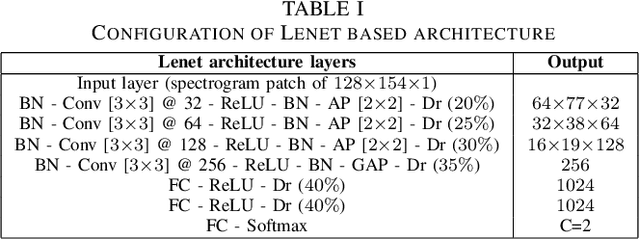
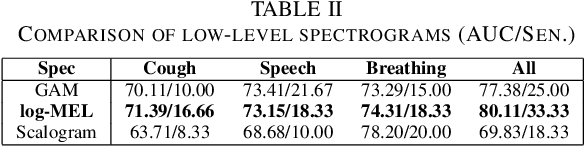
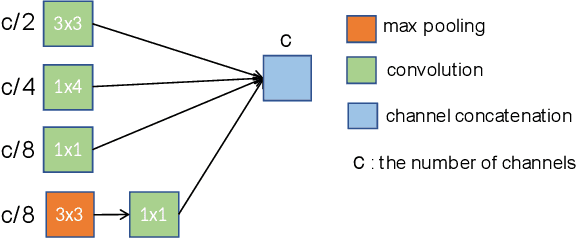
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
An Ensemble of Deep Learning Frameworks Applied For Predicting Respiratory Anomalies
Jan 09, 2022


In this paper, we evaluate various deep learning frameworks for detecting respiratory anomalies from input audio recordings. To this end, we firstly transform audio respiratory cycles collected from patients into spectrograms where both temporal and spectral features are presented, referred to as the front-end feature extraction. We then feed the spectrograms into back-end deep learning networks for classifying these respiratory cycles into certain categories. Finally, results from high-performed deep learning frameworks are fused to obtain the best score. Our experiments on ICBHI benchmark dataset achieve the highest ICBHI score of 57.3 from a late fusion of inception based and transfer learning based deep learning frameworks, which outperforms the state-of-the-art systems.
An Audio-Visual Dataset and Deep Learning Frameworks for Crowded Scene Classification
Dec 16, 2021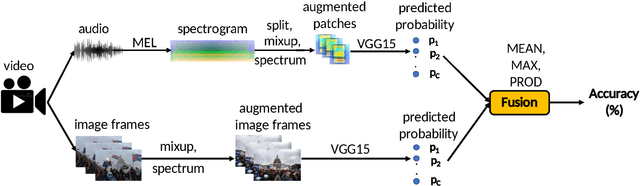
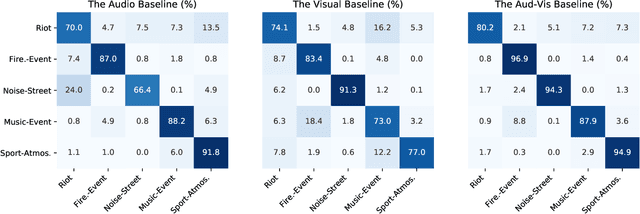
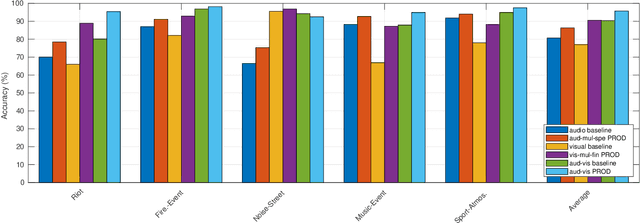
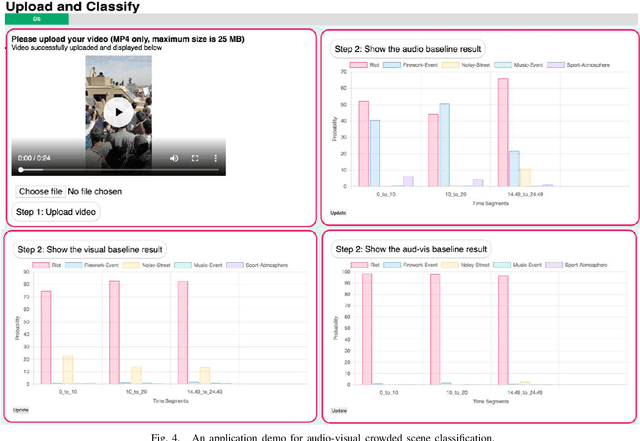
This paper presents a task of audio-visual scene classification (SC) where input videos are classified into one of five real-life crowded scenes: 'Riot', 'Noise-Street', 'Firework-Event', 'Music-Event', and 'Sport-Atmosphere'. To this end, we firstly collect an audio-visual dataset (videos) of these five crowded contexts from Youtube (in-the-wild scenes). Then, a wide range of deep learning frameworks are proposed to deploy either audio or visual input data independently. Finally, results obtained from high-performed deep learning frameworks are fused to achieve the best accuracy score. Our experimental results indicate that audio and visual input factors independently contribute to the SC task's performance. Significantly, an ensemble of deep learning frameworks exploring either audio or visual input data can achieve the best accuracy of 95.7%.