 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Frequency Bands on Acoustic Anomaly Detection of Machines using Deep Learning Based Model
Mar 01, 2024



In this paper, we propose a deep learning based model for Acoustic Anomaly Detection of Machines, the task for detecting abnormal machines by analysing the machine sound. By conducting extensive experiments, we indicate that multiple techniques of pseudo audios, audio segment, data augmentation, Mahalanobis distance, and narrow frequency bands, which mainly focus on feature engineering, are effective to enhance the system performance. Among the evaluating techniques, the narrow frequency bands presents a significant impact. Indeed, our proposed model, which focuses on the narrow frequency bands, outperforms the DCASE baseline on the benchmark dataset of DCASE 2022 Task 2 Development set. The important role of the narrow frequency bands indicated in this paper inspires the research community on the task of Acoustic Anomaly Detection of Machines to further investigate and propose novel network architectures focusing on the frequency bands.
A Deep Learning Architecture with Spatio-Temporal Focusing for Detecting Respiratory Anomalies
Jun 25, 2023This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Our system initially performs audio feature extraction using Continuous Wavelet transformation. This transformation converts the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed deep learning architecture inspired by the Inception-residual-based backbone performs the spatial-temporal focusing and multi-head attention mechanism to classify respiratory anomalies. In this work, we evaluate our proposed models on the benchmark SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) database proposed by the IEEE BioCAS 2023 challenge. As regards the Score computed by an average between the average score and harmonic score, our robust system has achieved Top-1 performance with Scores of 0.810, 0.667, 0.744, and 0.608 in Tasks 1-1, 1-2, 2-1, and 2-2, respectively.
Low-complexity deep learning frameworks for acoustic scene classification using teacher-student scheme and multiple spectrograms
May 16, 2023In this technical report, a low-complexity deep learning system for acoustic scene classification (ASC) is presented. The proposed system comprises two main phases: (Phase I) Training a teacher network; and (Phase II) training a student network using distilled knowledge from the teacher. In the first phase, the teacher, which presents a large footprint model, is trained. After training the teacher, the embeddings, which are the feature map of the second last layer of the teacher, are extracted. In the second phase, the student network, which presents a low complexity model, is trained with the embeddings extracted from the teacher. Our experiments conducted on DCASE 2023 Task 1 Development dataset have fulfilled the requirement of low-complexity and achieved the best classification accuracy of 57.4%, improving DCASE baseline by 14.5%.
Deep Learning Based Multimodal with Two-phase Training Strategy for Daily Life Video Classification
Apr 30, 2023In this paper, we present a deep learning based multimodal system for classifying daily life videos. To train the system, we propose a two-phase training strategy. In the first training phase (Phase I), we extract the audio and visual (image) data from the original video. We then train the audio data and the visual data with independent deep learning based models. After the training processes, we obtain audio embeddings and visual embeddings by extracting feature maps from the pre-trained deep learning models. In the second training phase (Phase II), we train a fusion layer to combine the audio/visual embeddings and a dense layer to classify the combined embedding into target daily scenes. Our extensive experiments, which were conducted on the benchmark dataset of DCASE (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) 2021 Task 1B Development, achieved the best classification accuracy of 80.5%, 91.8%, and 95.3% with only audio data, with only visual data, both audio and visual data, respectively. The highest classification accuracy of 95.3% presents an improvement of 17.9% compared with DCASE baseline and shows very competitive to the state-of-the-art systems.
An Inception-Residual-Based Architecture with Multi-Objective Loss for Detecting Respiratory Anomalies
Mar 07, 2023
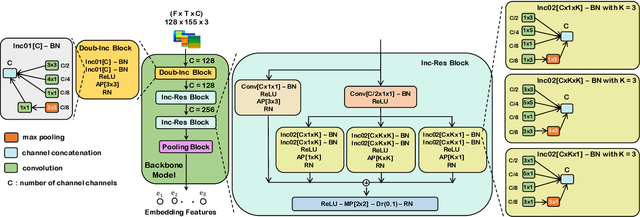
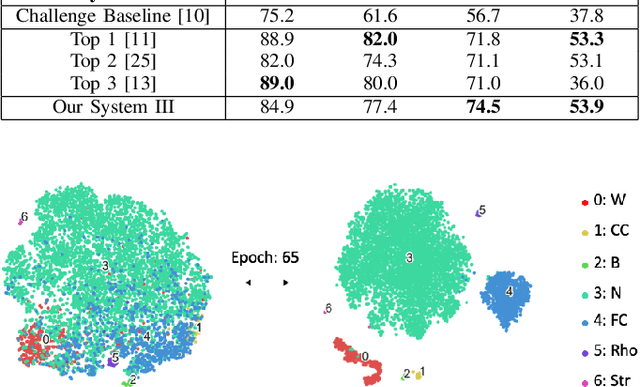

This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Initially, our system begins with audio feature extraction using Gammatone and Continuous Wavelet transformation. This step aims to transform the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed system integrates Inception-residual-based backbone models combined with multi-head attention and multi-objective loss to classify respiratory anomalies. In this work, we conducted experiments over the benchmark dataset of SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) proposed by the IEEE BioCAS 2022 challenge. As regards the Score computed by an average between the average score and harmonic score, our proposed system gained significant improvements of 9.7%, 15.8%, 17.0%, and 9.4% in Task 1-1, Task 1-2, Task 2-1, and Task 2-2 compared to the challenge baseline system. Notably, we achieved the Top-1 performance in Task 2-1 with the highest Score of 73.7%.
A Light-weight Deep Learning Model for Remote Sensing Image Classification
Feb 25, 2023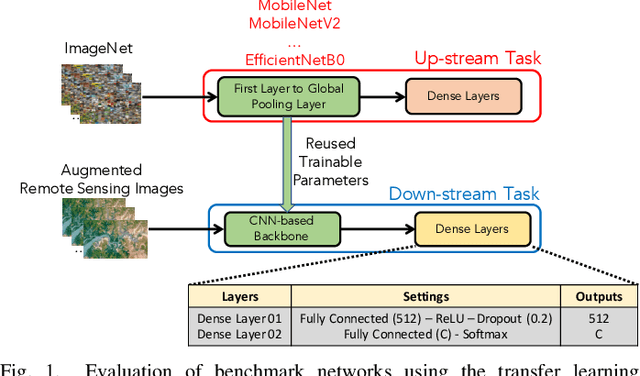
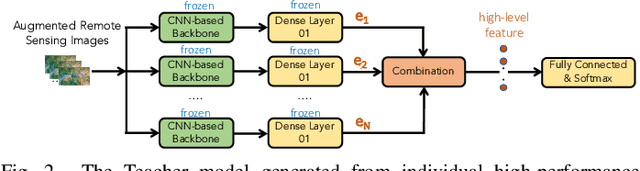
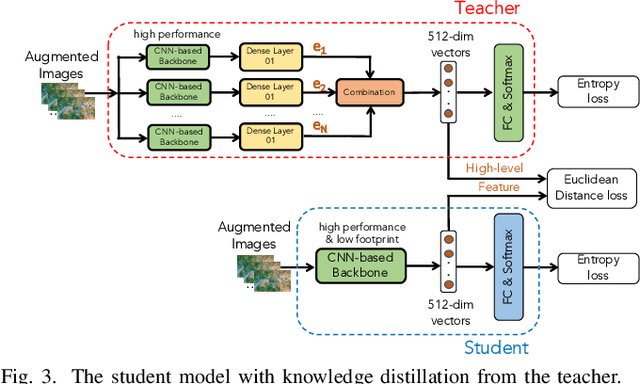

In this paper, we present a high-performance and light-weight deep learning model for Remote Sensing Image Classification (RSIC), the task of identifying the aerial scene of a remote sensing image. To this end, we first valuate various benchmark convolutional neural network (CNN) architectures: MobileNet V1/V2, ResNet 50/151V2, InceptionV3/InceptionResNetV2, EfficientNet B0/B7, DenseNet 121/201, ConNeXt Tiny/Large. Then, the best performing models are selected to train a compact model in a teacher-student arrangement. The knowledge distillation from the teacher aims to achieve high performance with significantly reduced complexity. By conducting extensive experiments on the NWPU-RESISC45 benchmark, our proposed teacher-student models outperforms the state-of-the-art systems, and has potential to be applied on a wide rage of edge devices.
Remote Sensing Image Classification using Transfer Learning and Attention Based Deep Neural Network
Jun 20, 2022
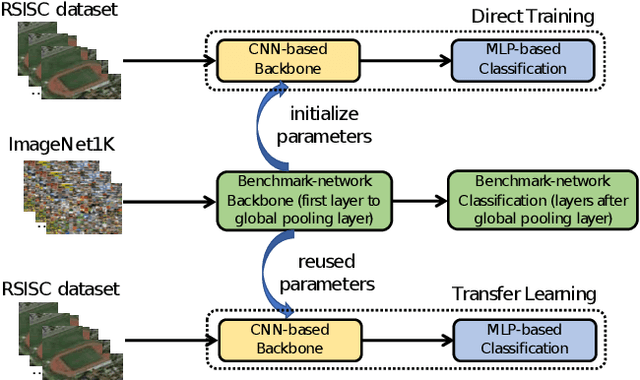
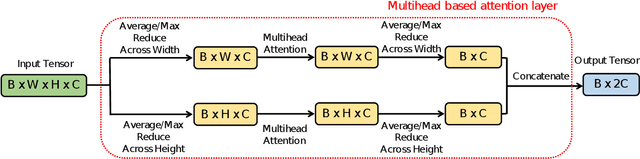

The task of remote sensing image scene classification (RSISC), which aims at classifying remote sensing images into groups of semantic categories based on their contents, has taken the important role in a wide range of applications such as urban planning, natural hazards detection, environment monitoring,vegetation mapping, or geospatial object detection. During the past years, research community focusing on RSISC task has shown significant effort to publish diverse datasets as well as propose different approaches to deal with the RSISC challenges. Recently, almost proposed RSISC systems base on deep learning models which prove powerful and outperform traditional approaches using image processing and machine learning. In this paper, we also leverage the power of deep learning technology, evaluate a variety of deep neural network architectures, indicate main factors affecting the performance of a RSISC system. Given the comprehensive analysis, we propose a deep learning based framework for RSISC, which makes use of the transfer learning technique and multihead attention scheme. The proposed deep learning framework is evaluated on the benchmark NWPU-RESISC45 dataset and achieves the best classification accuracy of 94.7% which shows competitive to the state-of-the-art systems and potential for real-life applications.
Low-complexity deep learning frameworks for acoustic scene classification
Jun 13, 2022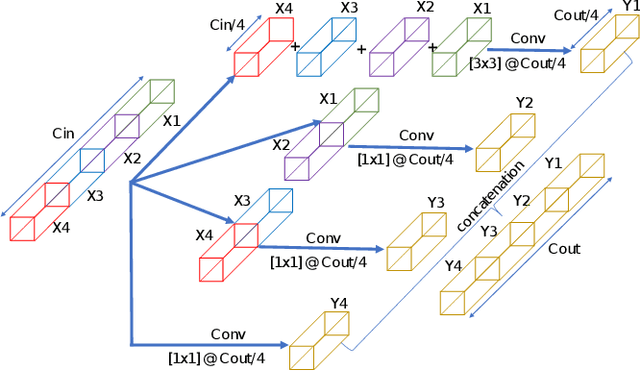
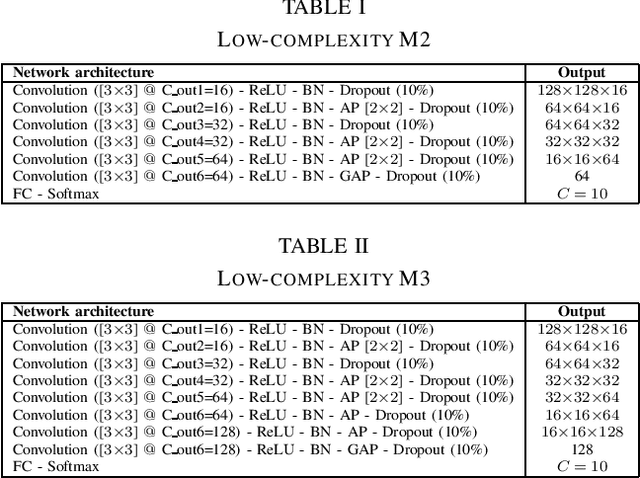
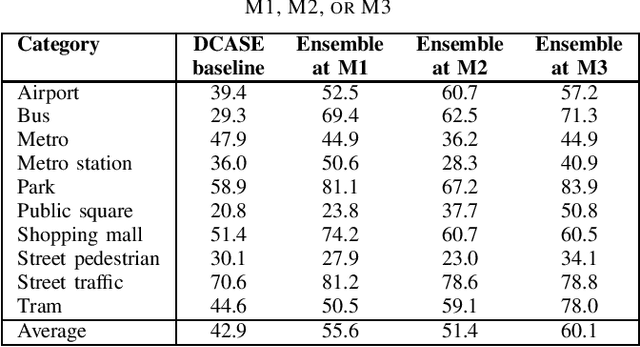
In this report, we presents low-complexity deep learning frameworks for acoustic scene classification (ASC). The proposed frameworks can be separated into four main steps: Front-end spectrogram extraction, online data augmentation, back-end classification, and late fusion of predicted probabilities. In particular, we initially transform audio recordings into Mel, Gammatone, and CQT spectrograms. Next, data augmentation methods of Random Cropping, Specaugment, and Mixup are then applied to generate augmented spectrograms before being fed into deep learning based classifiers. Finally, to achieve the best performance, we fuse probabilities which obtained from three individual classifiers, which are independently-trained with three type of spectrograms. Our experiments conducted on DCASE 2022 Task 1 Development dataset have fullfiled the requirement of low-complexity and achieved the best classification accuracy of 60.1%, improving DCASE baseline by 17.2%.
Wider or Deeper Neural Network Architecture for Acoustic Scene Classification with Mismatched Recording Devices
Mar 23, 2022
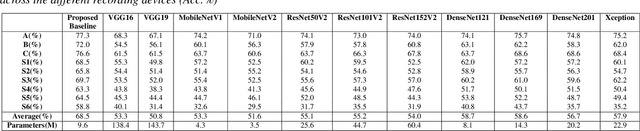
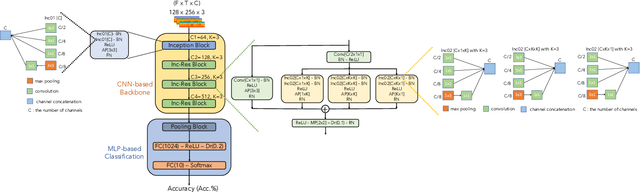
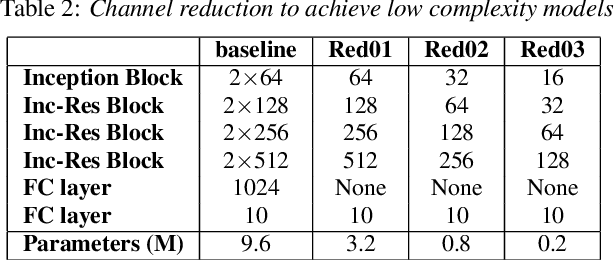
In this paper, we present a robust and low complexity system for Acoustic Scene Classification (ASC), the task of identifying the scene of an audio recording. We first construct an ASC baseline system in which a novel inception-residual-based network architecture is proposed to deal with the mismatched recording device issue. To further improve the performance but still satisfy the low complexity model, we apply two techniques: ensemble of multiple spectrograms and channel reduction on the ASC baseline system. By conducting extensive experiments on the benchmark DCASE 2020 Task 1A Development dataset, we achieve the best model performing an accuracy of 69.9% and a low complexity of 2.4M trainable parameters, which is competitive to the state-of-the-art ASC systems and potential for real-life applications on edge devices.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Mar 02, 2022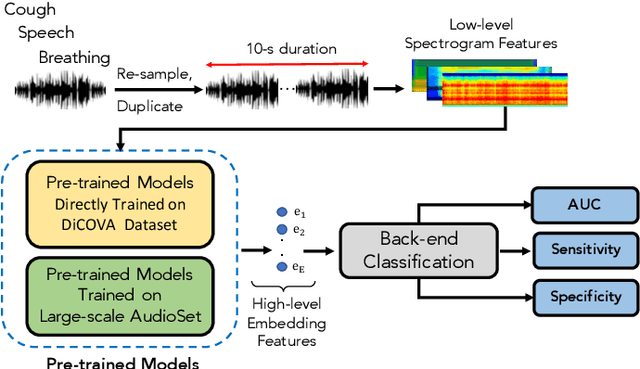

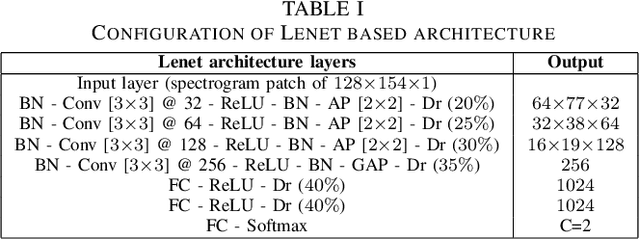
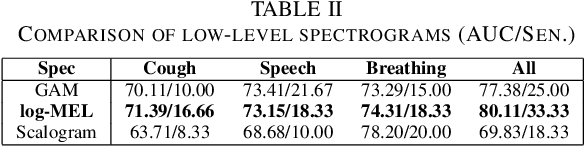
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.