 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Architecture with Spatio-Temporal Focusing for Detecting Respiratory Anomalies
Jun 25, 2023This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Our system initially performs audio feature extraction using Continuous Wavelet transformation. This transformation converts the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed deep learning architecture inspired by the Inception-residual-based backbone performs the spatial-temporal focusing and multi-head attention mechanism to classify respiratory anomalies. In this work, we evaluate our proposed models on the benchmark SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) database proposed by the IEEE BioCAS 2023 challenge. As regards the Score computed by an average between the average score and harmonic score, our robust system has achieved Top-1 performance with Scores of 0.810, 0.667, 0.744, and 0.608 in Tasks 1-1, 1-2, 2-1, and 2-2, respectively.
An Inception-Residual-Based Architecture with Multi-Objective Loss for Detecting Respiratory Anomalies
Mar 07, 2023
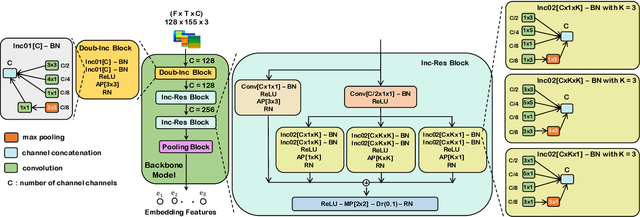

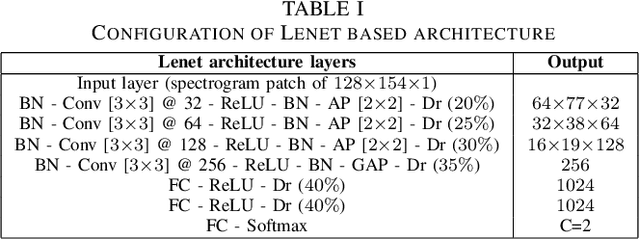
This paper presents a deep learning system applied for detecting anomalies from respiratory sound recordings. Initially, our system begins with audio feature extraction using Gammatone and Continuous Wavelet transformation. This step aims to transform the respiratory sound input into a two-dimensional spectrogram where both spectral and temporal features are presented. Then, our proposed system integrates Inception-residual-based backbone models combined with multi-head attention and multi-objective loss to classify respiratory anomalies. In this work, we conducted experiments over the benchmark dataset of SPRSound (The Open-Source SJTU Paediatric Respiratory Sound) proposed by the IEEE BioCAS 2022 challenge. As regards the Score computed by an average between the average score and harmonic score, our proposed system gained significant improvements of 9.7%, 15.8%, 17.0%, and 9.4% in Task 1-1, Task 1-2, Task 2-1, and Task 2-2 compared to the challenge baseline system. Notably, we achieved the Top-1 performance in Task 2-1 with the highest Score of 73.7%.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Mar 02, 2022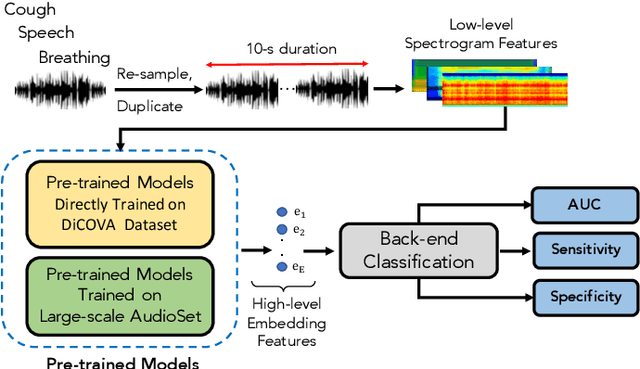

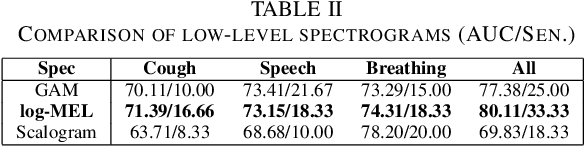
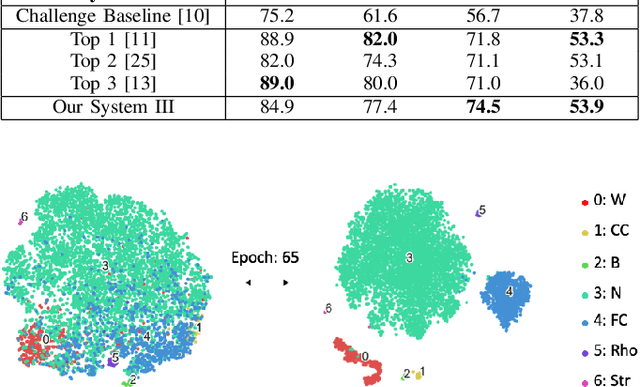
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
Recognition of Patient Groups with Sleep Related Disorders using Bio-signal Processing and Deep Learning
Nov 10, 2021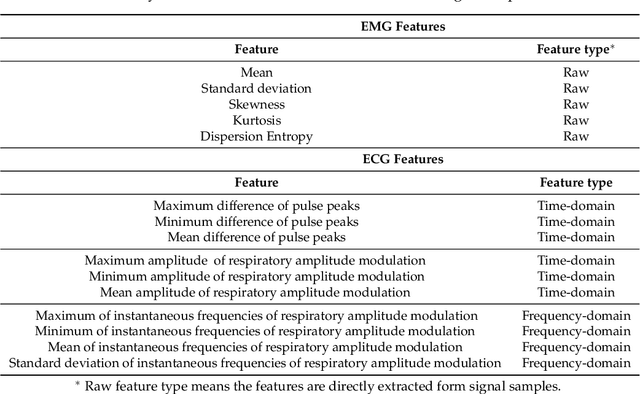
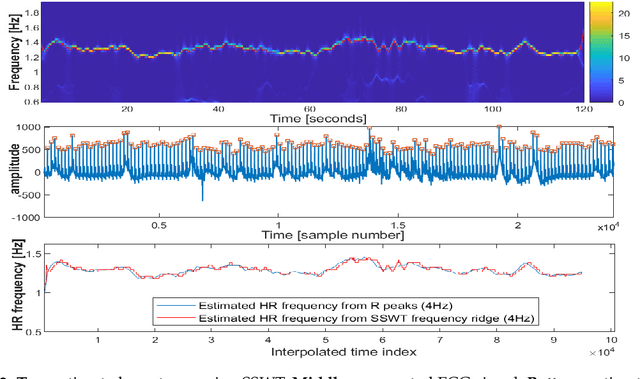
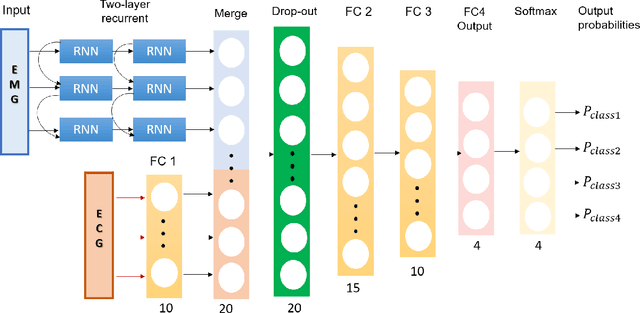
Accurately diagnosing sleep disorders is essential for clinical assessments and treatments. Polysomnography (PSG) has long been used for detection of various sleep disorders. In this research, electrocardiography (ECG) and electromayography (EMG) have been used for recognition of breathing and movement-related sleep disorders. Bio-signal processing has been performed by extracting EMG features exploiting entropy and statistical moments, in addition to developing an iterative pulse peak detection algorithm using synchrosqueezed wavelet transform (SSWT) for reliable extraction of heart rate and breathing-related features from ECG. A deep learning framework has been designed to incorporate EMG and ECG features. The framework has been used to classify four groups: healthy subjects, patients with obstructive sleep apnea (OSA), patients with restless leg syndrome (RLS) and patients with both OSA and RLS. The proposed deep learning framework produced a mean accuracy of 72% and weighted F1 score of 0.57 across subjects for our formulated four-class problem.
* Paper is offered by the publisher as Open Acess: https://www.mdpi.com/1424-8220/20/9/2594
A Generic Deep Learning Based Cough Analysis System from Clinically Validated Samples for Point-of-Need Covid-19 Test and Severity Levels
Nov 10, 2021
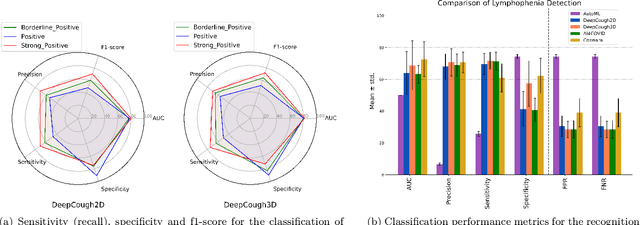
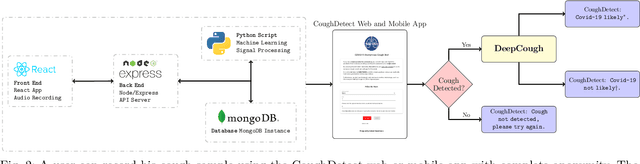
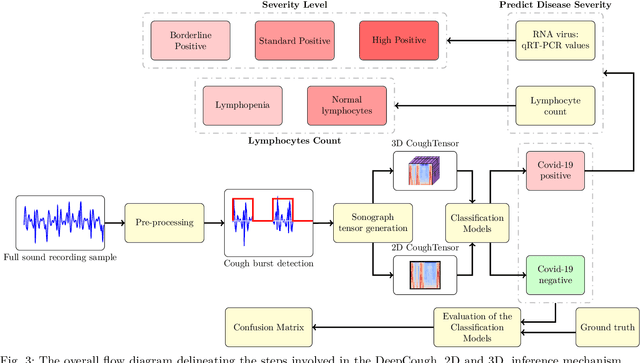
We seek to evaluate the detection performance of a rapid primary screening tool of Covid-19 solely based on the cough sound from 8,380 clinically validated samples with laboratory molecular-test (2,339 Covid-19 positives and 6,041 Covid-19 negatives). Samples were clinically labeled according to the results and severity based on quantitative RT-PCR (qRT-PCR) analysis, cycle threshold, and lymphocytes count from the patients. Our proposed generic method is an algorithm based on Empirical Mode Decomposition (EMD) with subsequent classification based on a tensor of audio features and a deep artificial neural network classifier with convolutional layers called DeepCough'. Two different versions of DeepCough based on the number of tensor dimensions, i.e. DeepCough2D and DeepCough3D, have been investigated. These methods have been deployed in a multi-platform proof-of-concept Web App CoughDetect to administer this test anonymously. Covid-19 recognition results rates achieved a promising AUC (Area Under Curve) of 98.800.83%, sensitivity of 96.431.85%, and specificity of 96.201.74%, and 81.08%5.05% AUC for the recognition of three severity levels. Our proposed web tool and underpinning algorithm for the robust, fast, point-of-need identification of Covid-19 facilitates the rapid detection of the infection. We believe that it has the potential to significantly hamper the Covid-19 pandemic across the world.