 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024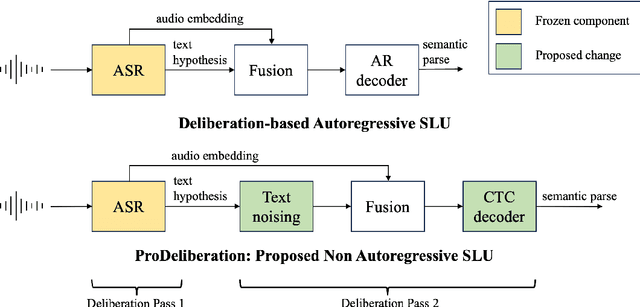
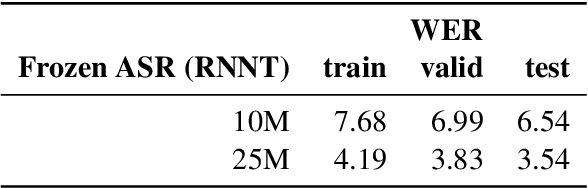
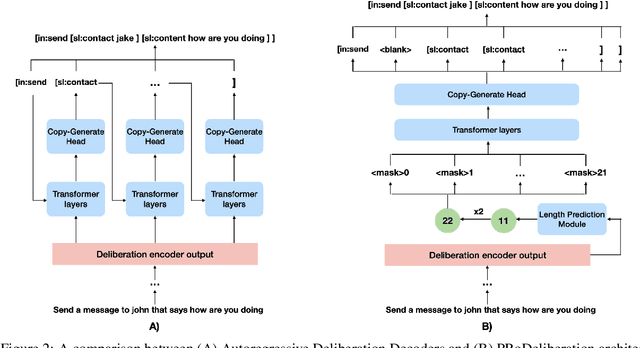

Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
Jun 05, 2024On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($\epsilon=1.29$, $\epsilon=7.58$). We achieve these results while using 9$\times$ fewer rounds, 6$\times$ less client computation per round, and 100$\times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.
Augmenting text for spoken language understanding with Large Language Models
Sep 17, 2023



Spoken semantic parsing (SSP) involves generating machine-comprehensible parses from input speech. Training robust models for existing application domains represented in training data or extending to new domains requires corresponding triplets of speech-transcript-semantic parse data, which is expensive to obtain. In this paper, we address this challenge by examining methods that can use transcript-semantic parse data (unpaired text) without corresponding speech. First, when unpaired text is drawn from existing textual corpora, Joint Audio Text (JAT) and Text-to-Speech (TTS) are compared as ways to generate speech representations for unpaired text. Experiments on the STOP dataset show that unpaired text from existing and new domains improves performance by 2% and 30% in absolute Exact Match (EM) respectively. Second, we consider the setting when unpaired text is not available in existing textual corpora. We propose to prompt Large Language Models (LLMs) to generate unpaired text for existing and new domains. Experiments show that examples and words that co-occur with intents can be used to generate unpaired text with Llama 2.0. Using the generated text with JAT and TTS for spoken semantic parsing improves EM on STOP by 1.4% and 2.6% absolute for existing and new domains respectively.
Deep Learning Based Multimodal with Two-phase Training Strategy for Daily Life Video Classification
Apr 30, 2023In this paper, we present a deep learning based multimodal system for classifying daily life videos. To train the system, we propose a two-phase training strategy. In the first training phase (Phase I), we extract the audio and visual (image) data from the original video. We then train the audio data and the visual data with independent deep learning based models. After the training processes, we obtain audio embeddings and visual embeddings by extracting feature maps from the pre-trained deep learning models. In the second training phase (Phase II), we train a fusion layer to combine the audio/visual embeddings and a dense layer to classify the combined embedding into target daily scenes. Our extensive experiments, which were conducted on the benchmark dataset of DCASE (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) 2021 Task 1B Development, achieved the best classification accuracy of 80.5%, 91.8%, and 95.3% with only audio data, with only visual data, both audio and visual data, respectively. The highest classification accuracy of 95.3% presents an improvement of 17.9% compared with DCASE baseline and shows very competitive to the state-of-the-art systems.
Roadmap on Deep Learning for Microscopy
Mar 07, 2023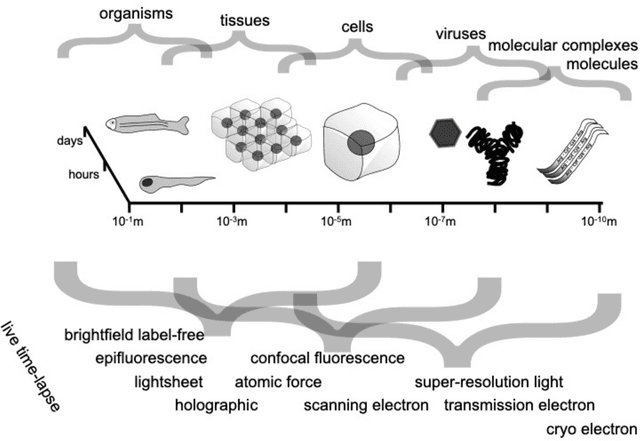
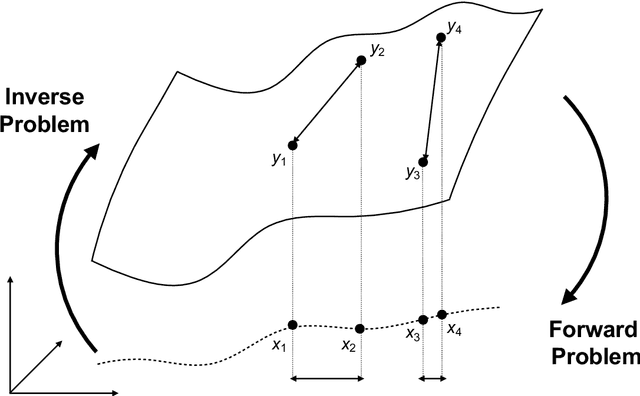
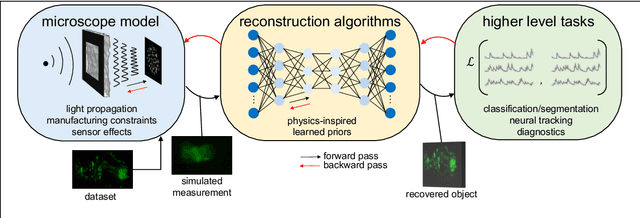
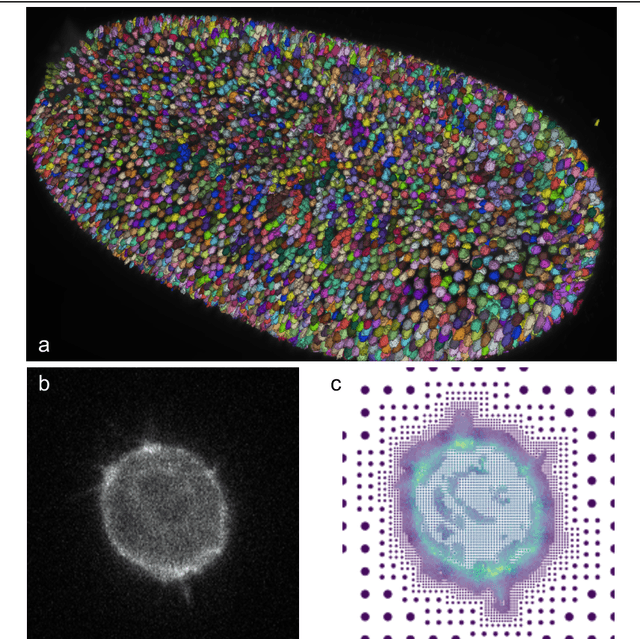
Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.
Federated Artificial Intelligence for Unified Credit Assessment
May 20, 2021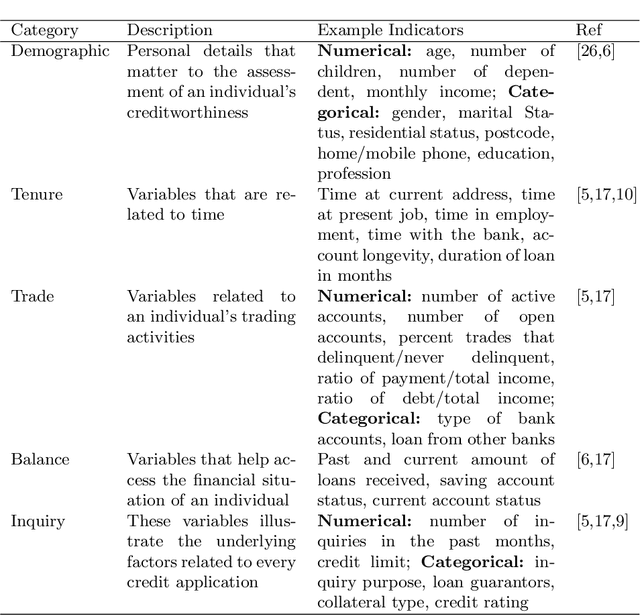
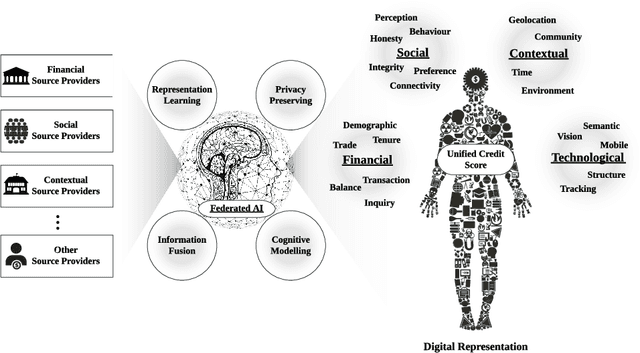
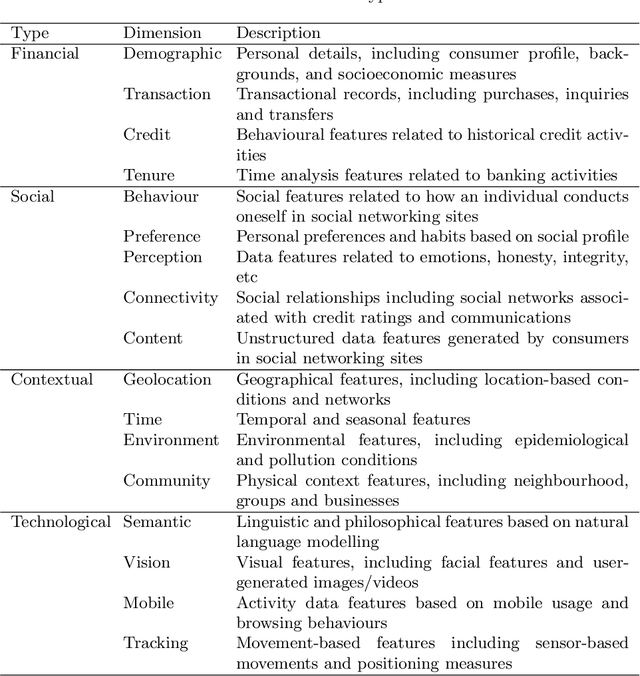
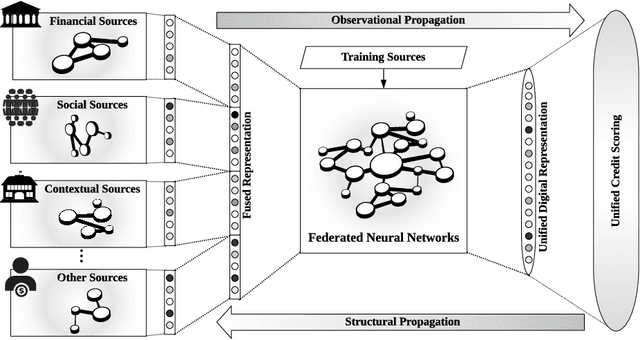
With the rapid adoption of Internet technologies, digital footprints have become ubiquitous and versatile to revolutionise the financial industry in digital transformation. This paper takes initiatives to investigate a new paradigm of the unified credit assessment with the use of federated artificial intelligence. We conceptualised digital human representation which consists of social, contextual, financial and technological dimensions to assess the commercial creditworthiness and social reputation of both banked and unbanked individuals. A federated artificial intelligence platform is proposed with a comprehensive set of system design for efficient and effective credit scoring. The study considerably contributes to the cumulative development of financial intelligence and social computing. It also provides a number of implications for academic bodies, practitioners, and developers of financial technologies.