 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024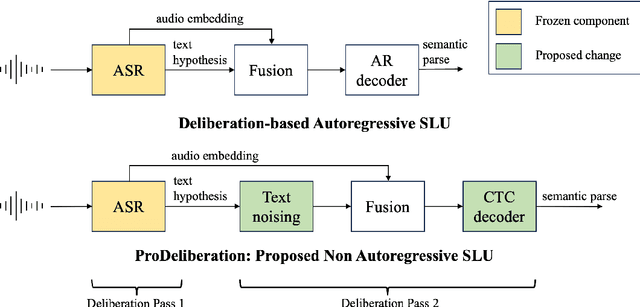
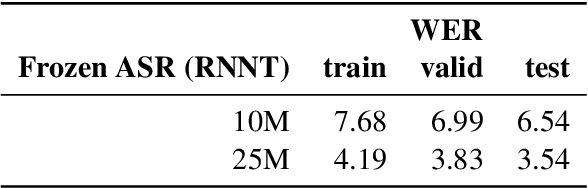
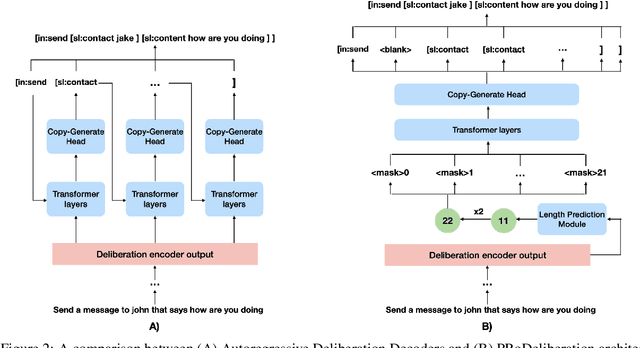

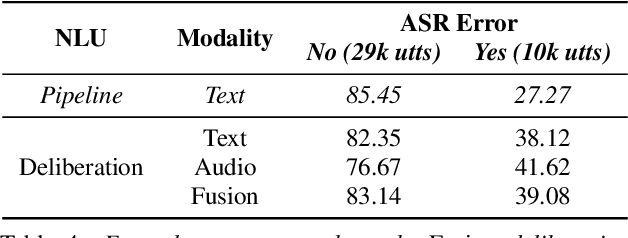
Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023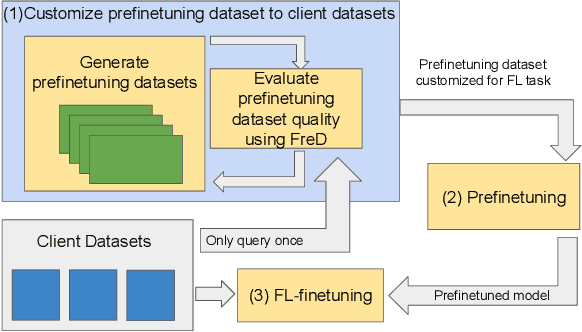

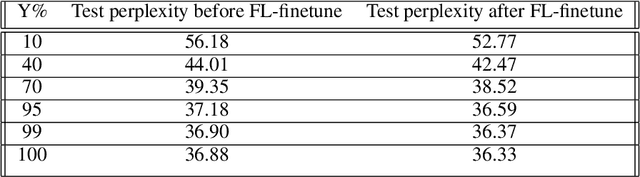
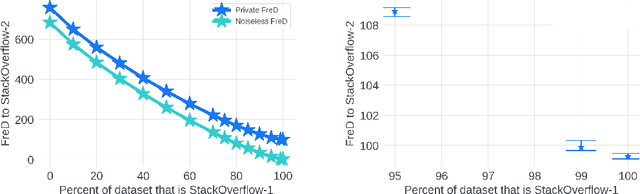
In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
Deliberation Model for On-Device Spoken Language Understanding
Apr 04, 2022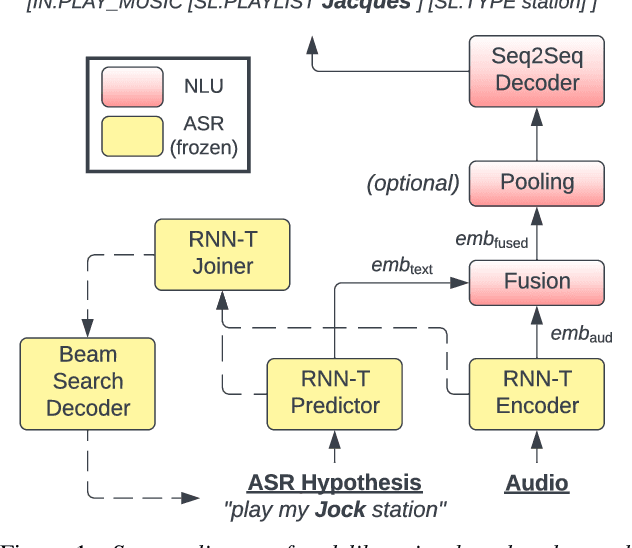

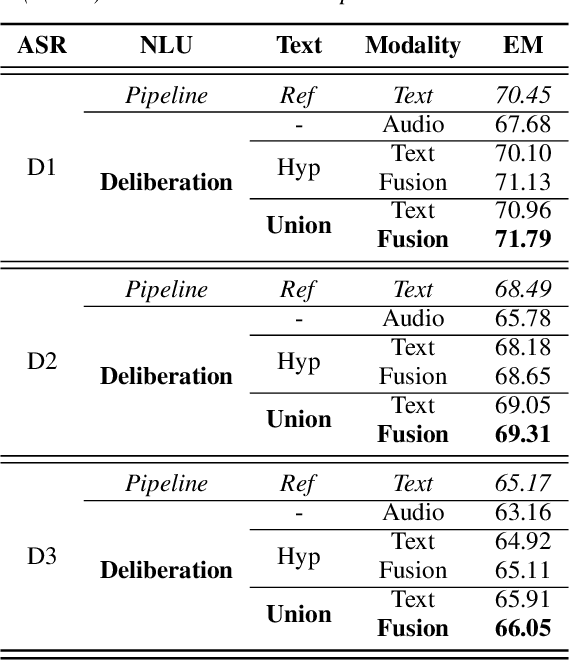
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.
Retrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022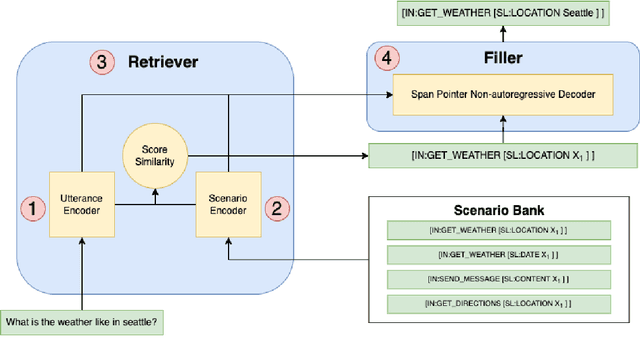
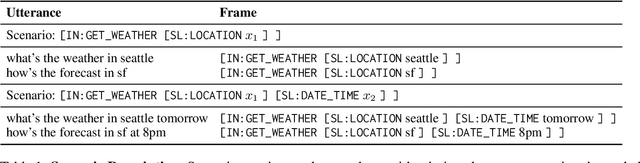


Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.
An Universal Image Attractiveness Ranking Framework
Sep 19, 2018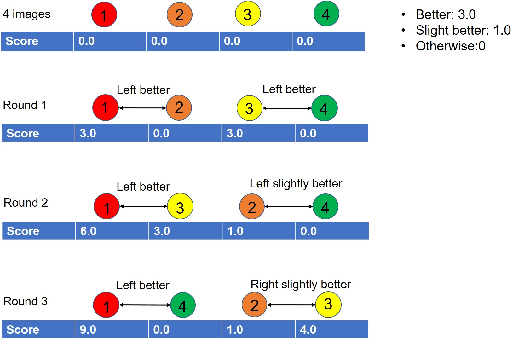

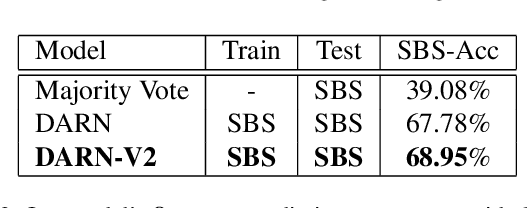
We propose a new framework to rank image attractiveness using a novel pairwise deep network trained with a large set of side-by-side multi-labeled image pairs from a web image index. The judges only provide relative ranking between two images without the need to directly assign an absolute score, or rate any predefined image attribute, thus making the rating more intuitive and straightforward. We investigate a deep attractiveness rank net (DARN), a combination of deep convolutional neural network and rank net, to directly learn an attractiveness score mean and variance for each image and the underlying criteria the judges use to label each pair. The extension of this model (DARN-V2) is able to adapt to individual judge's personal preference. We also show the attractiveness of search results are significantly improved by using this attractiveness information in a real commercial search engine. We evaluate our model against other state-of-the-art models on our side-by-side web test data and another public aesthetic data set. Our model outperforms on side-by-side labeled data, and is competitive on data labeled by absolute score.