 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberation Model for On-Device Spoken Language Understanding
Paper and Code
Apr 04, 2022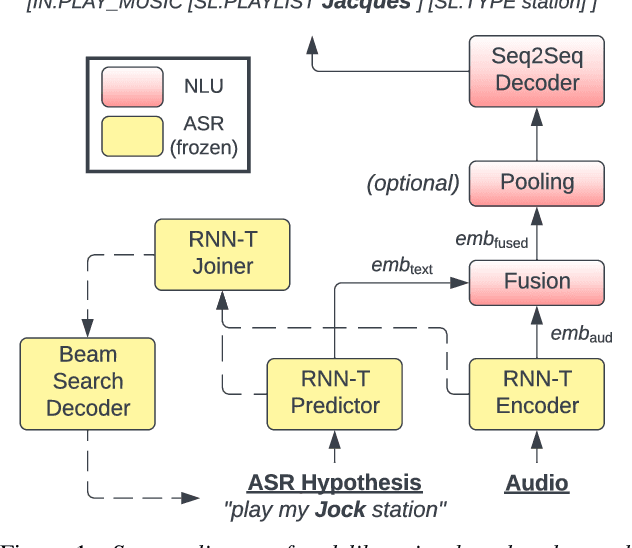

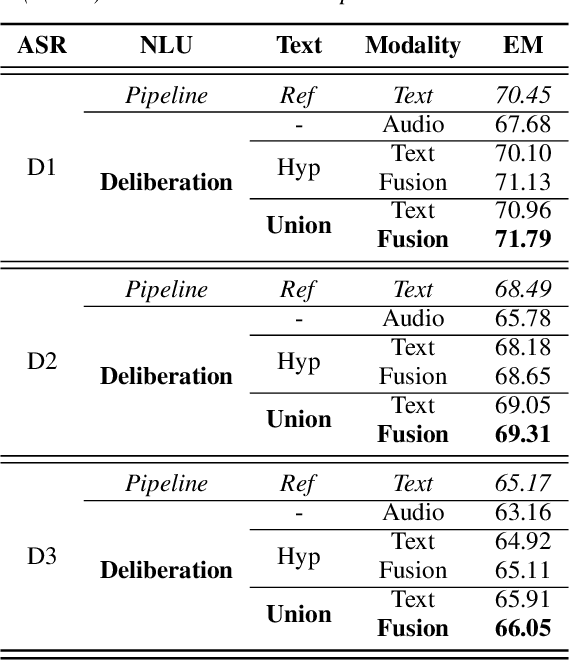
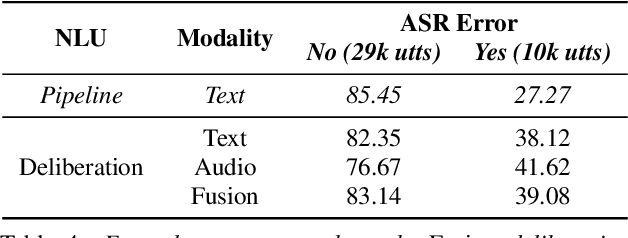
We propose a novel deliberation-based approach to end-to-end (E2E) spoken language understanding (SLU), where a streaming automatic speech recognition (ASR) model produces the first-pass hypothesis and a second-pass natural language understanding (NLU) component generates the semantic parse by conditioning on both ASR's text and audio embeddings. By formulating E2E SLU as a generalized decoder, our system is able to support complex compositional semantic structures. Furthermore, the sharing of parameters between ASR and NLU makes the system especially suitable for resource-constrained (on-device) environments; our proposed approach consistently outperforms strong pipeline NLU baselines by 0.82% to 1.34% across various operating points on the spoken version of the TOPv2 dataset. We demonstrate that the fusion of text and audio features, coupled with the system's ability to rewrite the first-pass hypothesis, makes our approach more robust to ASR errors. Finally, we show that our approach can significantly reduce the degradation when moving from natural speech to synthetic speech training, but more work is required to make text-to-speech (TTS) a viable solution for scaling up E2E SLU.