 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
Mar 12, 2026Reasoning LLMs-as-Judges, which can benefit from inference-time scaling, provide a promising path for extending the success of reasoning models to non-verifiable domains where the output correctness/quality cannot be directly checked. However, while reasoning judges have shown better performance on static evaluation benchmarks, their effectiveness in actual policy training has not been systematically examined. Therefore, we conduct a rigorous study to investigate the actual impact of non-reasoning and reasoning judges in reinforcement-learning-based LLM alignment. Our controlled synthetic setting, where a "gold-standard" judge (gpt-oss-120b) provides preference annotations to train smaller judges, reveals key differences between non-reasoning and reasoning judges: non-reasoning judges lead to reward hacking easily, while reasoning judges can lead to policies that achieve strong performance when evaluated by the gold-standard judge. Interestingly, we find that the reasoning-judge-trained policies achieve such strong performance by learning to generate highly effective adversarial outputs that can also score well on popular benchmarks such as Arena-Hard by deceiving other LLM-judges. Combined with our further analysis, our study highlights both important findings and room for improvements for applying (reasoning) LLM-judges in non-verifiable LLM post-training.
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Oct 10, 2025Diffusion large language models (dLLMs) are emerging as an efficient alternative to autoregressive models due to their ability to decode multiple tokens in parallel. However, aligning dLLMs with human preferences or task-specific rewards via reinforcement learning (RL) is challenging because their intractable log-likelihood precludes the direct application of standard policy gradient methods. While prior work uses surrogates like the evidence lower bound (ELBO), these one-sided approximations can introduce significant policy gradient bias. To address this, we propose the Sandwiched Policy Gradient (SPG) that leverages both an upper and a lower bound of the true log-likelihood. Experiments show that SPG significantly outperforms baselines based on ELBO or one-step estimation. Specifically, SPG improves the accuracy over state-of-the-art RL methods for dLLMs by 3.6% in GSM8K, 2.6% in MATH500, 18.4% in Countdown and 27.0% in Sudoku.
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Trainin
May 29, 2025Reinforcement Learning (RL) has become the most effective post-training approach for improving the capabilities of Large Language Models (LLMs). In practice, because of the high demands on latency and memory, it is particularly challenging to develop an efficient RL framework that reliably manages policy models with hundreds to thousands of billions of parameters. In this paper, we present LlamaRL, a fully distributed, asynchronous RL framework optimized for efficient training of large-scale LLMs with various model sizes (8B, 70B, and 405B parameters) on GPU clusters ranging from a handful to thousands of devices. LlamaRL introduces a streamlined, single-controller architecture built entirely on native PyTorch, enabling modularity, ease of use, and seamless scalability to thousands of GPUs. We also provide a theoretical analysis of LlamaRL's efficiency, including a formal proof that its asynchronous design leads to strict RL speed-up. Empirically, by leveraging best practices such as colocated model offloading, asynchronous off-policy training, and distributed direct memory access for weight synchronization, LlamaRL achieves significant efficiency gains -- up to 10.7x speed-up compared to DeepSpeed-Chat-like systems on a 405B-parameter policy model. Furthermore, the efficiency advantage continues to grow with increasing model scale, demonstrating the framework's suitability for future large-scale RL training.
Learning to chain-of-thought with Jensen's evidence lower bound
Mar 25, 2025



We propose a way to optimize chain-of-thought with reinforcement learning, but without external reward function. Our algorithm relies on viewing chain-of-thought as latent variable as part of a probabilistic inference problem. Contrary to the full evidence lower bound, we propose to apply a much simpler Jensen's lower bound, which derives tractable objectives with simple algorithmic components (e.g., without the need for parametric approximate posterior), making it more conducive to modern large-scale training. The lower bound approach naturally interpolates other methods such as supervised fine-tuning and online reinforcement learning, whose practical trade-offs we will illustrate. Finally, we show that on mathematical reasoning problems, optimizing with Jensen's lower bound is as effective as policy gradient with external reward. Taken together, our results showcase as a proof of concept to this new algorithmic paradigm's potential to more generic applications.
READ: Recurrent Adaptation of Large Transformers
May 24, 2023Fine-tuning large-scale Transformers has led to the explosion of many AI applications across Natural Language Processing and Computer Vision tasks. However, fine-tuning all pre-trained model parameters becomes impractical as the model size and number of tasks increase. Parameter-efficient transfer learning (PETL) methods aim to address these challenges. While effective in reducing the number of trainable parameters, PETL methods still require significant energy and computational resources to fine-tune. In this paper, we introduce \textbf{RE}current \textbf{AD}aption (READ) -- a lightweight and memory-efficient fine-tuning method -- to overcome the limitations of the current PETL approaches. Specifically, READ inserts a small RNN network alongside the backbone model so that the model does not have to back-propagate through the large backbone network. Through comprehensive empirical evaluation of the GLUE benchmark, we demonstrate READ can achieve a $56\%$ reduction in the training memory consumption and an $84\%$ reduction in the GPU energy usage while retraining high model quality compared to full-tuning. Additionally, the model size of READ does not grow with the backbone model size, making it a highly scalable solution for fine-tuning large Transformers.
Now It Sounds Like You: Learning Personalized Vocabulary On Device
May 05, 2023

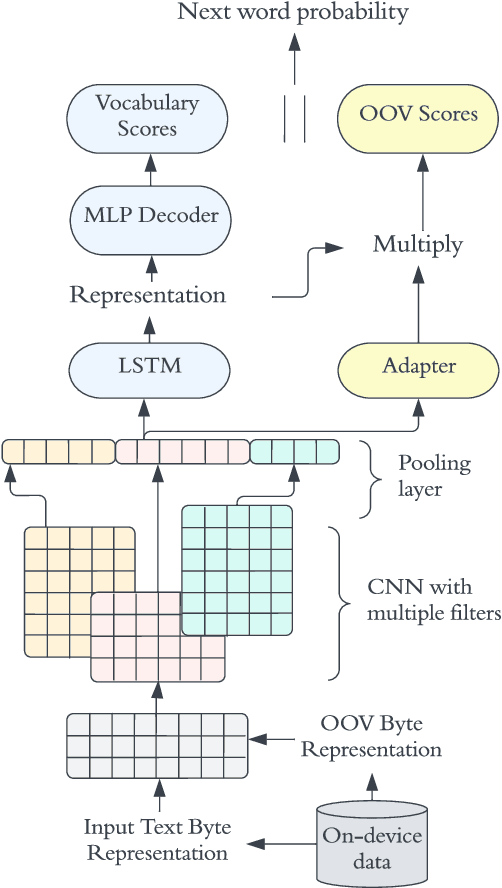

In recent years, Federated Learning (FL) has shown significant advancements in its ability to perform various natural language processing (NLP) tasks. This work focuses on applying personalized FL for on-device language modeling. Due to limitations of memory and latency, these models cannot support the complexity of sub-word tokenization or beam search decoding, resulting in the decision to deploy a closed-vocabulary language model. However, closed-vocabulary models are unable to handle out-of-vocabulary (OOV) words belonging to specific users. To address this issue, We propose a novel technique called "OOV expansion" that improves OOV coverage and increases model accuracy while minimizing the impact on memory and latency. This method introduces a personalized "OOV adapter" that effectively transfers knowledge from a central model and learns word embedding for personalized vocabulary. OOV expansion significantly outperforms standard FL personalization methods on a set of common FL benchmarks.
TreePiece: Faster Semantic Parsing via Tree Tokenization
Mar 30, 2023



Autoregressive (AR) encoder-decoder neural networks have proved successful in many NLP problems, including Semantic Parsing -- a task that translates natural language to machine-readable parse trees. However, the sequential prediction process of AR models can be slow. To accelerate AR for semantic parsing, we introduce a new technique called TreePiece that tokenizes a parse tree into subtrees and generates one subtree per decoding step. On TopV2 benchmark, TreePiece shows 4.6 times faster decoding speed than standard AR, and comparable speed but significantly higher accuracy compared to Non-Autoregressive (NAR).
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023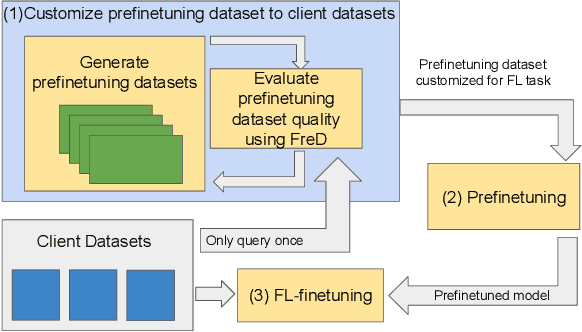

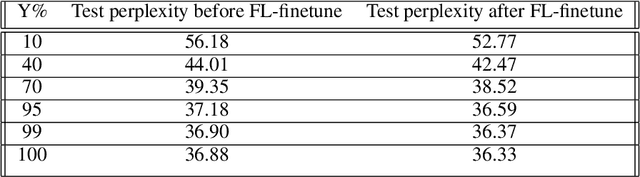
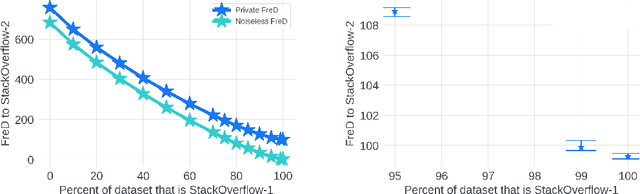
In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.