 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Federated Learning using Preference-Optimized Synthetic Data
Apr 23, 2025



In practical settings, differentially private Federated learning (DP-FL) is the dominant method for training models from private, on-device client data. Recent work has suggested that DP-FL may be enhanced or outperformed by methods that use DP synthetic data (Wu et al., 2024; Hou et al., 2024). The primary algorithms for generating DP synthetic data for FL applications require careful prompt engineering based on public information and/or iterative private client feedback. Our key insight is that the private client feedback collected by prior DP synthetic data methods (Hou et al., 2024; Xie et al., 2024) can be viewed as a preference ranking. Our algorithm, Preference Optimization for Private Client Data (POPri) harnesses client feedback using preference optimization algorithms such as Direct Preference Optimization (DPO) to fine-tune LLMs to generate high-quality DP synthetic data. To evaluate POPri, we release LargeFedBench, a new federated text benchmark for uncontaminated LLM evaluations on federated client data. POPri substantially improves the utility of DP synthetic data relative to prior work on LargeFedBench datasets and an existing benchmark from Xie et al. (2024). POPri closes the gap between next-token prediction accuracy in the fully-private and non-private settings by up to 68%, compared to 52% for prior synthetic data methods, and 10% for state-of-the-art DP federated learning methods. The code and data are available at https://github.com/meiyuw/POPri.
PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
Jun 05, 2024On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($\epsilon=1.29$, $\epsilon=7.58$). We achieve these results while using 9$\times$ fewer rounds, 6$\times$ less client computation per round, and 100$\times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.
On the Convergence of Differentially-Private Fine-tuning: To Linearly Probe or to Fully Fine-tune?
Feb 29, 2024


Differentially private (DP) machine learning pipelines typically involve a two-phase process: non-private pre-training on a public dataset, followed by fine-tuning on private data using DP optimization techniques. In the DP setting, it has been observed that full fine-tuning may not always yield the best test accuracy, even for in-distribution data. This paper (1) analyzes the training dynamics of DP linear probing (LP) and full fine-tuning (FT), and (2) explores the phenomenon of sequential fine-tuning, starting with linear probing and transitioning to full fine-tuning (LP-FT), and its impact on test loss. We provide theoretical insights into the convergence of DP fine-tuning within an overparameterized neural network and establish a utility curve that determines the allocation of privacy budget between linear probing and full fine-tuning. The theoretical results are supported by empirical evaluations on various benchmarks and models. The findings reveal the complex nature of DP fine-tuning methods. These results contribute to a deeper understanding of DP machine learning and highlight the importance of considering the allocation of privacy budget in the fine-tuning process.
Pretrained deep models outperform GBDTs in Learning-To-Rank under label scarcity
Jul 31, 2023



While deep learning (DL) models are state-of-the-art in text and image domains, they have not yet consistently outperformed Gradient Boosted Decision Trees (GBDTs) on tabular Learning-To-Rank (LTR) problems. Most of the recent performance gains attained by DL models in text and image tasks have used unsupervised pretraining, which exploits orders of magnitude more unlabeled data than labeled data. To the best of our knowledge, unsupervised pretraining has not been applied to the LTR problem, which often produces vast amounts of unlabeled data. In this work, we study whether unsupervised pretraining can improve LTR performance over GBDTs and other non-pretrained models. Using simple design choices--including SimCLR-Rank, our ranking-specific modification of SimCLR (an unsupervised pretraining method for images)--we produce pretrained deep learning models that soundly outperform GBDTs (and other non-pretrained models) in the case where labeled data is vastly outnumbered by unlabeled data. We also show that pretrained models also often achieve significantly better robustness than non-pretrained models (GBDTs or DL models) in ranking outlier data.
Privately Customizing Prefinetuning to Better Match User Data in Federated Learning
Feb 23, 2023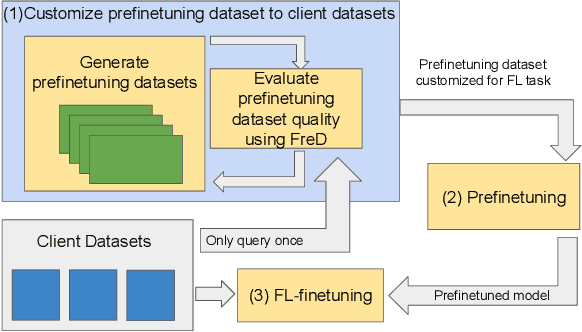

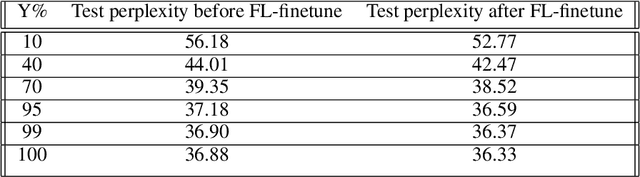
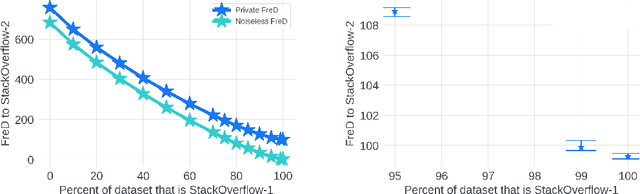
In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
Reducing the Communication Cost of Federated Learning through Multistage Optimization
Aug 16, 2021
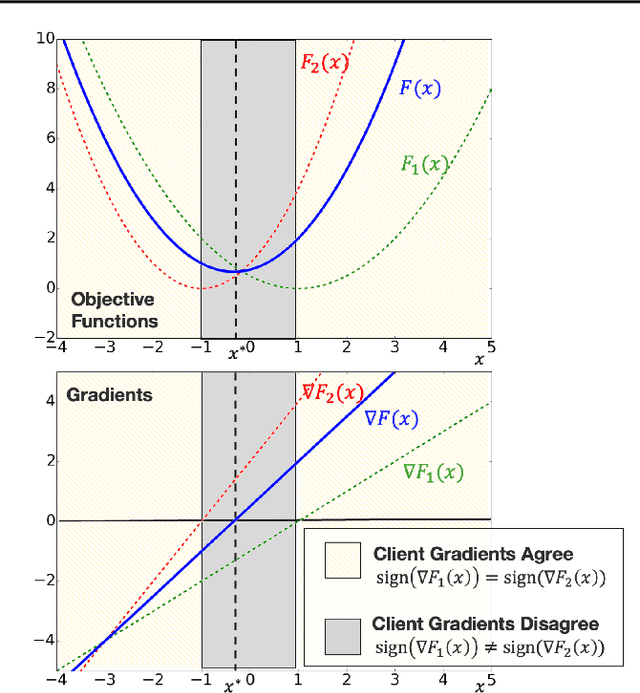

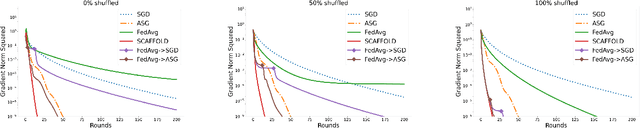
A central question in federated learning (FL) is how to design optimization algorithms that minimize the communication cost of training a model over heterogeneous data distributed across many clients. A popular technique for reducing communication is the use of local steps, where clients take multiple optimization steps over local data before communicating with the server (e.g., FedAvg, SCAFFOLD). This contrasts with centralized methods, where clients take one optimization step per communication round (e.g., Minibatch SGD). A recent lower bound on the communication complexity of first-order methods shows that centralized methods are optimal over highly-heterogeneous data, whereas local methods are optimal over purely homogeneous data [Woodworth et al., 2020]. For intermediate heterogeneity levels, no algorithm is known to match the lower bound. In this paper, we propose a multistage optimization scheme that nearly matches the lower bound across all heterogeneity levels. The idea is to first run a local method up to a heterogeneity-induced error floor; next, we switch to a centralized method for the remaining steps. Our analysis may help explain empirically-successful stepsize decay methods in FL [Charles et al., 2020; Reddi et al., 2020]. We demonstrate the scheme's practical utility in image classification tasks.
Efficient Algorithms for Federated Saddle Point Optimization
Feb 12, 2021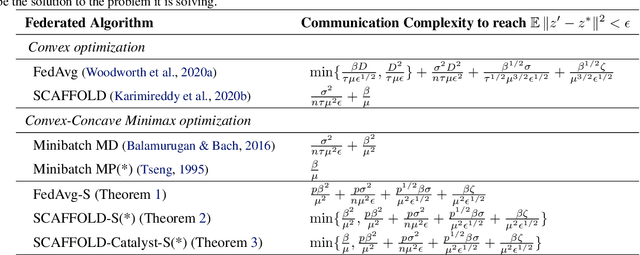


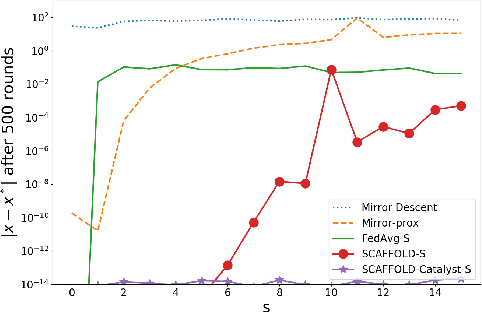
We consider strongly convex-concave minimax problems in the federated setting, where the communication constraint is the main bottleneck. When clients are arbitrarily heterogeneous, a simple Minibatch Mirror-prox achieves the best performance. As the clients become more homogeneous, using multiple local gradient updates at the clients significantly improves upon Minibatch Mirror-prox by communicating less frequently. Our goal is to design an algorithm that can harness the benefit of similarity in the clients while recovering the Minibatch Mirror-prox performance under arbitrary heterogeneity (up to log factors). We give the first federated minimax optimization algorithm that achieves this goal. The main idea is to combine (i) SCAFFOLD (an algorithm that performs variance reduction across clients for convex optimization) to erase the worst-case dependency on heterogeneity and (ii) Catalyst (a framework for acceleration based on modifying the objective) to accelerate convergence without amplifying client drift. We prove that this algorithm achieves our goal, and include experiments to validate the theory.