 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Dense Reward for Long-Horizon Robotic Tasks
Mar 31, 2026Existing robotic foundation policies are trained primarily via large-scale imitation learning. While such models demonstrate strong capabilities, they often struggle with long-horizon tasks due to distribution shift and error accumulation. While reinforcement learning (RL) can finetune these models, it cannot work well across diverse tasks without manual reward engineering. We propose VLLR, a dense reward framework combining (1) an extrinsic reward from Large Language Models (LLMs) and Vision-Language Models (VLMs) for task progress recognition, and (2) an intrinsic reward based on policy self-certainty. VLLR uses LLMs to decompose tasks into verifiable subtasks and then VLMs to estimate progress to initialize the value function for a brief warm-up phase, avoiding prohibitive inference cost during full training; and self-certainty provides per-step intrinsic guidance throughout PPO finetuning. Ablation studies reveal complementary benefits: VLM-based value initialization primarily improves task completion efficiency, while self-certainty primarily enhances success rates, particularly on out-of-distribution tasks. On the CHORES benchmark covering mobile manipulation and navigation, VLLR achieves up to 56% absolute success rate gains over the pretrained policy, up to 5% gains over state-of-the-art RL finetuning methods on in-distribution tasks, and up to $10\%$ gains on out-of-distribution tasks, all without manual reward engineering. Additional visualizations can be found in https://silongyong.github.io/vllr_project_page/
Self-Refining Vision Language Model for Robotic Failure Detection and Reasoning
Feb 12, 2026Reasoning about failures is crucial for building reliable and trustworthy robotic systems. Prior approaches either treat failure reasoning as a closed-set classification problem or assume access to ample human annotations. Failures in the real world are typically subtle, combinatorial, and difficult to enumerate, whereas rich reasoning labels are expensive to acquire. We address this problem by introducing ARMOR: Adaptive Round-based Multi-task mOdel for Robotic failure detection and reasoning. We formulate detection and reasoning as a multi-task self-refinement process, where the model iteratively predicts detection outcomes and natural language reasoning conditioned on past outputs. During training, ARMOR learns from heterogeneous supervision - large-scale sparse binary labels and small-scale rich reasoning annotations - optimized via a combination of offline and online imitation learning. At inference time, ARMOR generates multiple refinement trajectories and selects the most confident prediction via a self-certainty metric. Experiments across diverse environments show that ARMOR achieves state-of-the-art performance by improving over the previous approaches by up to 30% on failure detection rate and up to 100% in reasoning measured through LLM fuzzy match score, demonstrating robustness to heterogeneous supervision and open-ended reasoning beyond predefined failure modes. We provide dditional visualizations on our website: https://sites.google.com/utexas.edu/armor
Pretrained deep models outperform GBDTs in Learning-To-Rank under label scarcity
Jul 31, 2023



While deep learning (DL) models are state-of-the-art in text and image domains, they have not yet consistently outperformed Gradient Boosted Decision Trees (GBDTs) on tabular Learning-To-Rank (LTR) problems. Most of the recent performance gains attained by DL models in text and image tasks have used unsupervised pretraining, which exploits orders of magnitude more unlabeled data than labeled data. To the best of our knowledge, unsupervised pretraining has not been applied to the LTR problem, which often produces vast amounts of unlabeled data. In this work, we study whether unsupervised pretraining can improve LTR performance over GBDTs and other non-pretrained models. Using simple design choices--including SimCLR-Rank, our ranking-specific modification of SimCLR (an unsupervised pretraining method for images)--we produce pretrained deep learning models that soundly outperform GBDTs (and other non-pretrained models) in the case where labeled data is vastly outnumbered by unlabeled data. We also show that pretrained models also often achieve significantly better robustness than non-pretrained models (GBDTs or DL models) in ranking outlier data.
On the Value of Behavioral Representations for Dense Retrieval
Aug 11, 2022


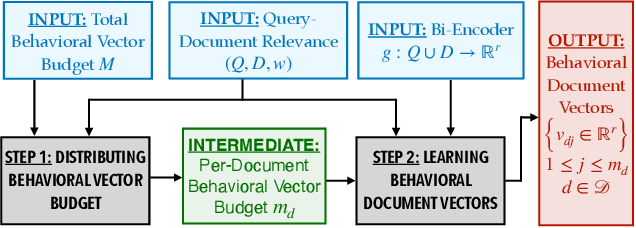
We consider text retrieval within dense representational space in real-world settings such as e-commerce search where (a) document popularity and (b) diversity of queries associated with a document have a skewed distribution. Most of the contemporary dense retrieval literature presents two shortcomings in these settings. (1) They learn an almost equal number of representations per document, agnostic to the fact that a few head documents are disproportionately more critical to achieving a good retrieval performance. (ii) They learn purely semantic document representations inferred from intrinsic document characteristics which may not contain adequate information to determine the queries for which the document is relevant--especially when the document is short. We propose to overcome these limitations by augmenting semantic document representations learned by bi-encoders with behavioral document representations learned by our proposed approach MVG. To do so, MVG (1) determines how to divide the total budget for behavioral representations by drawing a connection to the Pitman-Yor process, and (2) simply clusters the queries related to a given document (based on user behavior) within the representational space learned by a base bi-encoder, and treats the cluster centers as its behavioral representations. Our central contribution is the finding such a simple intuitive light-weight approach leads to substantial gains in key first-stage retrieval metrics by incurring only a marginal memory overhead. We establish this via extensive experiments over three large public datasets comparing several single-vector and multi-vector bi-encoders, a proprietary e-commerce search dataset compared to production-quality bi-encoder, and an A/B test.
A Fast Randomized Algorithm for Massive Text Normalization
Oct 06, 2021
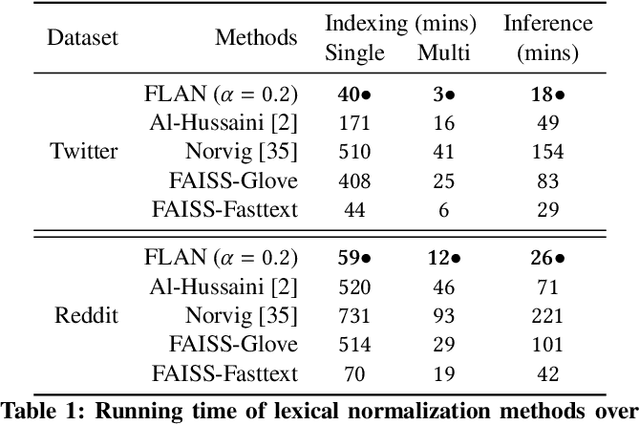
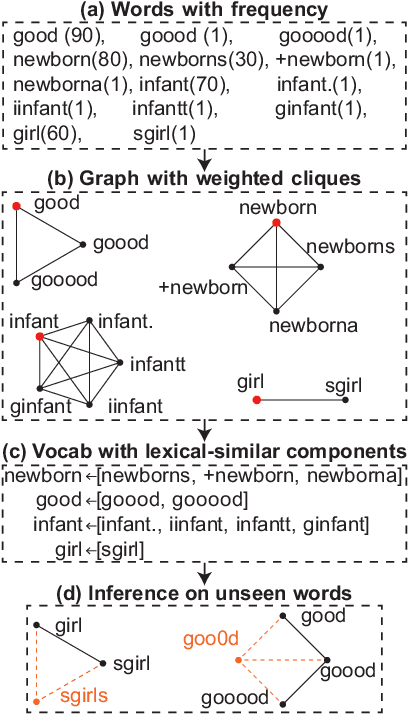
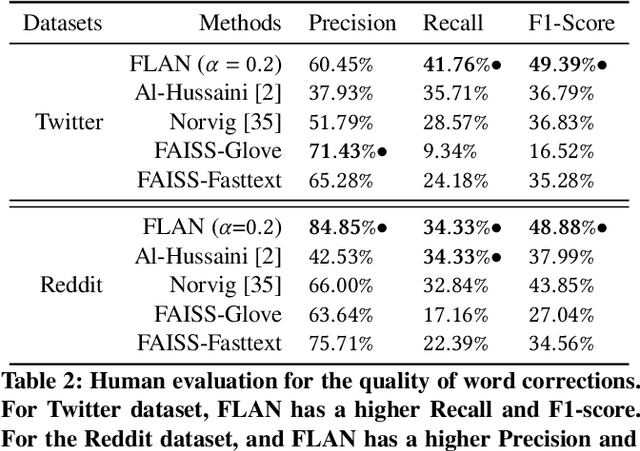
Many popular machine learning techniques in natural language processing and data mining rely heavily on high-quality text sources. However real-world text datasets contain a significant amount of spelling errors and improperly punctuated variants where the performance of these models would quickly deteriorate. Moreover, real-world, web-scale datasets contain hundreds of millions or even billions of lines of text, where the existing text cleaning tools are prohibitively expensive to execute over and may require an overhead to learn the corrections. In this paper, we present FLAN, a scalable randomized algorithm to clean and canonicalize massive text data. Our algorithm relies on the Jaccard similarity between words to suggest correction results. We efficiently handle the pairwise word-to-word comparisons via Locality Sensitive Hashing (LSH). We also propose a novel stabilization process to address the issue of hash collisions between dissimilar words, which is a consequence of the randomized nature of LSH and is exacerbated by the massive scale of real-world datasets. Compared with existing approaches, our method is more efficient, both asymptotically and in empirical evaluations, and does not rely on additional features, such as lexical/phonetic similarity or word embedding features. In addition, FLAN does not require any annotated data or supervised learning. We further theoretically show the robustness of our algorithm with upper bounds on the false positive and false negative rates of corrections. Our experimental results on real-world datasets demonstrate the efficiency and efficacy of FLAN.