 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Value of Behavioral Representations for Dense Retrieval
Aug 11, 2022


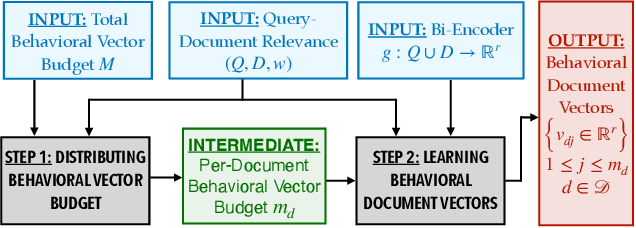
We consider text retrieval within dense representational space in real-world settings such as e-commerce search where (a) document popularity and (b) diversity of queries associated with a document have a skewed distribution. Most of the contemporary dense retrieval literature presents two shortcomings in these settings. (1) They learn an almost equal number of representations per document, agnostic to the fact that a few head documents are disproportionately more critical to achieving a good retrieval performance. (ii) They learn purely semantic document representations inferred from intrinsic document characteristics which may not contain adequate information to determine the queries for which the document is relevant--especially when the document is short. We propose to overcome these limitations by augmenting semantic document representations learned by bi-encoders with behavioral document representations learned by our proposed approach MVG. To do so, MVG (1) determines how to divide the total budget for behavioral representations by drawing a connection to the Pitman-Yor process, and (2) simply clusters the queries related to a given document (based on user behavior) within the representational space learned by a base bi-encoder, and treats the cluster centers as its behavioral representations. Our central contribution is the finding such a simple intuitive light-weight approach leads to substantial gains in key first-stage retrieval metrics by incurring only a marginal memory overhead. We establish this via extensive experiments over three large public datasets comparing several single-vector and multi-vector bi-encoders, a proprietary e-commerce search dataset compared to production-quality bi-encoder, and an A/B test.