 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Value of Behavioral Representations for Dense Retrieval
Aug 11, 2022


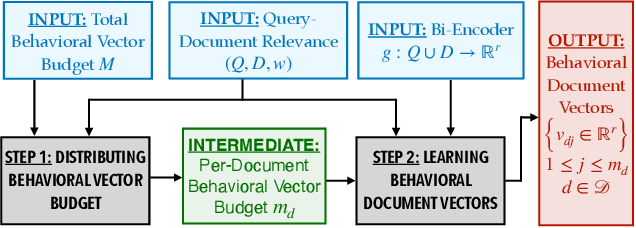
We consider text retrieval within dense representational space in real-world settings such as e-commerce search where (a) document popularity and (b) diversity of queries associated with a document have a skewed distribution. Most of the contemporary dense retrieval literature presents two shortcomings in these settings. (1) They learn an almost equal number of representations per document, agnostic to the fact that a few head documents are disproportionately more critical to achieving a good retrieval performance. (ii) They learn purely semantic document representations inferred from intrinsic document characteristics which may not contain adequate information to determine the queries for which the document is relevant--especially when the document is short. We propose to overcome these limitations by augmenting semantic document representations learned by bi-encoders with behavioral document representations learned by our proposed approach MVG. To do so, MVG (1) determines how to divide the total budget for behavioral representations by drawing a connection to the Pitman-Yor process, and (2) simply clusters the queries related to a given document (based on user behavior) within the representational space learned by a base bi-encoder, and treats the cluster centers as its behavioral representations. Our central contribution is the finding such a simple intuitive light-weight approach leads to substantial gains in key first-stage retrieval metrics by incurring only a marginal memory overhead. We establish this via extensive experiments over three large public datasets comparing several single-vector and multi-vector bi-encoders, a proprietary e-commerce search dataset compared to production-quality bi-encoder, and an A/B test.
Benefit-aware Early Prediction of Health Outcomes on Multivariate EEG Time Series
Nov 11, 2021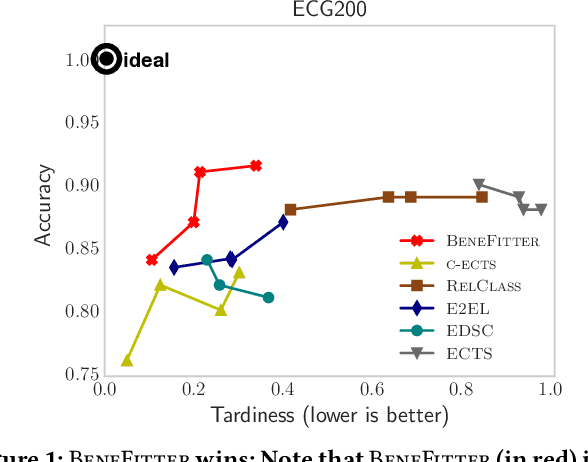
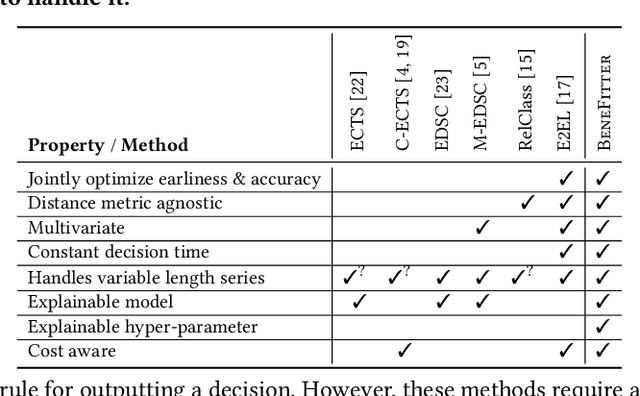
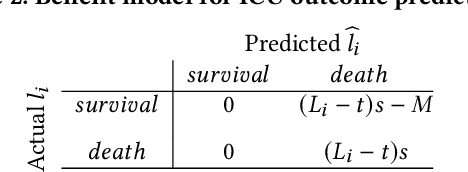
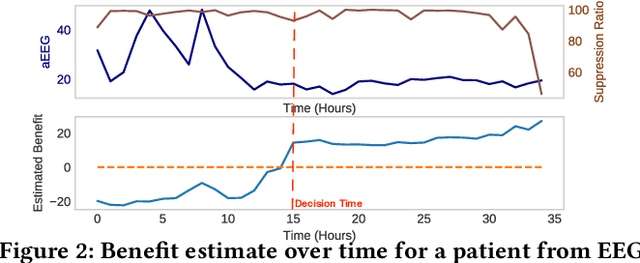
Given a cardiac-arrest patient being monitored in the ICU (intensive care unit) for brain activity, how can we predict their health outcomes as early as possible? Early decision-making is critical in many applications, e.g. monitoring patients may assist in early intervention and improved care. On the other hand, early prediction on EEG data poses several challenges: (i) earliness-accuracy trade-off; observing more data often increases accuracy but sacrifices earliness, (ii) large-scale (for training) and streaming (online decision-making) data processing, and (iii) multi-variate (due to multiple electrodes) and multi-length (due to varying length of stay of patients) time series. Motivated by this real-world application, we present BeneFitter that infuses the incurred savings from an early prediction as well as the cost from misclassification into a unified domain-specific target called benefit. Unifying these two quantities allows us to directly estimate a single target (i.e. benefit), and importantly, dictates exactly when to output a prediction: when benefit estimate becomes positive. BeneFitter (a) is efficient and fast, with training time linear in the number of input sequences, and can operate in real-time for decision-making, (b) can handle multi-variate and variable-length time-series, suitable for patient data, and (c) is effective, providing up to 2x time-savings with equal or better accuracy as compared to competitors.
Higher-Order Label Homogeneity and Spreading in Graphs
Feb 18, 2020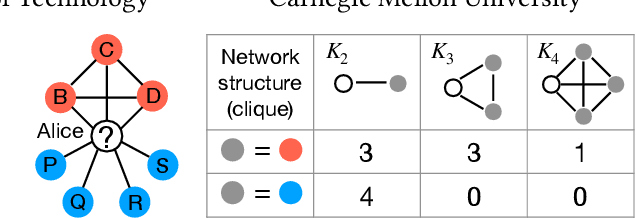
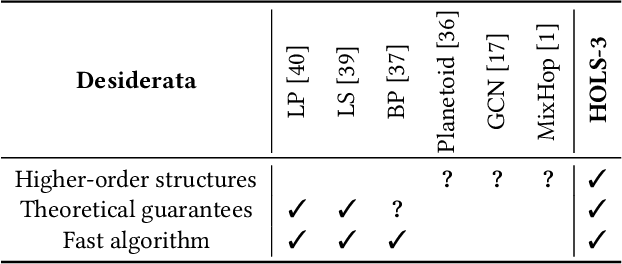

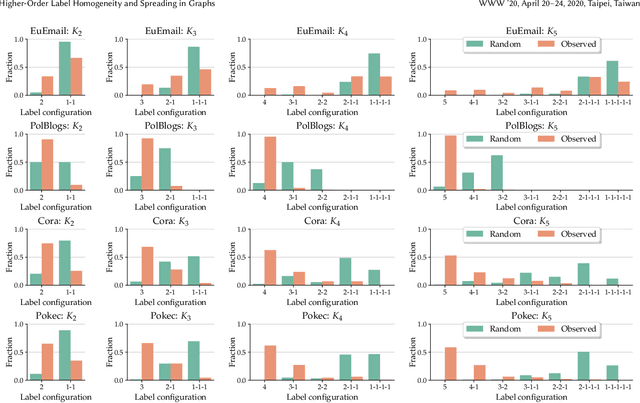
Do higher-order network structures aid graph semi-supervised learning? Given a graph and a few labeled vertices, labeling the remaining vertices is a high-impact problem with applications in several tasks, such as recommender systems, fraud detection and protein identification. However, traditional methods rely on edges for spreading labels, which is limited as all edges are not equal. Vertices with stronger connections participate in higher-order structures in graphs, which calls for methods that can leverage these structures in the semi-supervised learning tasks. To this end, we propose Higher-Order Label Spreading (HOLS) to spread labels using higher-order structures. HOLS has strong theoretical guarantees and reduces to standard label spreading in the base case. Via extensive experiments, we show that higher-order label spreading using triangles in addition to edges is up to 4.7% better than label spreading using edges alone. Compared to prior traditional and state-of-the-art methods, the proposed method leads to statistically significant accuracy gains in all-but-one cases, while remaining fast and scalable to large graphs.
Why You Should Charge Your Friends for Borrowing Your Stuff
May 20, 2017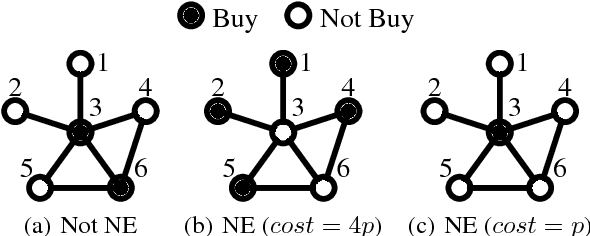
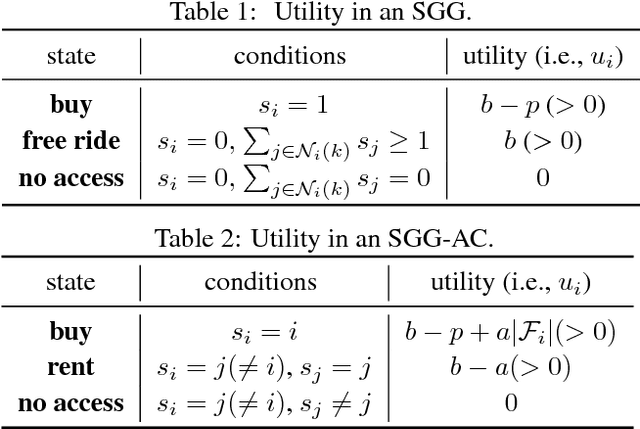

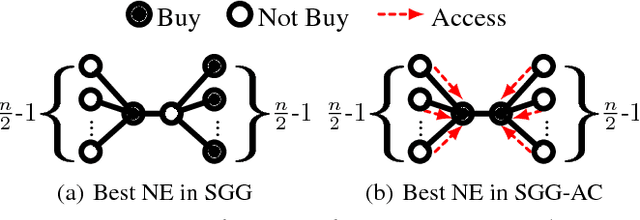
We consider goods that can be shared with k-hop neighbors (i.e., the set of nodes within k hops from an owner) on a social network. We examine incentives to buy such a good by devising game-theoretic models where each node decides whether to buy the good or free ride. First, we find that social inefficiency, specifically excessive purchase of the good, occurs in Nash equilibria. Second, the social inefficiency decreases as k increases and thus a good can be shared with more nodes. Third, and most importantly, the social inefficiency can also be significantly reduced by charging free riders an access cost and paying it to owners, leading to the conclusion that organizations and system designers should impose such a cost. These findings are supported by our theoretical analysis in terms of the price of anarchy and the price of stability; and by simulations based on synthetic and real social networks.