 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroeconomic Forecasting with Large Language Models
Jul 01, 2024This paper presents a comparative analysis evaluating the accuracy of Large Language Models (LLMs) against traditional macro time series forecasting approaches. In recent times, LLMs have surged in popularity for forecasting due to their ability to capture intricate patterns in data and quickly adapt across very different domains. However, their effectiveness in forecasting macroeconomic time series data compared to conventional methods remains an area of interest. To address this, we conduct a rigorous evaluation of LLMs against traditional macro forecasting methods, using as common ground the FRED-MD database. Our findings provide valuable insights into the strengths and limitations of LLMs in forecasting macroeconomic time series, shedding light on their applicability in real-world scenarios
UltraProp: Principled and Explainable Propagation on Large Graphs
Dec 31, 2022Given a large graph with few node labels, how can we (a) identify the mixed network-effect of the graph and (b) predict the unknown labels accurately and efficiently? This work proposes Network Effect Analysis (NEA) and UltraProp, which are based on two insights: (a) the network-effect (NE) insight: a graph can exhibit not only one of homophily and heterophily, but also both or none in a label-wise manner, and (b) the neighbor-differentiation (ND) insight: neighbors have different degrees of influence on the target node based on the strength of connections. NEA provides a statistical test to check whether a graph exhibits network-effect or not, and surprisingly discovers the absence of NE in many real-world graphs known to have heterophily. UltraProp solves the node classification problem with notable advantages: (a) Accurate, thanks to the network-effect (NE) and neighbor-differentiation (ND) insights; (b) Explainable, precisely estimating the compatibility matrix; (c) Scalable, being linear with the input size and handling graphs with millions of nodes; and (d) Principled, with closed-form formula and theoretical guarantee. Applied on eight real-world graph datasets, UltraProp outperforms top competitors in terms of accuracy and run time, requiring only stock CPU servers. On a large real-world graph with 1.6M nodes and 22.3M edges, UltraProp achieves more than 9 times speedup (12 minutes vs. 2 hours) compared to most competitors.
Unsupervised Machine Learning for Explainable Medicare Fraud Detection
Nov 09, 2022The US federal government spends more than a trillion dollars per year on health care, largely provided by private third parties and reimbursed by the government. A major concern in this system is overbilling, waste and fraud by providers, who face incentives to misreport on their claims in order to receive higher payments. In this paper, we develop novel machine learning tools to identify providers that overbill Medicare, the US federal health insurance program for elderly adults and the disabled. Using large-scale Medicare claims data, we identify patterns consistent with fraud or overbilling among inpatient hospitalizations. Our proposed approach for Medicare fraud detection is fully unsupervised, not relying on any labeled training data, and is explainable to end users, providing reasoning and interpretable insights into the potentially suspicious behavior of the flagged providers. Data from the Department of Justice on providers facing anti-fraud lawsuits and several case studies validate our approach and findings both quantitatively and qualitatively.
SlenderGNN: Accurate, Robust, and Interpretable GNN, and the Reasons for its Success
Oct 08, 2022

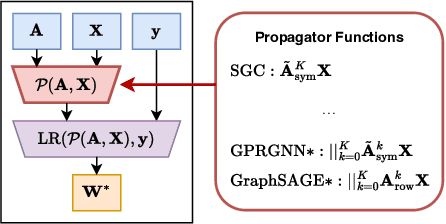
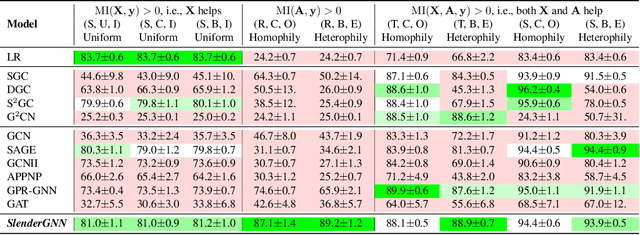
Can we design a GNN that is accurate and interpretable at the same time? Could it also be robust to handle the case of homophily, heterophily, or even noisy edges without network effects? We propose SlenderGNN that has all desirable properties: (a) accurate, (b) robust, and (c) interpretable. For the reasons of its success, we had to dig deeper: The result is our GNNLin framework which highlights the fundamental differences among popular GNN models (e.g., feature combination, structural normalization, etc.) and thus reveals the reasons for the success of our SlenderGNN, as well as the reasons for occasional failures of other GNN variants. Thanks to our careful design, SlenderGNN passes all the 'sanity checks' we propose, and it achieves the highest overall accuracy on 9 real-world datasets of both homophily and heterophily graphs, when compared against 10 recent GNN models. Specifically, SlenderGNN exceeds the accuracy of linear GNNs and matches or exceeds the accuracy of nonlinear models with up to 64 times fewer parameters.
Benefit-aware Early Prediction of Health Outcomes on Multivariate EEG Time Series
Nov 11, 2021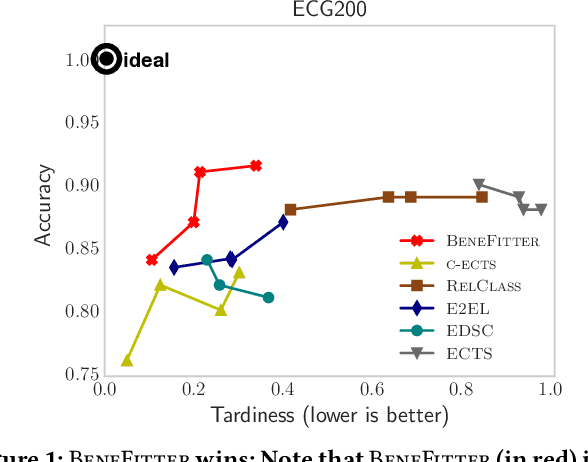
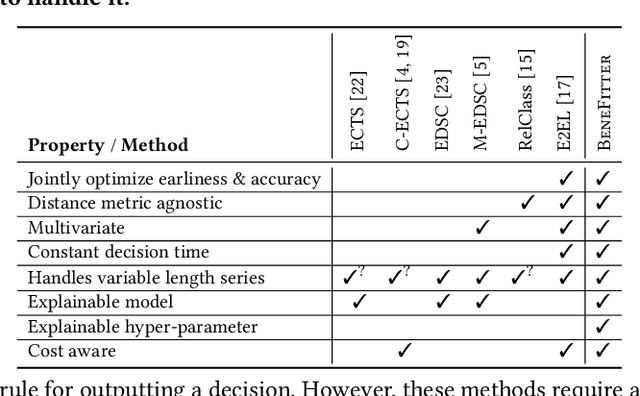
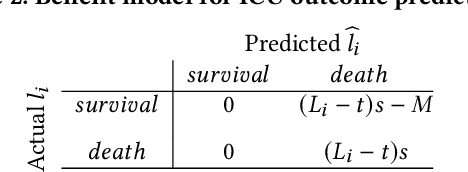
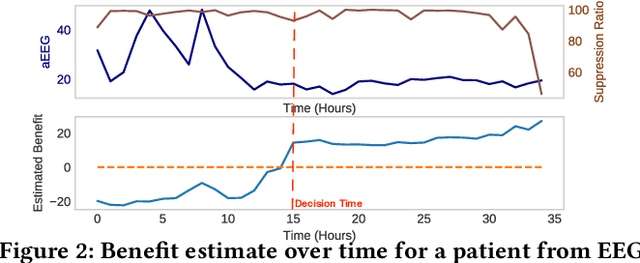
Given a cardiac-arrest patient being monitored in the ICU (intensive care unit) for brain activity, how can we predict their health outcomes as early as possible? Early decision-making is critical in many applications, e.g. monitoring patients may assist in early intervention and improved care. On the other hand, early prediction on EEG data poses several challenges: (i) earliness-accuracy trade-off; observing more data often increases accuracy but sacrifices earliness, (ii) large-scale (for training) and streaming (online decision-making) data processing, and (iii) multi-variate (due to multiple electrodes) and multi-length (due to varying length of stay of patients) time series. Motivated by this real-world application, we present BeneFitter that infuses the incurred savings from an early prediction as well as the cost from misclassification into a unified domain-specific target called benefit. Unifying these two quantities allows us to directly estimate a single target (i.e. benefit), and importantly, dictates exactly when to output a prediction: when benefit estimate becomes positive. BeneFitter (a) is efficient and fast, with training time linear in the number of input sequences, and can operate in real-time for decision-making, (b) can handle multi-variate and variable-length time-series, suitable for patient data, and (c) is effective, providing up to 2x time-savings with equal or better accuracy as compared to competitors.
gen2Out: Detecting and Ranking Generalized Anomalies
Sep 06, 2021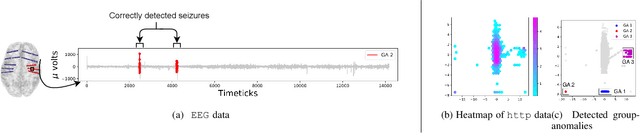
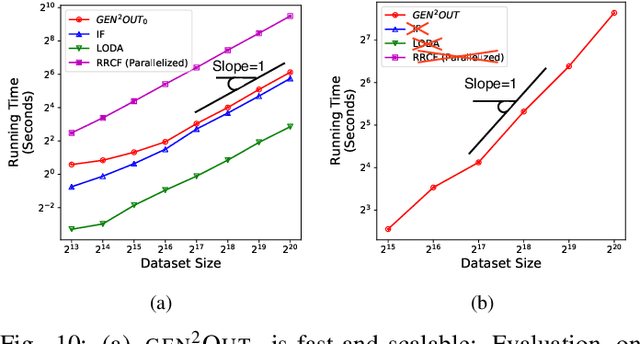
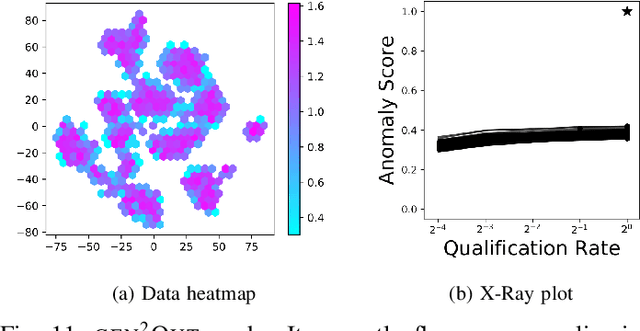
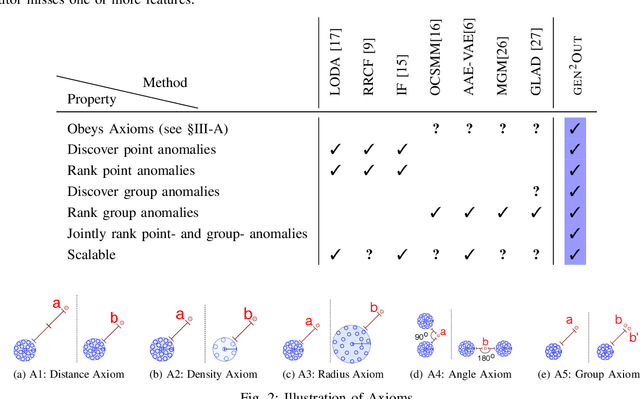
In a cloud of m-dimensional data points, how would we spot, as well as rank, both single-point- as well as group- anomalies? We are the first to generalize anomaly detection in two dimensions: The first dimension is that we handle both point-anomalies, as well as group-anomalies, under a unified view -- we shall refer to them as generalized anomalies. The second dimension is that gen2Out not only detects, but also ranks, anomalies in suspiciousness order. Detection, and ranking, of anomalies has numerous applications: For example, in EEG recordings of an epileptic patient, an anomaly may indicate a seizure; in computer network traffic data, it may signify a power failure, or a DoS/DDoS attack. We start by setting some reasonable axioms; surprisingly, none of the earlier methods pass all the axioms. Our main contribution is the gen2Out algorithm, that has the following desirable properties: (a) Principled and Sound anomaly scoring that obeys the axioms for detectors, (b) Doubly-general in that it detects, as well as ranks generalized anomaly -- both point- and group-anomalies, (c) Scalable, it is fast and scalable, linear on input size. (d) Effective, experiments on real-world epileptic recordings (200GB) demonstrate effectiveness of gen2Out as confirmed by clinicians. Experiments on 27 real-world benchmark datasets show that gen2Out detects ground truth groups, matches or outperforms point-anomaly baseline algorithms on accuracy, with no competition for group-anomalies and requires about 2 minutes for 1 million data points on a stock machine.
FAIROD: Fairness-aware Outlier Detection
Dec 05, 2020

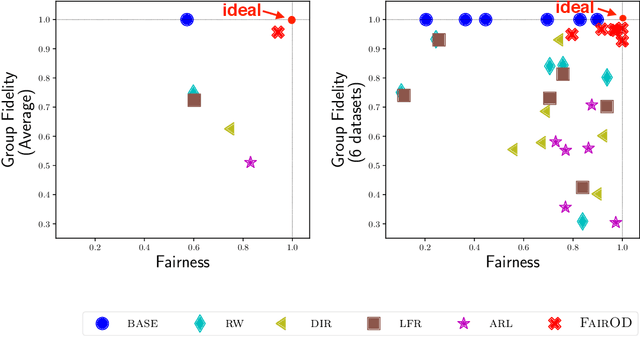

Fairness and Outlier Detection (OD) are closely related, as it is exactly the goal of OD to spot rare, minority samples in a given population. When being a minority (as defined by protected variables, e.g. race/ethnicity/sex/age) does not reflect positive-class membership (e.g. criminal/fraud), however, OD produces unjust outcomes. Surprisingly, fairness-aware OD has been almost untouched in prior work, as fair machine learning literature mainly focus on supervised settings. Our work aims to bridge this gap. Specifically, we develop desiderata capturing well-motivated fairness criteria for OD, and systematically formalize the fair OD problem. Further, guided by our desiderata, we propose FairOD, a fairness-aware outlier detector, which has the following, desirable properties: FairOD (1) does not employ disparate treatment at test time, (2) aims to flag equal proportions of samples from all groups (i.e. obtain group fairness, via statistical parity), and (3) strives to flag truly high-risk fraction of samples within each group. Extensive experiments on a diverse set of synthetic and real world datasets show that FairOD produces outcomes that are fair with respect to protected variables, while performing comparable to (and in some cases, even better than) fairness-agnostic detectors in terms of detection performance.
Incorporating Privileged Information to Unsupervised Anomaly Detection
May 24, 2018



We introduce a new unsupervised anomaly detection ensemble called SPI which can harness privileged information - data available only for training examples but not for (future) test examples. Our ideas build on the Learning Using Privileged Information (LUPI) paradigm pioneered by Vapnik et al. [19,17], which we extend to unsupervised learning and in particular to anomaly detection. SPI (for Spotting anomalies with Privileged Information) constructs a number of frames/fragments of knowledge (i.e., density estimates) in the privileged space and transfers them to the anomaly scoring space through "imitation" functions that use only the partial information available for test examples. Our generalization of the LUPI paradigm to unsupervised anomaly detection shepherds the field in several key directions, including (i) domain knowledge-augmented detection using expert annotations as PI, (ii) fast detection using computationally-demanding data as PI, and (iii) early detection using "historical future" data as PI. Through extensive experiments on simulated and real datasets, we show that augmenting privileged information to anomaly detection significantly improves detection performance. We also demonstrate the promise of SPI under all three settings (i-iii); with PI capturing expert knowledge, computationally expensive features, and future data on three real world detection tasks.