 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Curse of Dimensionality: On the Stability of Modern Vector Retrieval
Dec 13, 2025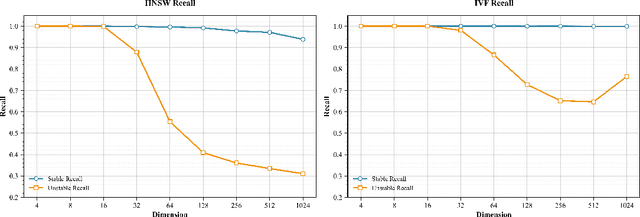
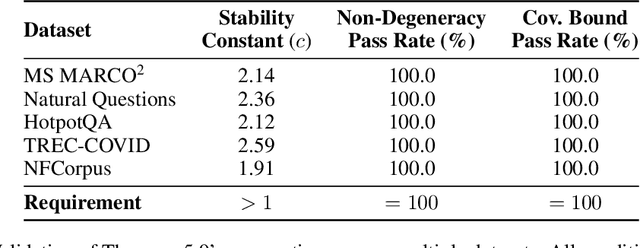
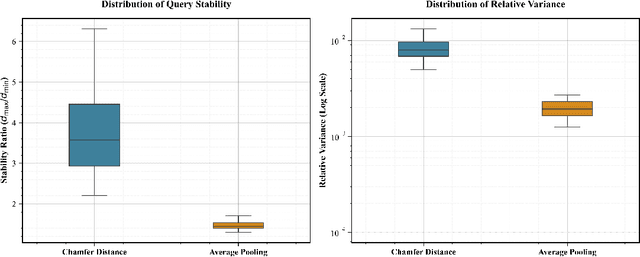
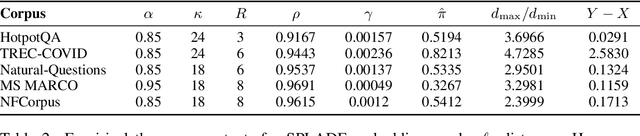
Modern vector databases enable efficient retrieval over high-dimensional neural embeddings, powering applications from web search to retrieval-augmented generation. However, classical theory predicts such tasks should suffer from the curse of dimensionality, where distances between points become nearly indistinguishable, thereby crippling efficient nearest-neighbor search. We revisit this paradox through the lens of stability, the property that small perturbations to a query do not radically alter its nearest neighbors. Building on foundational results, we extend stability theory to three key retrieval settings widely used in practice: (i) multi-vector search, where we prove that the popular Chamfer distance metric preserves single-vector stability, while average pooling aggregation may destroy it; (ii) filtered vector search, where we show that sufficiently large penalties for mismatched filters can induce stability even when the underlying search is unstable; and (iii) sparse vector search, where we formalize and prove novel sufficient stability conditions. Across synthetic and real datasets, our experimental results match our theoretical predictions, offering concrete guidance for model and system design to avoid the curse of dimensionality.
Down with the Hierarchy: The 'H' in HNSW Stands for "Hubs"
Dec 02, 2024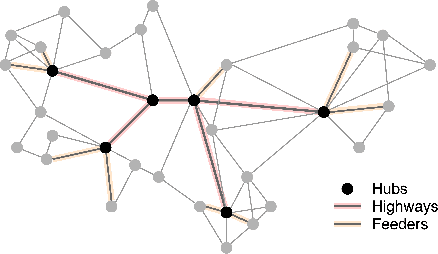

Driven by recent breakthrough advances in neural representation learning, approximate near-neighbor (ANN) search over vector embeddings has emerged as a critical computational workload. With the introduction of the seminal Hierarchical Navigable Small World (HNSW) algorithm, graph-based indexes have established themseves as the overwhelmingly dominant paradigm for efficient and scalable ANN search. As the name suggests, HNSW searches a layered hierarchical graph to quickly identify neighborhoods of similar points to a given query vector. But is this hierarchy even necessary? A rigorous experimental analysis to answer this question would provide valuable insights into the nature of algorithm design for ANN search and motivate directions for future work in this increasingly crucial domain. To that end, we conduct an extensive benchmarking study covering more large-scale datasets than prior investigations of this question. We ultimately find that a flat graph retains all of the benefits of HNSW on high-dimensional datasets, with latency and recall performance essentially \emph{identical} to the original algorithm but with less memory overhead. Furthermore, we go a step further and study \emph{why} the hierarchy of HNSW provides no benefit in high dimensions, hypothesizing that navigable small world graphs contain a well-connected, frequently traversed ``highway" of hub nodes that maintain the same purported function as the hierarchical layers. We present compelling empirical evidence that the \emph{Hub Highway Hypothesis} holds for real datasets and investigate the mechanisms by which the highway forms. The implications of this hypothesis may also provide future research directions in developing enhancements to graph-based ANN search.
On the Diminishing Returns of Width for Continual Learning
Mar 14, 2024While deep neural networks have demonstrated groundbreaking performance in various settings, these models often suffer from \emph{catastrophic forgetting} when trained on new tasks in sequence. Several works have empirically demonstrated that increasing the width of a neural network leads to a decrease in catastrophic forgetting but have yet to characterize the exact relationship between width and continual learning. We design one of the first frameworks to analyze Continual Learning Theory and prove that width is directly related to forgetting in Feed-Forward Networks (FFN). Specifically, we demonstrate that increasing network widths to reduce forgetting yields diminishing returns. We empirically verify our claims at widths hitherto unexplored in prior studies where the diminishing returns are clearly observed as predicted by our theory.
CAPS: A Practical Partition Index for Filtered Similarity Search
Aug 29, 2023



With the surging popularity of approximate near-neighbor search (ANNS), driven by advances in neural representation learning, the ability to serve queries accompanied by a set of constraints has become an area of intense interest. While the community has recently proposed several algorithms for constrained ANNS, almost all of these methods focus on integration with graph-based indexes, the predominant class of algorithms achieving state-of-the-art performance in latency-recall tradeoffs. In this work, we take a different approach and focus on developing a constrained ANNS algorithm via space partitioning as opposed to graphs. To that end, we introduce Constrained Approximate Partitioned Search (CAPS), an index for ANNS with filters via space partitions that not only retains the benefits of a partition-based algorithm but also outperforms state-of-the-art graph-based constrained search techniques in recall-latency tradeoffs, with only 10% of the index size.
CARAMEL: A Succinct Read-Only Lookup Table via Compressed Static Functions
May 26, 2023


Lookup tables are a fundamental structure in many data processing and systems applications. Examples include tokenized text in NLP, quantized embedding collections in recommendation systems, integer sketches for streaming data, and hash-based string representations in genomics. With the increasing size of web-scale data, such applications often require compression techniques that support fast random $O(1)$ lookup of individual parameters directly on the compressed data (i.e. without blockwise decompression in RAM). While the community has proposd a number of succinct data structures that support queries over compressed representations, these approaches do not fully leverage the low-entropy structure prevalent in real-world workloads to reduce space. Inspired by recent advances in static function construction techniques, we propose a space-efficient representation of immutable key-value data, called CARAMEL, specifically designed for the case where the values are multi-sets. By carefully combining multiple compressed static functions, CARAMEL occupies space proportional to the data entropy with low memory overheads and minimal lookup costs. We demonstrate 1.25-16x compression on practical lookup tasks drawn from real-world systems, improving upon established techniques, including a production-grade read-only database widely used for development within Amazon.com.
BOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023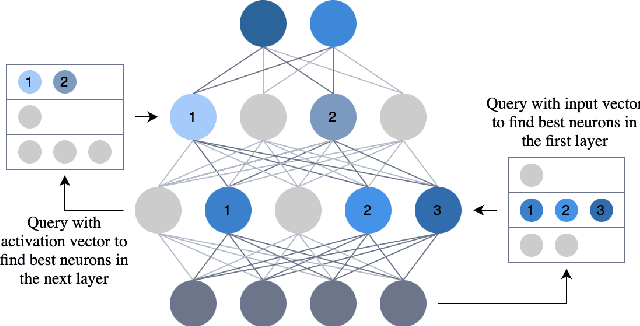
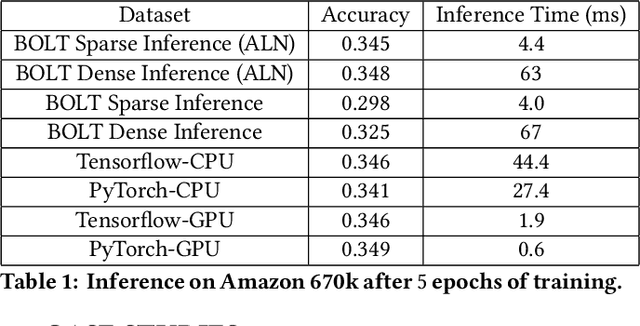
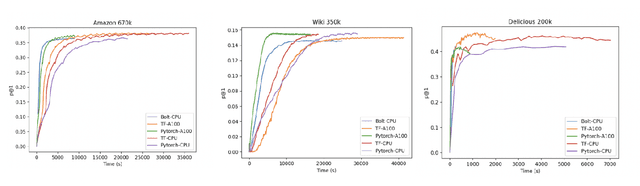
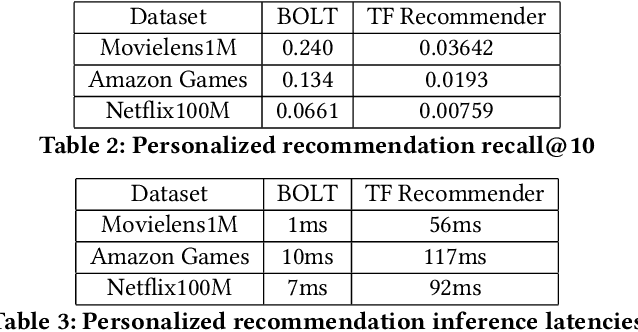
Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.
Low-Precision Quantization for Efficient Nearest Neighbor Search
Oct 17, 2021

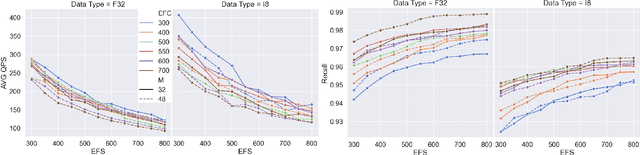

Fast k-Nearest Neighbor search over real-valued vector spaces (KNN) is an important algorithmic task for information retrieval and recommendation systems. We present a method for using reduced precision to represent vectors through quantized integer values, enabling both a reduction in the memory overhead of indexing these vectors and faster distance computations at query time. While most traditional quantization techniques focus on minimizing the reconstruction error between a point and its uncompressed counterpart, we focus instead on preserving the behavior of the underlying distance metric. Furthermore, our quantization approach is applied at the implementation level and can be combined with existing KNN algorithms. Our experiments on both open source and proprietary datasets across multiple popular KNN frameworks validate that quantized distance metrics can reduce memory by 60% and improve query throughput by 30%, while incurring only a 2% reduction in recall.
Embracing Structure in Data for Billion-Scale Semantic Product Search
Oct 12, 2021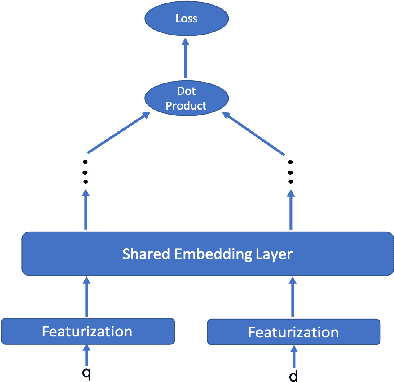
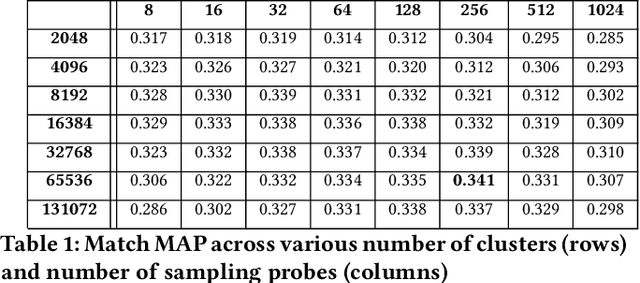
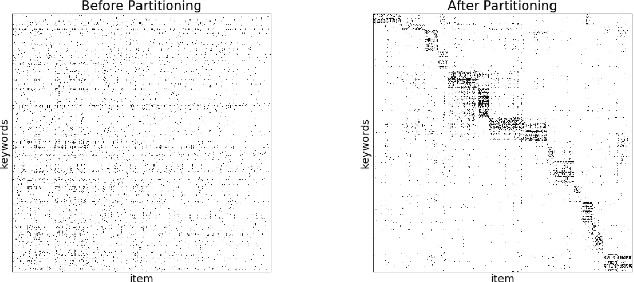
We present principled approaches to train and deploy dyadic neural embedding models at the billion scale, focusing our investigation on the application of semantic product search. When training a dyadic model, one seeks to embed two different types of entities (e.g., queries and documents or users and movies) in a common vector space such that pairs with high relevance are positioned nearby. During inference, given an embedding of one type (e.g., a query or a user), one seeks to retrieve the entities of the other type (e.g., documents or movies, respectively) that are highly relevant. In this work, we show that exploiting the natural structure of real-world datasets helps address both challenges efficiently. Specifically, we model dyadic data as a bipartite graph with edges between pairs with positive associations. We then propose to partition this network into semantically coherent clusters and thus reduce our search space by focusing on a small subset of these partitions for a given input. During training, this technique enables us to efficiently mine hard negative examples while, at inference, we can quickly find the nearest neighbors for a given embedding. We provide offline experimental results that demonstrate the efficacy of our techniques for both training and inference on a billion-scale Amazon.com product search dataset.
A Fast Randomized Algorithm for Massive Text Normalization
Oct 06, 2021
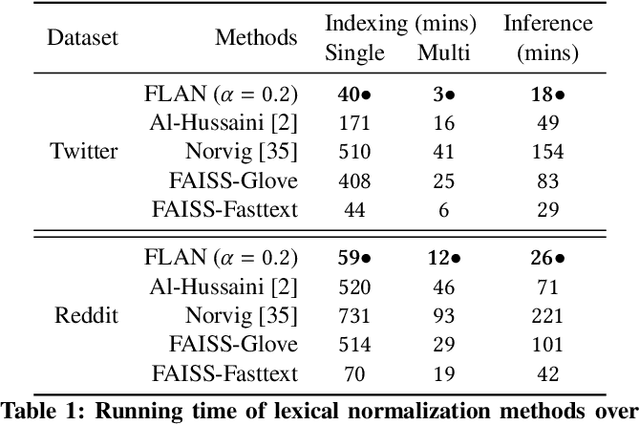
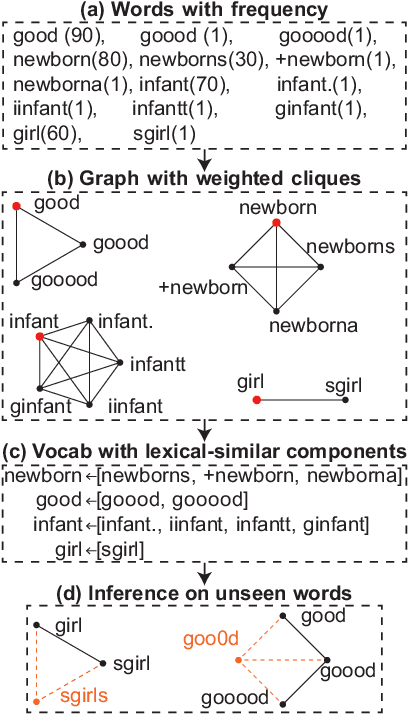
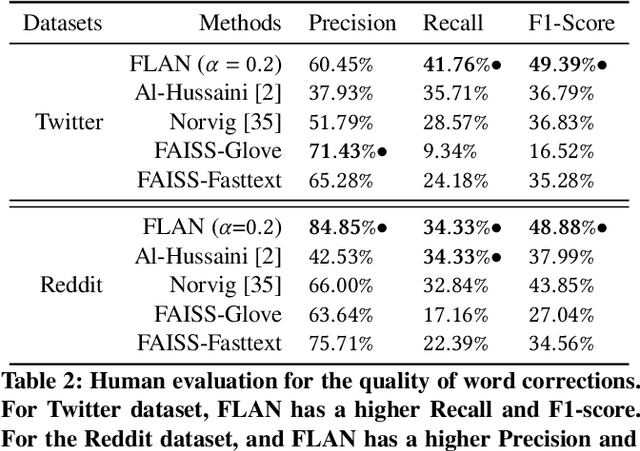
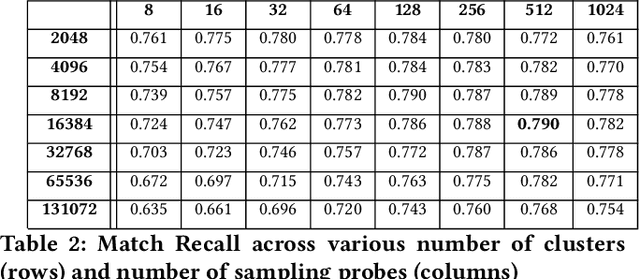
Many popular machine learning techniques in natural language processing and data mining rely heavily on high-quality text sources. However real-world text datasets contain a significant amount of spelling errors and improperly punctuated variants where the performance of these models would quickly deteriorate. Moreover, real-world, web-scale datasets contain hundreds of millions or even billions of lines of text, where the existing text cleaning tools are prohibitively expensive to execute over and may require an overhead to learn the corrections. In this paper, we present FLAN, a scalable randomized algorithm to clean and canonicalize massive text data. Our algorithm relies on the Jaccard similarity between words to suggest correction results. We efficiently handle the pairwise word-to-word comparisons via Locality Sensitive Hashing (LSH). We also propose a novel stabilization process to address the issue of hash collisions between dissimilar words, which is a consequence of the randomized nature of LSH and is exacerbated by the massive scale of real-world datasets. Compared with existing approaches, our method is more efficient, both asymptotically and in empirical evaluations, and does not rely on additional features, such as lexical/phonetic similarity or word embedding features. In addition, FLAN does not require any annotated data or supervised learning. We further theoretically show the robustness of our algorithm with upper bounds on the false positive and false negative rates of corrections. Our experimental results on real-world datasets demonstrate the efficiency and efficacy of FLAN.
Semantic Product Search
Jul 01, 2019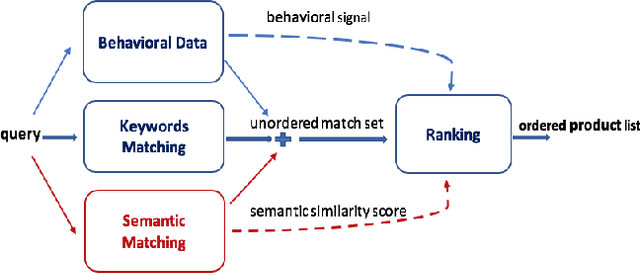
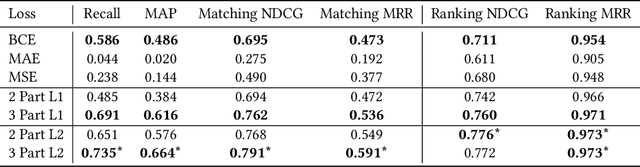
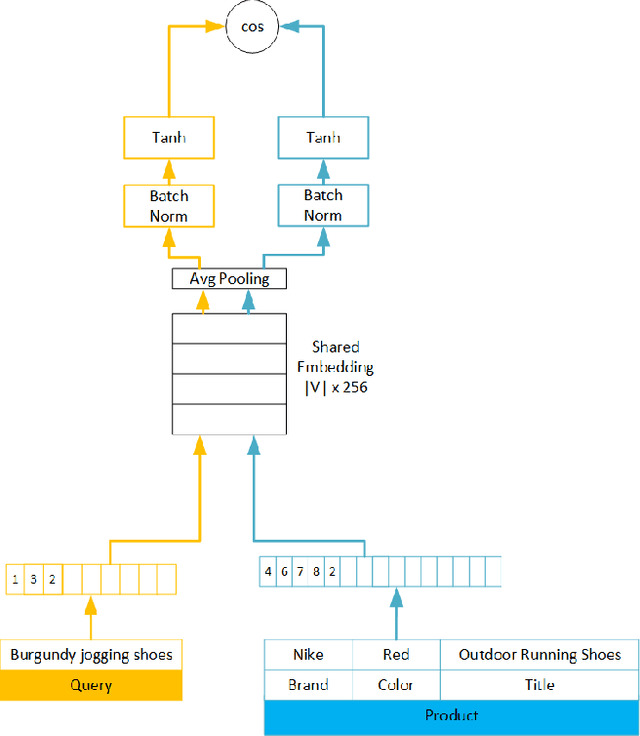
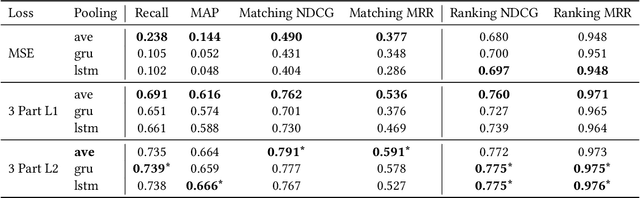
We study the problem of semantic matching in product search, that is, given a customer query, retrieve all semantically related products from the catalog. Pure lexical matching via an inverted index falls short in this respect due to several factors: a) lack of understanding of hypernyms, synonyms, and antonyms, b) fragility to morphological variants (e.g. "woman" vs. "women"), and c) sensitivity to spelling errors. To address these issues, we train a deep learning model for semantic matching using customer behavior data. Much of the recent work on large-scale semantic search using deep learning focuses on ranking for web search. In contrast, semantic matching for product search presents several novel challenges, which we elucidate in this paper. We address these challenges by a) developing a new loss function that has an inbuilt threshold to differentiate between random negative examples, impressed but not purchased examples, and positive examples (purchased items), b) using average pooling in conjunction with n-grams to capture short-range linguistic patterns, c) using hashing to handle out of vocabulary tokens, and d) using a model parallel training architecture to scale across 8 GPUs. We present compelling offline results that demonstrate at least 4.7% improvement in Recall@100 and 14.5% improvement in mean average precision (MAP) over baseline state-of-the-art semantic search methods using the same tokenization method. Moreover, we present results and discuss learnings from online A/B tests which demonstrate the efficacy of our method.