 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Structure in Data for Billion-Scale Semantic Product Search
Oct 12, 2021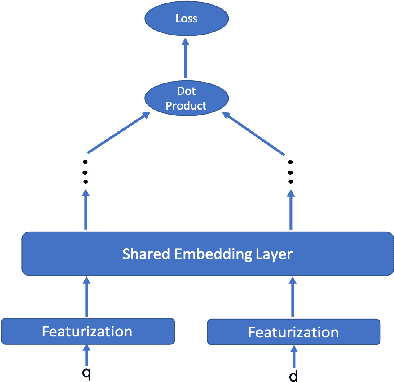
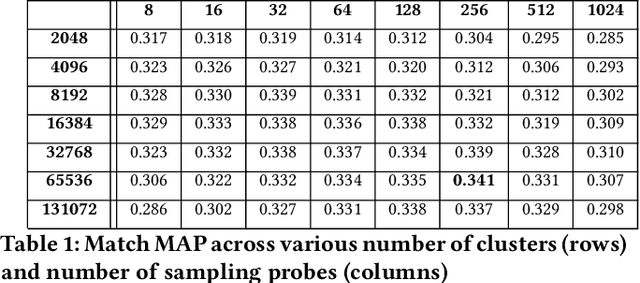
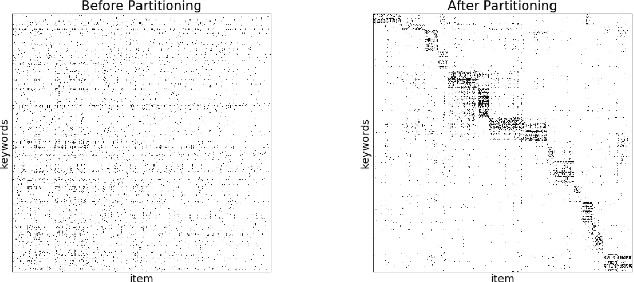
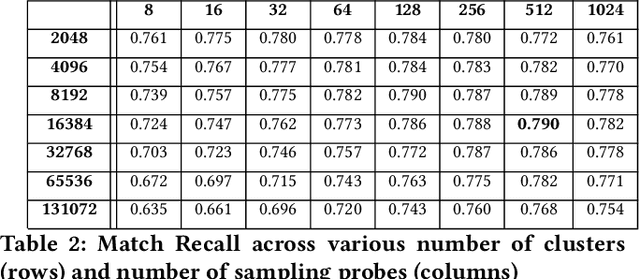
We present principled approaches to train and deploy dyadic neural embedding models at the billion scale, focusing our investigation on the application of semantic product search. When training a dyadic model, one seeks to embed two different types of entities (e.g., queries and documents or users and movies) in a common vector space such that pairs with high relevance are positioned nearby. During inference, given an embedding of one type (e.g., a query or a user), one seeks to retrieve the entities of the other type (e.g., documents or movies, respectively) that are highly relevant. In this work, we show that exploiting the natural structure of real-world datasets helps address both challenges efficiently. Specifically, we model dyadic data as a bipartite graph with edges between pairs with positive associations. We then propose to partition this network into semantically coherent clusters and thus reduce our search space by focusing on a small subset of these partitions for a given input. During training, this technique enables us to efficiently mine hard negative examples while, at inference, we can quickly find the nearest neighbors for a given embedding. We provide offline experimental results that demonstrate the efficacy of our techniques for both training and inference on a billion-scale Amazon.com product search dataset.
Adaptive, Personalized Diversity for Visual Discovery
Oct 02, 2018

Search queries are appropriate when users have explicit intent, but they perform poorly when the intent is difficult to express or if the user is simply looking to be inspired. Visual browsing systems allow e-commerce platforms to address these scenarios while offering the user an engaging shopping experience. Here we explore extensions in the direction of adaptive personalization and item diversification within Stream, a new form of visual browsing and discovery by Amazon. Our system presents the user with a diverse set of interesting items while adapting to user interactions. Our solution consists of three components (1) a Bayesian regression model for scoring the relevance of items while leveraging uncertainty, (2) a submodular diversification framework that re-ranks the top scoring items based on category, and (3) personalized category preferences learned from the user's behavior. When tested on live traffic, our algorithms show a strong lift in click-through-rate and session duration.
* Best Paper Award