 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
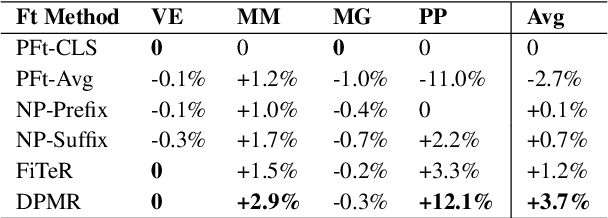
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025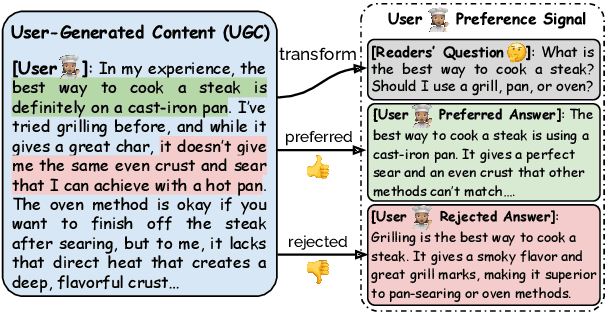
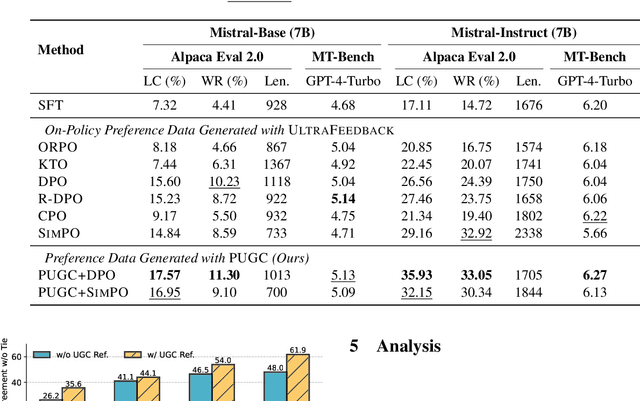
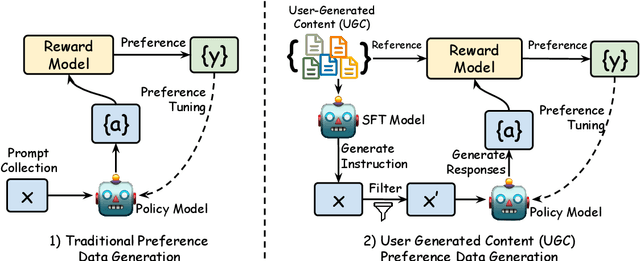

Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
Hephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Evolutionary Contrastive Distillation for Language Model Alignment
Oct 10, 2024
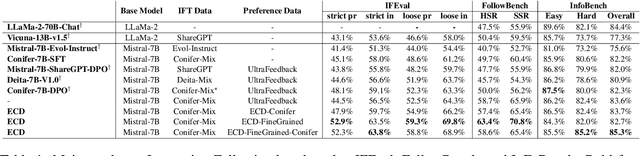
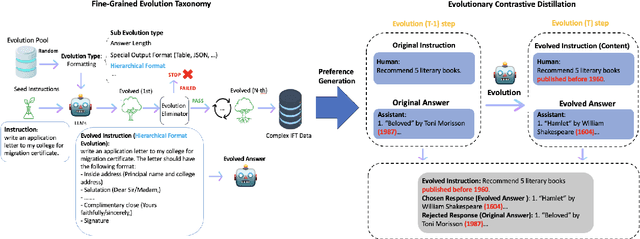

The ability of large language models (LLMs) to execute complex instructions is essential for their real-world applications. However, several recent studies indicate that LLMs struggle with challenging instructions. In this paper, we propose Evolutionary Contrastive Distillation (ECD), a novel method for generating high-quality synthetic preference data designed to enhance the complex instruction-following capability of language models. ECD generates data that specifically illustrates the difference between a response that successfully follows a set of complex instructions and a response that is high-quality, but nevertheless makes some subtle mistakes. This is done by prompting LLMs to progressively evolve simple instructions to more complex instructions. When the complexity of an instruction is increased, the original successful response to the original instruction becomes a "hard negative" response for the new instruction, mostly meeting requirements of the new instruction, but barely missing one or two. By pairing a good response with such a hard negative response, and employing contrastive learning algorithms such as DPO, we improve language models' ability to follow complex instructions. Empirically, we observe that our method yields a 7B model that exceeds the complex instruction-following performance of current SOTA 7B models and is competitive even with open-source 70B models.
DynaMaR: Dynamic Prompt with Mask Token Representation
Jun 07, 2022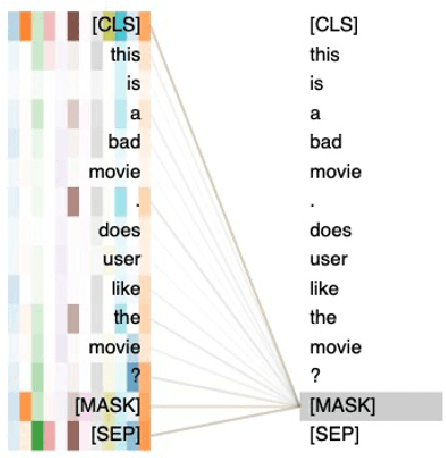
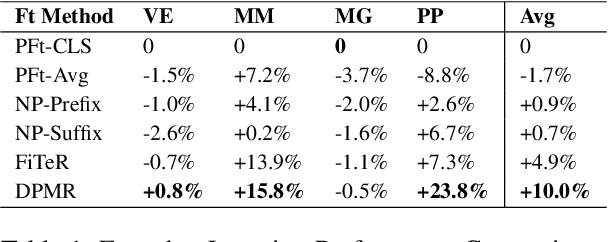
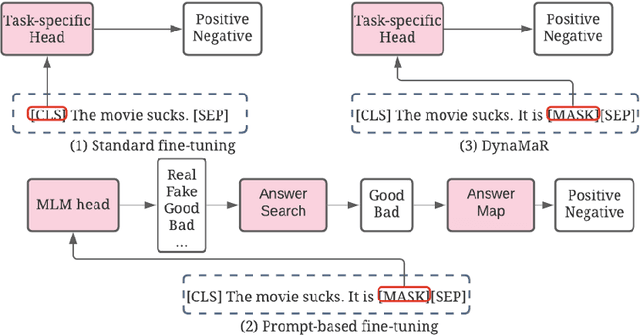
Recent research has shown that large language models pretrained using unsupervised approaches can achieve significant performance improvement on many downstream tasks. Typically when adapting these language models to downstream tasks, like a classification or regression task, we employ a fine-tuning paradigm in which the sentence representation from the language model is input to a task-specific head; the model is then fine-tuned end-to-end. However, with the emergence of models like GPT-3, prompt-based fine-tuning has been proven to be a successful approach for few-shot tasks. Inspired by this work, we study discrete prompt technologies in practice. There are two issues that arise with the standard prompt approach. First, it can overfit on the prompt template. Second, it requires manual effort to formulate the downstream task as a language model problem. In this paper, we propose an improvement to prompt-based fine-tuning that addresses these two issues. We refer to our approach as DynaMaR -- Dynamic Prompt with Mask Token Representation. Results show that DynaMaR can achieve an average improvement of 10% in few-shot settings and improvement of 3.7% in data-rich settings over the standard fine-tuning approach on four e-commerce applications.
Embracing Structure in Data for Billion-Scale Semantic Product Search
Oct 12, 2021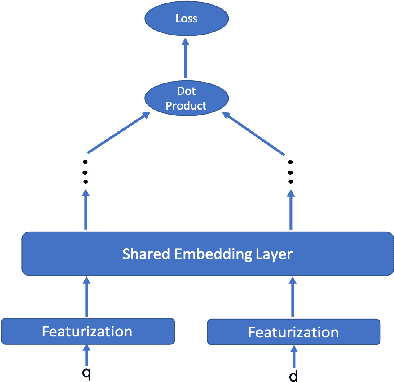
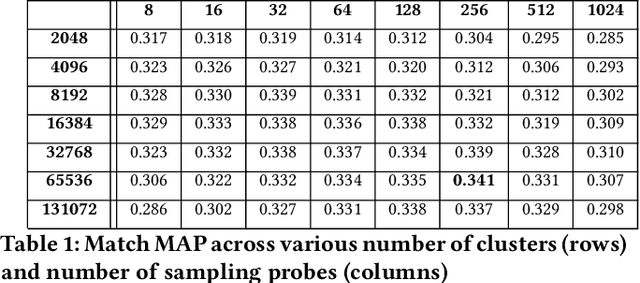
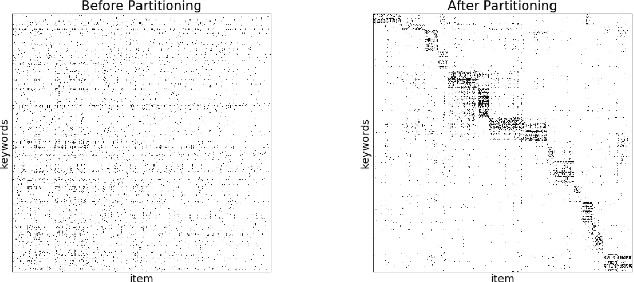
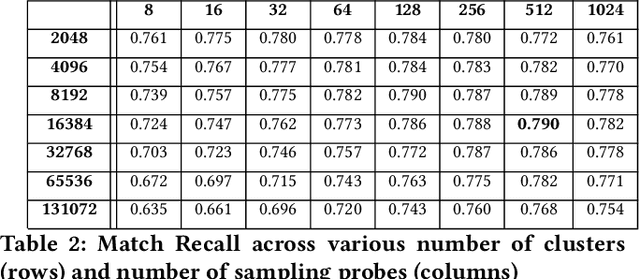
We present principled approaches to train and deploy dyadic neural embedding models at the billion scale, focusing our investigation on the application of semantic product search. When training a dyadic model, one seeks to embed two different types of entities (e.g., queries and documents or users and movies) in a common vector space such that pairs with high relevance are positioned nearby. During inference, given an embedding of one type (e.g., a query or a user), one seeks to retrieve the entities of the other type (e.g., documents or movies, respectively) that are highly relevant. In this work, we show that exploiting the natural structure of real-world datasets helps address both challenges efficiently. Specifically, we model dyadic data as a bipartite graph with edges between pairs with positive associations. We then propose to partition this network into semantically coherent clusters and thus reduce our search space by focusing on a small subset of these partitions for a given input. During training, this technique enables us to efficiently mine hard negative examples while, at inference, we can quickly find the nearest neighbors for a given embedding. We provide offline experimental results that demonstrate the efficacy of our techniques for both training and inference on a billion-scale Amazon.com product search dataset.
Semantic Product Search
Jul 01, 2019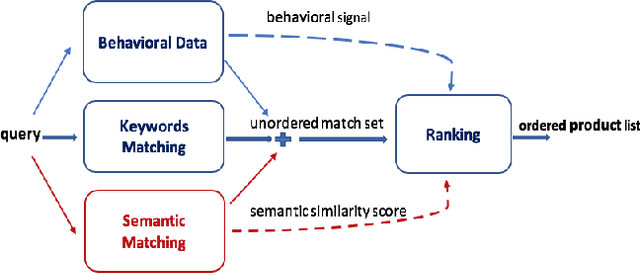
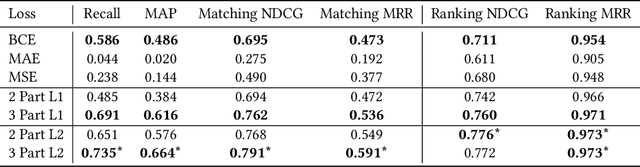
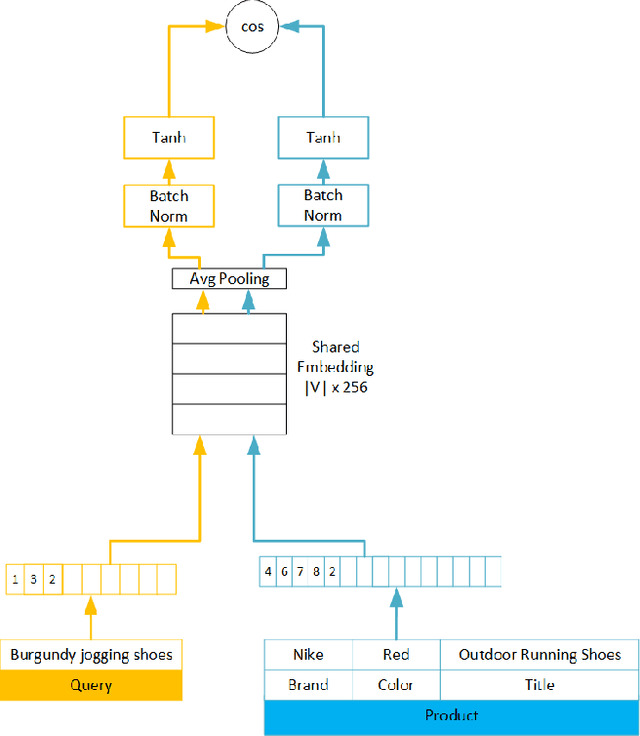
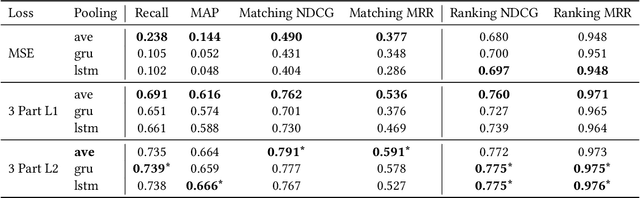
We study the problem of semantic matching in product search, that is, given a customer query, retrieve all semantically related products from the catalog. Pure lexical matching via an inverted index falls short in this respect due to several factors: a) lack of understanding of hypernyms, synonyms, and antonyms, b) fragility to morphological variants (e.g. "woman" vs. "women"), and c) sensitivity to spelling errors. To address these issues, we train a deep learning model for semantic matching using customer behavior data. Much of the recent work on large-scale semantic search using deep learning focuses on ranking for web search. In contrast, semantic matching for product search presents several novel challenges, which we elucidate in this paper. We address these challenges by a) developing a new loss function that has an inbuilt threshold to differentiate between random negative examples, impressed but not purchased examples, and positive examples (purchased items), b) using average pooling in conjunction with n-grams to capture short-range linguistic patterns, c) using hashing to handle out of vocabulary tokens, and d) using a model parallel training architecture to scale across 8 GPUs. We present compelling offline results that demonstrate at least 4.7% improvement in Recall@100 and 14.5% improvement in mean average precision (MAP) over baseline state-of-the-art semantic search methods using the same tokenization method. Moreover, we present results and discuss learnings from online A/B tests which demonstrate the efficacy of our method.