 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSETrLUSI: Stochastic Ensemble Multi-Source Transfer Learning Using Statistical Invariant
Sep 19, 2025In transfer learning, a source domain often carries diverse knowledge, and different domains usually emphasize different types of knowledge. Different from handling only a single type of knowledge from all domains in traditional transfer learning methods, we introduce an ensemble learning framework with a weak mode of convergence in the form of Statistical Invariant (SI) for multi-source transfer learning, formulated as Stochastic Ensemble Multi-Source Transfer Learning Using Statistical Invariant (SETrLUSI). The proposed SI extracts and integrates various types of knowledge from both source and target domains, which not only effectively utilizes diverse knowledge but also accelerates the convergence process. Further, SETrLUSI incorporates stochastic SI selection, proportional source domain sampling, and target domain bootstrapping, which improves training efficiency while enhancing model stability. Experiments show that SETrLUSI has good convergence and outperforms related methods with a lower time cost.
QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction
Sep 05, 2021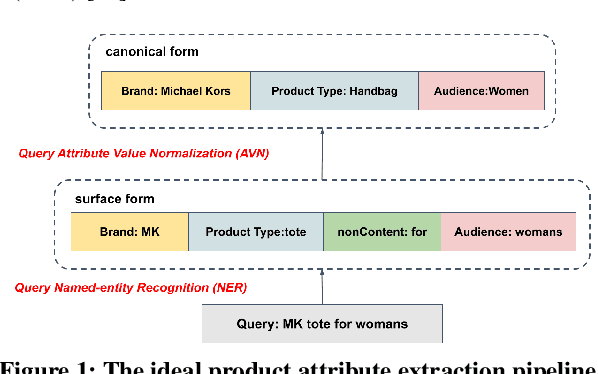

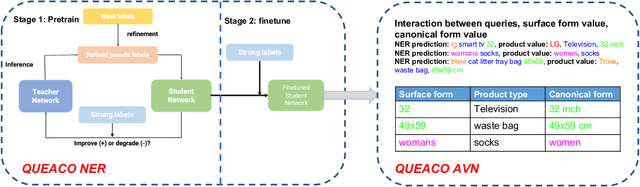
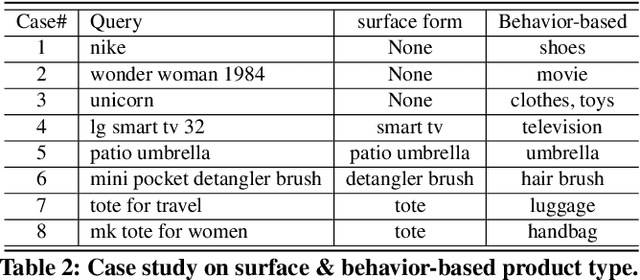
We study the problem of query attribute value extraction, which aims to identify named entities from user queries as diverse surface form attribute values and afterward transform them into formally canonical forms. Such a problem consists of two phases: {named entity recognition (NER)} and {attribute value normalization (AVN)}. However, existing works only focus on the NER phase but neglect equally important AVN. To bridge this gap, this paper proposes a unified query attribute value extraction system in e-commerce search named QUEACO, which involves both two phases. Moreover, by leveraging large-scale weakly-labeled behavior data, we further improve the extraction performance with less supervision cost. Specifically, for the NER phase, QUEACO adopts a novel teacher-student network, where a teacher network that is trained on the strongly-labeled data generates pseudo-labels to refine the weakly-labeled data for training a student network. Meanwhile, the teacher network can be dynamically adapted by the feedback of the student's performance on strongly-labeled data to maximally denoise the noisy supervisions from the weak labels. For the AVN phase, we also leverage the weakly-labeled query-to-attribute behavior data to normalize surface form attribute values from queries into canonical forms from products. Extensive experiments on a real-world large-scale E-commerce dataset demonstrate the effectiveness of QUEACO.
* The 30th ACM International Conference on Information and Knowledge Management (CIKM 2021, Applied Research Track)
Graph-based Multilingual Product Retrieval in E-commerce Search
May 06, 2021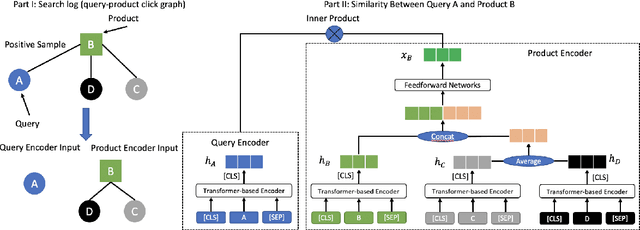

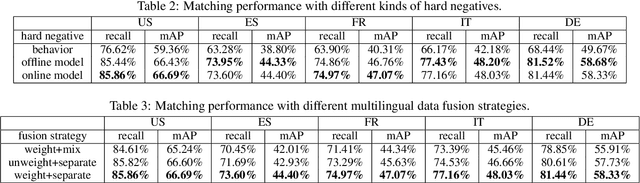
Nowadays, with many e-commerce platforms conducting global business, e-commerce search systems are required to handle product retrieval under multilingual scenarios. Moreover, comparing with maintaining per-country specific e-commerce search systems, having a universal system across countries can further reduce the operational and computational costs, and facilitate business expansion to new countries. In this paper, we introduce a universal end-to-end multilingual retrieval system, and discuss our learnings and technical details when training and deploying the system to serve billion-scale product retrieval for e-commerce search. In particular, we propose a multilingual graph attention based retrieval network by leveraging recent advances in transformer-based multilingual language models and graph neural network architectures to capture the interactions between search queries and items in e-commerce search. Offline experiments on five countries data show that our algorithm outperforms the state-of-the-art baselines by 35% recall and 25% mAP on average. Moreover, the proposed model shows significant increase of conversion/revenue in online A/B experiments and has been deployed in production for multiple countries.
Semantic Product Search
Jul 01, 2019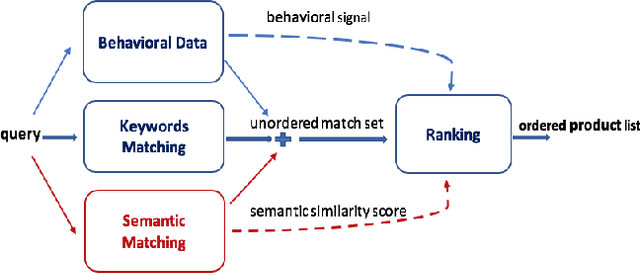
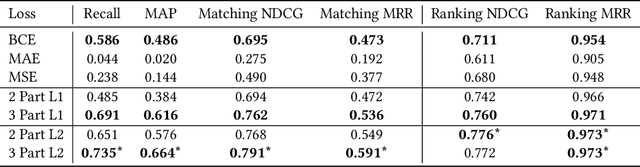
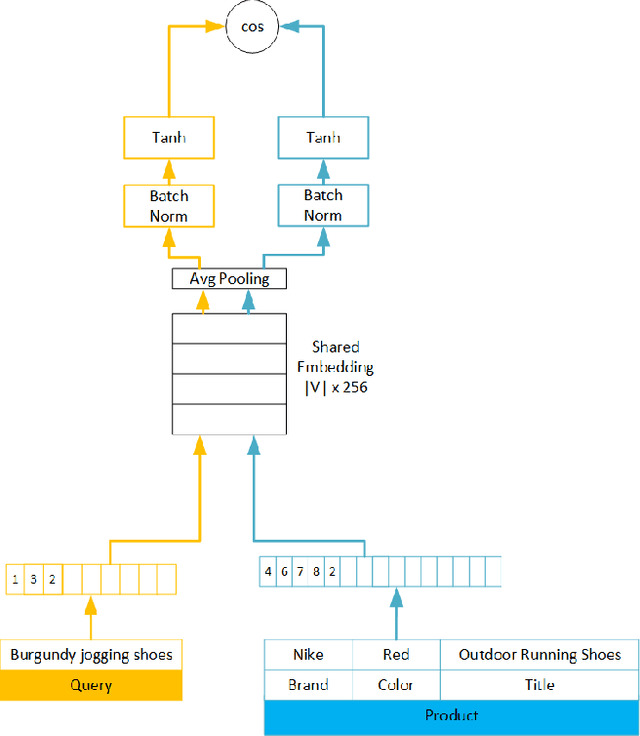
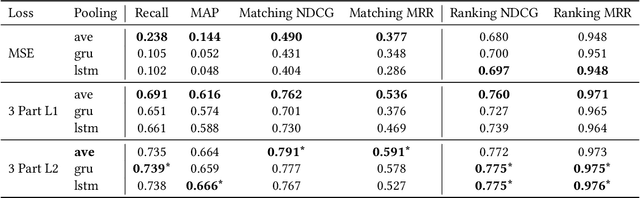
We study the problem of semantic matching in product search, that is, given a customer query, retrieve all semantically related products from the catalog. Pure lexical matching via an inverted index falls short in this respect due to several factors: a) lack of understanding of hypernyms, synonyms, and antonyms, b) fragility to morphological variants (e.g. "woman" vs. "women"), and c) sensitivity to spelling errors. To address these issues, we train a deep learning model for semantic matching using customer behavior data. Much of the recent work on large-scale semantic search using deep learning focuses on ranking for web search. In contrast, semantic matching for product search presents several novel challenges, which we elucidate in this paper. We address these challenges by a) developing a new loss function that has an inbuilt threshold to differentiate between random negative examples, impressed but not purchased examples, and positive examples (purchased items), b) using average pooling in conjunction with n-grams to capture short-range linguistic patterns, c) using hashing to handle out of vocabulary tokens, and d) using a model parallel training architecture to scale across 8 GPUs. We present compelling offline results that demonstrate at least 4.7% improvement in Recall@100 and 14.5% improvement in mean average precision (MAP) over baseline state-of-the-art semantic search methods using the same tokenization method. Moreover, we present results and discuss learnings from online A/B tests which demonstrate the efficacy of our method.