 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteAttention: A Temporal Sparse Attention for Diffusion Transformers
Nov 14, 2025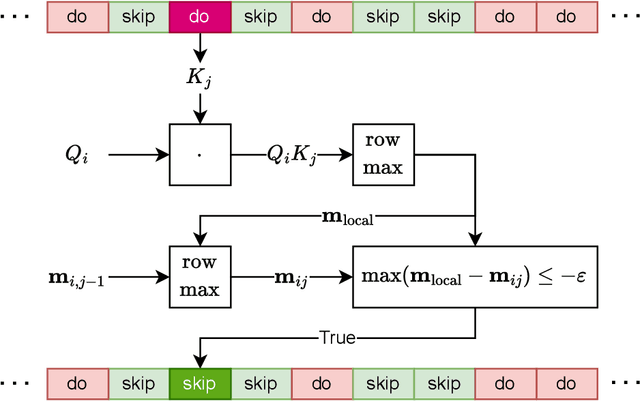



Diffusion Transformers, particularly for video generation, achieve remarkable quality but suffer from quadratic attention complexity, leading to prohibitive latency. Existing acceleration methods face a fundamental trade-off: dynamically estimating sparse attention patterns at each denoising step incurs high computational overhead and estimation errors, while static sparsity patterns remain fixed and often suboptimal throughout denoising. We identify a key structural property of diffusion attention, namely, its sparsity patterns exhibit strong temporal coherence across denoising steps. Tiles deemed non-essential at step $t$ typically remain so at step $t+δ$. Leveraging this observation, we introduce LiteAttention, a method that exploits temporal coherence to enable evolutionary computation skips across the denoising sequence. By marking non-essential tiles early and propagating skip decisions forward, LiteAttention eliminates redundant attention computations without repeated profiling overheads, combining the adaptivity of dynamic methods with the efficiency of static ones. We implement a highly optimized LiteAttention kernel on top of FlashAttention and demonstrate substantial speedups on production video diffusion models, with no degradation in quality. The code and implementation details will be publicly released.
Quantifying and Modeling Driving Styles in Trajectory Forecasting
Mar 06, 2025



Trajectory forecasting has become a popular deep learning task due to its relevance for scenario simulation for autonomous driving. Specifically, trajectory forecasting predicts the trajectory of a short-horizon future for specific human drivers in a particular traffic scenario. Robust and accurate future predictions can enable autonomous driving planners to optimize for low-risk and predictable outcomes for human drivers around them. Although some work has been done to model driving style in planning and personalized autonomous polices, a gap exists in explicitly modeling human driving styles for trajectory forecasting of human behavior. Human driving style is most certainly a correlating factor to decision making, especially in edge-case scenarios where risk is nontrivial, as justified by the large amount of traffic psychology literature on risky driving. So far, the current real-world datasets for trajectory forecasting lack insight on the variety of represented driving styles. While the datasets may represent real-world distributions of driving styles, we posit that fringe driving style types may also be correlated with edge-case safety scenarios. In this work, we conduct analyses on existing real-world trajectory datasets for driving and dissect these works from the lens of driving styles, which is often intangible and non-standardized.
ColPali: Efficient Document Retrieval with Vision Language Models
Jul 02, 2024Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, or fonts. While modern document retrieval systems exhibit strong performance on query-to-text matching, they struggle to exploit visual cues efficiently, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation. To benchmark current systems on visually rich document retrieval, we introduce the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings. The inherent shortcomings of modern systems motivate the introduction of a new retrieval model architecture, ColPali, which leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages. Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.
Sensitivity-Informed Augmentation for Robust Segmentation
Jun 04, 2024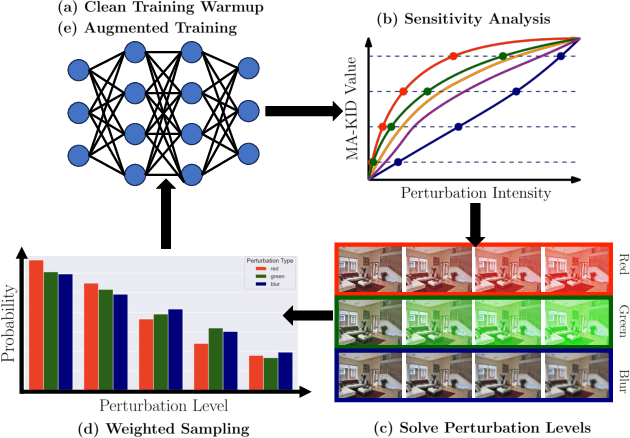
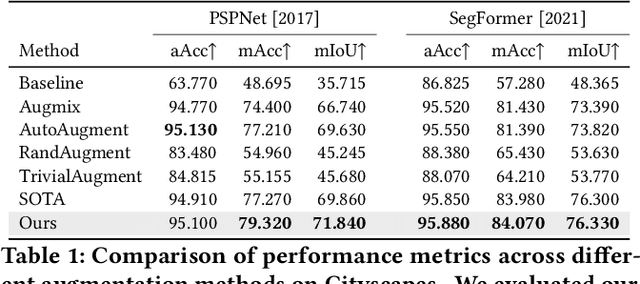
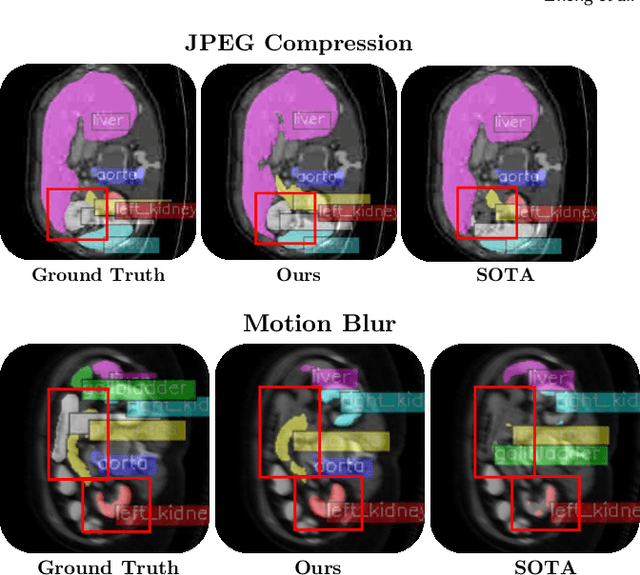
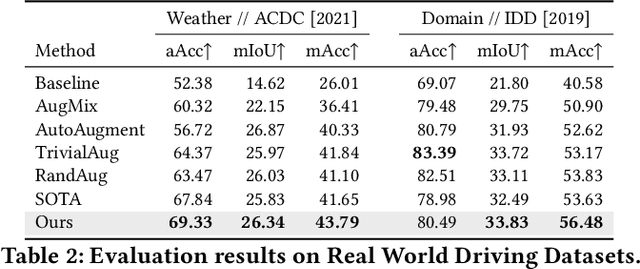
Segmentation is an integral module in many visual computing applications such as virtual try-on, medical imaging, autonomous driving, and agricultural automation. These applications often involve either widespread consumer use or highly variable environments, both of which can degrade the quality of visual sensor data, whether from a common mobile phone or an expensive satellite imaging camera. In addition to external noises like user difference or weather conditions, internal noises such as variations in camera quality or lens distortion can affect the performance of segmentation models during both development and deployment. In this work, we present an efficient, adaptable, and gradient-free method to enhance the robustness of learning-based segmentation models across training. First, we introduce a novel adaptive sensitivity analysis (ASA) using Kernel Inception Distance (KID) on basis perturbations to benchmark perturbation sensitivity of pre-trained segmentation models. Then, we model the sensitivity curve using the adaptive SA and sample perturbation hyperparameter values accordingly. Finally, we conduct adversarial training with the selected perturbation values and dynamically re-evaluate robustness during online training. Our method, implemented end-to-end with minimal fine-tuning required, consistently outperforms state-of-the-art data augmentation techniques for segmentation. It shows significant improvement in both clean data evaluation and real-world adverse scenario evaluation across various segmentation datasets used in visual computing and computer graphics applications.
Learning Interpretable Representations of Entanglement in Quantum Optics Experiments using Deep Generative Models
Sep 06, 2021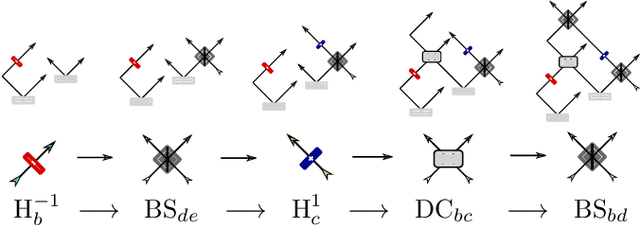
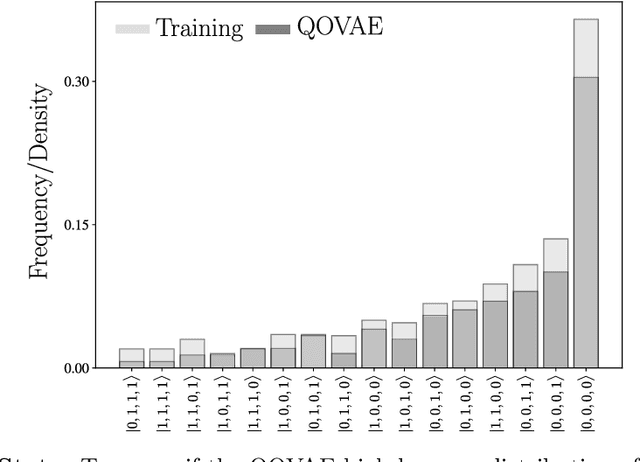
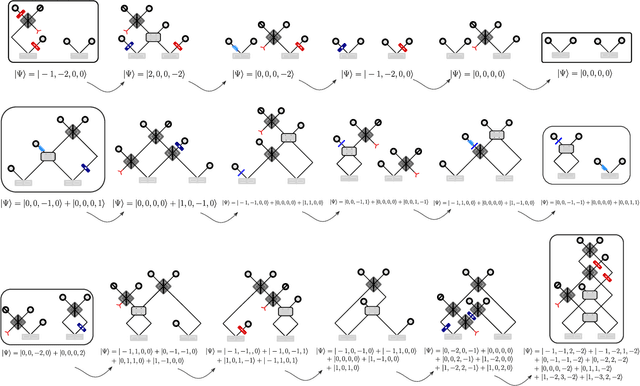
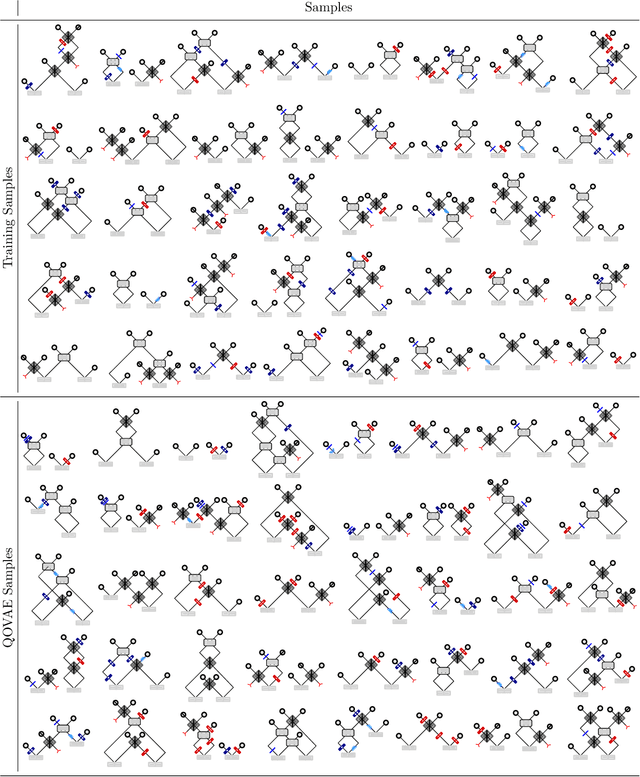
Quantum physics experiments produce interesting phenomena such as interference or entanglement, which is a core property of numerous future quantum technologies. The complex relationship between a quantum experiment's structure and its entanglement properties is essential to fundamental research in quantum optics but is difficult to intuitively understand. We present the first deep generative model of quantum optics experiments where a variational autoencoder (QOVAE) is trained on a dataset of experimental setups. In a series of computational experiments, we investigate the learned representation of the QOVAE and its internal understanding of the quantum optics world. We demonstrate that the QOVAE learns an intrepretable representation of quantum optics experiments and the relationship between experiment structure and entanglement. We show the QOVAE is able to generate novel experiments for highly entangled quantum states with specific distributions that match its training data. Importantly, we are able to fully interpret how the QOVAE structures its latent space, finding curious patterns that we can entirely explain in terms of quantum physics. The results demonstrate how we can successfully use and understand the internal representations of deep generative models in a complex scientific domain. The QOVAE and the insights from our investigations can be immediately applied to other physical systems throughout fundamental scientific research.
QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction
Sep 05, 2021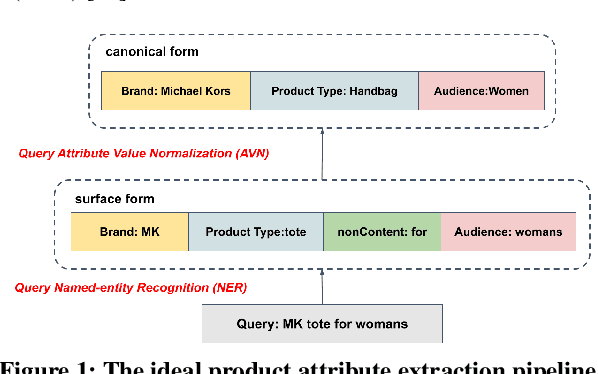

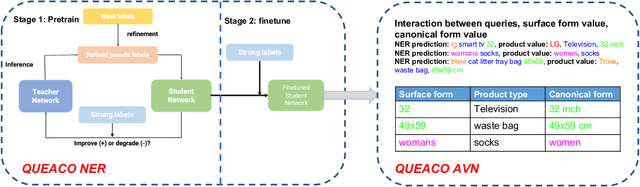
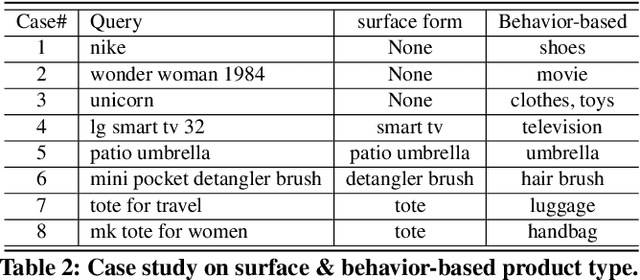
We study the problem of query attribute value extraction, which aims to identify named entities from user queries as diverse surface form attribute values and afterward transform them into formally canonical forms. Such a problem consists of two phases: {named entity recognition (NER)} and {attribute value normalization (AVN)}. However, existing works only focus on the NER phase but neglect equally important AVN. To bridge this gap, this paper proposes a unified query attribute value extraction system in e-commerce search named QUEACO, which involves both two phases. Moreover, by leveraging large-scale weakly-labeled behavior data, we further improve the extraction performance with less supervision cost. Specifically, for the NER phase, QUEACO adopts a novel teacher-student network, where a teacher network that is trained on the strongly-labeled data generates pseudo-labels to refine the weakly-labeled data for training a student network. Meanwhile, the teacher network can be dynamically adapted by the feedback of the student's performance on strongly-labeled data to maximally denoise the noisy supervisions from the weak labels. For the AVN phase, we also leverage the weakly-labeled query-to-attribute behavior data to normalize surface form attribute values from queries into canonical forms from products. Extensive experiments on a real-world large-scale E-commerce dataset demonstrate the effectiveness of QUEACO.
* The 30th ACM International Conference on Information and Knowledge Management (CIKM 2021, Applied Research Track)
Graph-based Multilingual Product Retrieval in E-commerce Search
May 06, 2021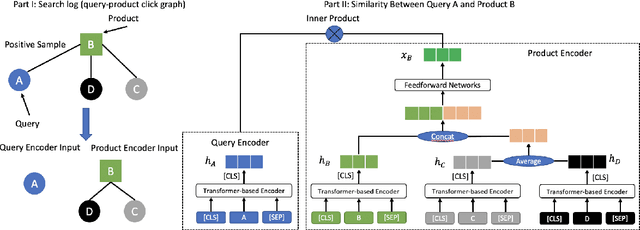

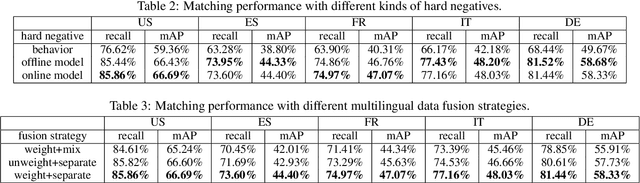
Nowadays, with many e-commerce platforms conducting global business, e-commerce search systems are required to handle product retrieval under multilingual scenarios. Moreover, comparing with maintaining per-country specific e-commerce search systems, having a universal system across countries can further reduce the operational and computational costs, and facilitate business expansion to new countries. In this paper, we introduce a universal end-to-end multilingual retrieval system, and discuss our learnings and technical details when training and deploying the system to serve billion-scale product retrieval for e-commerce search. In particular, we propose a multilingual graph attention based retrieval network by leveraging recent advances in transformer-based multilingual language models and graph neural network architectures to capture the interactions between search queries and items in e-commerce search. Offline experiments on five countries data show that our algorithm outperforms the state-of-the-art baselines by 35% recall and 25% mAP on average. Moreover, the proposed model shows significant increase of conversion/revenue in online A/B experiments and has been deployed in production for multiple countries.
Neural Message Passing on High Order Paths
Feb 24, 2020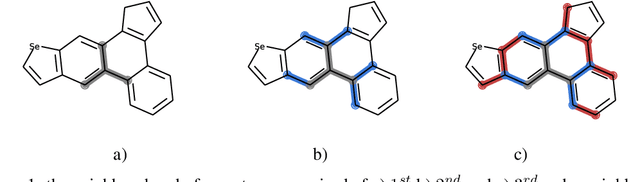

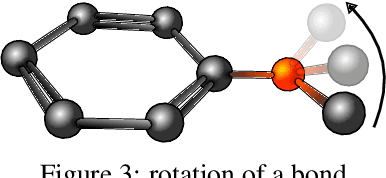
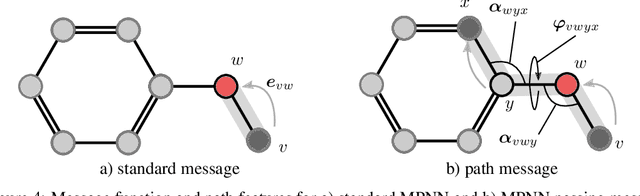
Graph neural network have achieved impressive results in predicting molecular properties, but they do not directly account for local and hidden structures in the graph such as functional groups and molecular geometry. At each propagation step, GNNs aggregate only over first order neighbours, ignoring important information contained in subsequent neighbours as well as the relationships between those higher order connections. In this work, we generalize graph neural nets to pass messages and aggregate across higher order paths. This allows for information to propagate over various levels and substructures of the graph. We demonstrate our model on a few tasks in molecular property prediction.
Graph Deconvolutional Generation
Feb 14, 2020
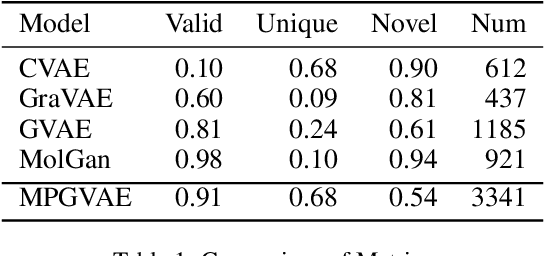
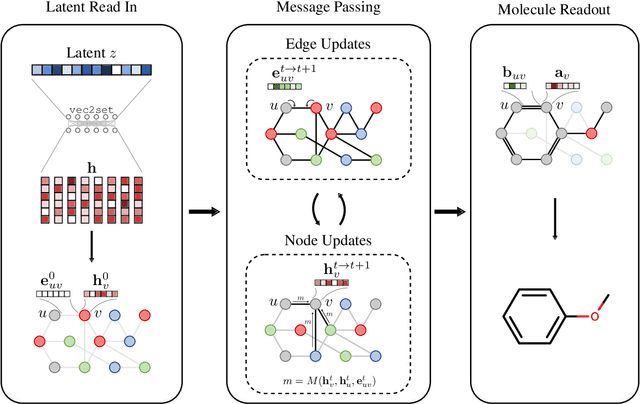
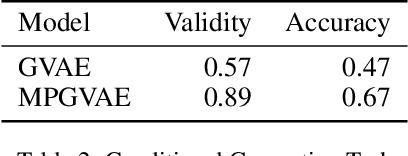
Graph generation is an extremely important task, as graphs are found throughout different areas of science and engineering. In this work, we focus on the modern equivalent of the Erdos-Renyi random graph model: the graph variational autoencoder (GVAE). This model assumes edges and nodes are independent in order to generate entire graphs at a time using a multi-layer perceptron decoder. As a result of these assumptions, GVAE has difficulty matching the training distribution and relies on an expensive graph matching procedure. We improve this class of models by building a message passing neural network into GVAE's encoder and decoder. We demonstrate our model on the specific task of generating small organic molecules